 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Grep All You Need? How Agent Harnesses Reshape Agentic Search
May 14, 2026Recent advances in Large Language Model (LLM) agents have enabled complex agentic workflows where models autonomously retrieve information, call tools, and reason over large corpora to complete tasks on behalf of users. Despite the growing adoption of retrieval-augmented generation (RAG) in agentic search systems, existing literature lacks a systematic comparison of how retrieval strategy choice interacts with agent architecture and tool-calling paradigm. Important practical dimensions, including how tool outputs are presented to the model and how performance changes when searches must cope with more irrelevant surrounding text, remain under-explored in agent loops. This paper reports an empirical study organized into two experiments. Experiment 1 compares grep and vector retrieval on a 116-question sample from LongMemEval, using a custom agent harness (Chronos) and provider-native CLI harnesses (Claude Code, Codex, and Gemini CLI), for both inline tool results and file-based tool results that the model reads separately. Experiment 2 compares grep-only and vector-only retrieval while progressively mixing in additional unrelated conversation history, so that each query is embedded in more distracting material alongside the passages that matter. Across Chronos and the provider CLIs, grep generally yields higher accuracy than vector retrieval in our comparisons in experiment 1; at the same time, overall scores still depend strongly on which harness and tool-calling style is used, even when the underlying conversation data are the same.
Agentic Jackal: Live Execution and Semantic Value Grounding for Text-to-JQL
Apr 10, 2026Translating natural language into Jira Query Language (JQL) requires resolving ambiguous field references, instance-specific categorical values, and complex Boolean predicates. Single-pass LLMs cannot discover which categorical values (e.g., component names or fix versions) actually exist in a given Jira instance, nor can they verify generated queries against a live data source, limiting accuracy on paraphrased or ambiguous requests. No open, execution-based benchmark exists for mapping natural language to JQL. We introduce Jackal, the first large-scale, execution-based text-to-JQL benchmark comprising 100,000 validated NL-JQL pairs on a live Jira instance with over 200,000 issues. To establish baselines on Jackal, we propose Agentic Jackal, a tool-augmented agent that equips LLMs with live query execution via the Jira MCP server and JiraAnchor, a semantic retrieval tool that resolves natural-language mentions of categorical values through embedding-based similarity search. Among 9 frontier LLMs evaluated, single-pass models average only 43.4% execution accuracy on short natural-language queries, highlighting that text-to-JQL remains an open challenge. The agentic approach improves 7 of 9 models, with a 9.0% relative gain on the most linguistically challenging variant; in a controlled ablation isolating JiraAnchor, categorical-value accuracy rises from 48.7% to 71.7%, with component-field accuracy jumping from 16.9% to 66.2%. Our analysis identifies inherent semantic ambiguities, such as issue-type disambiguation and text-field selection, as the dominant failure modes rather than value-resolution errors, pointing to concrete directions for future work. We publicly release the benchmark, all agent transcripts, and evaluation code to support reproducibility.
Chronos: Temporal-Aware Conversational Agents with Structured Event Retrieval for Long-Term Memory
Mar 17, 2026Recent advances in Large Language Models (LLMs) have enabled conversational AI agents to engage in extended multi-turn interactions spanning weeks or months. However, existing memory systems struggle to reason over temporally grounded facts and preferences that evolve across months of interaction and lack effective retrieval strategies for multi-hop, time-sensitive queries over long dialogue histories. We introduce Chronos, a novel temporal-aware memory framework that decomposes raw dialogue into subject-verb-object event tuples with resolved datetime ranges and entity aliases, indexing them in a structured event calendar alongside a turn calendar that preserves full conversational context. At query time, Chronos applies dynamic prompting to generate tailored retrieval guidance for each question, directing the agent on what to retrieve, how to filter across time ranges, and how to approach multi-hop reasoning through an iterative tool-calling loop over both calendars. We evaluate Chronos with 8 LLMs, both open-source and closed-source, on the LongMemEvalS benchmark comprising 500 questions spanning six categories of dialogue history tasks. Chronos Low achieves 92.60% and Chronos High scores 95.60% accuracy, setting a new state of the art with an improvement of 7.67% over the best prior system. Ablation results reveal the events calendar accounts for a 58.9% gain on the baseline while all other components yield improvements between 15.5% and 22.3%. Notably, Chronos Low alone surpasses prior approaches evaluated under their strongest model configurations.
From Rows to Reasoning: A Retrieval-Augmented Multimodal Framework for Spreadsheet Understanding
Jan 13, 2026Large Language Models (LLMs) struggle to reason over large-scale enterprise spreadsheets containing thousands of numeric rows, multiple linked sheets, and embedded visual content such as charts and receipts. Prior state-of-the-art spreadsheet reasoning approaches typically rely on single-sheet compression or full-context encoding, which limits scalability and fails to reflect how real users interact with complex, multimodal workbooks. We introduce FRTR-Bench, the first large-scale benchmark for multimodal spreadsheet reasoning, comprising 30 enterprise-grade Excel workbooks spanning nearly four million cells and more than 50 embedded images. To address these challenges, we present From Rows to Reasoning (FRTR), an advanced, multimodal retrieval-augmented generation framework that decomposes Excel workbooks into granular row, column, and block embeddings, employs hybrid lexical-dense retrieval with Reciprocal Rank Fusion (RRF), and integrates multimodal embeddings to reason over both numerical and visual information. We tested FRTR on six LLMs, achieving 74% answer accuracy on FRTR-Bench with Claude Sonnet 4.5, a substantial improvement over prior state-of-the-art approaches that reached only 24%. On the SpreadsheetLLM benchmark, FRTR achieved 87% accuracy with GPT-5 while reducing token usage by roughly 50% compared to context-compression methods.
Don't Break the Cache: An Evaluation of Prompt Caching for Long-Horizon Agentic Tasks
Jan 09, 2026Recent advancements in Large Language Model (LLM) agents have enabled complex multi-turn agentic tasks requiring extensive tool calling, where conversations can span dozens of API calls with increasingly large context windows. However, although major LLM providers offer prompt caching to reduce cost and latency, its benefits for agentic workloads remain underexplored in the research literature. To our knowledge, no prior work quantifies these cost savings or compares caching strategies for multi-turn agentic tasks. We present a comprehensive evaluation of prompt caching across three major LLM providers (OpenAI, Anthropic, and Google) and compare three caching strategies, including full context caching, system prompt only caching, and caching that excludes dynamic tool results. We evaluate on DeepResearchBench, a multi-turn agentic benchmark where agents autonomously execute real-world web search tool calls to answer complex research questions, measuring both API cost and time to first token (TTFT) across over 500 agent sessions with 10,000-token system prompts. Our results demonstrate that prompt caching reduces API costs by 45-80% and improves time to first token by 13-31% across providers. We find that strategic prompt cache block control, such as placing dynamic content at the end of the system prompt, avoiding dynamic traditional function calling, and excluding dynamic tool results, provides more consistent benefits than naive full-context caching, which can paradoxically increase latency. Our analysis reveals nuanced variations in caching behavior across providers, and we provide practical guidance for implementing prompt caching in production agentic systems.
ScaleMCP: Dynamic and Auto-Synchronizing Model Context Protocol Tools for LLM Agents
May 09, 2025



Recent advancements in Large Language Models (LLMs) and the introduction of the Model Context Protocol (MCP) have significantly expanded LLM agents' capability to interact dynamically with external tools and APIs. However, existing tool selection frameworks do not integrate MCP servers, instead relying heavily on error-prone manual updates to monolithic local tool repositories, leading to duplication, inconsistencies, and inefficiencies. Additionally, current approaches abstract tool selection before the LLM agent is invoked, limiting its autonomy and hindering dynamic re-querying capabilities during multi-turn interactions. To address these issues, we introduce ScaleMCP, a novel tool selection approach that dynamically equips LLM agents with a MCP tool retriever, giving agents the autonomy to add tools into their memory, as well as an auto-synchronizing tool storage system pipeline through CRUD (create, read, update, delete) operations with MCP servers as the single source of truth. We also propose a novel embedding strategy, Tool Document Weighted Average (TDWA), designed to selectively emphasize critical components of tool documents (e.g. tool name or synthetic questions) during the embedding process. Comprehensive evaluations conducted on a created dataset of 5,000 financial metric MCP servers, across 10 LLM models, 5 embedding models, and 5 retriever types, demonstrate substantial improvements in tool retrieval and agent invocation performance, emphasizing ScaleMCP's effectiveness in scalable, dynamic tool selection and invocation.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Practical Conformer: Optimizing size, speed and flops of Conformer for on-Device and cloud ASR
Mar 31, 2023

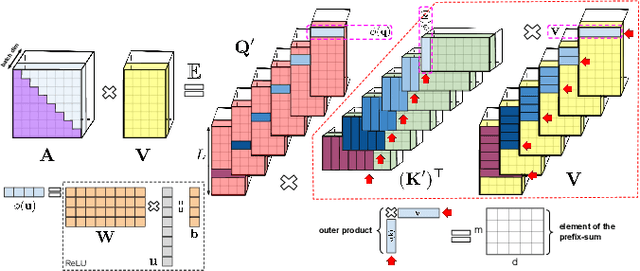

Conformer models maintain a large number of internal states, the vast majority of which are associated with self-attention layers. With limited memory bandwidth, reading these from memory at each inference step can slow down inference. In this paper, we design an optimized conformer that is small enough to meet on-device restrictions and has fast inference on TPUs. We explore various ideas to improve the execution speed, including replacing lower conformer blocks with convolution-only blocks, strategically downsizing the architecture, and utilizing an RNNAttention-Performer. Our optimized conformer can be readily incorporated into a cascaded-encoder setting, allowing a second-pass decoder to operate on its output and improve the accuracy whenever more resources are available. Altogether, we find that these optimizations can reduce latency by a factor of 6.8x, and come at a reasonable trade-off in quality. With the cascaded second-pass, we show that the recognition accuracy is completely recoverable. Thus, our proposed encoder can double as a strong standalone encoder in on device, and as the first part of a high-performance ASR pipeline.
SLAM: A Unified Encoder for Speech and Language Modeling via Speech-Text Joint Pre-Training
Oct 20, 2021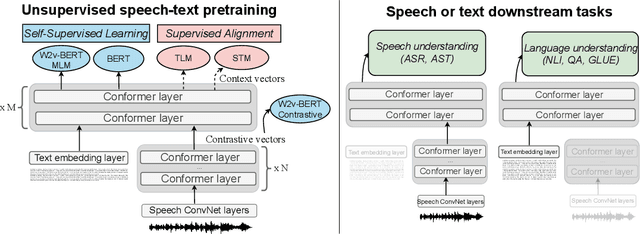
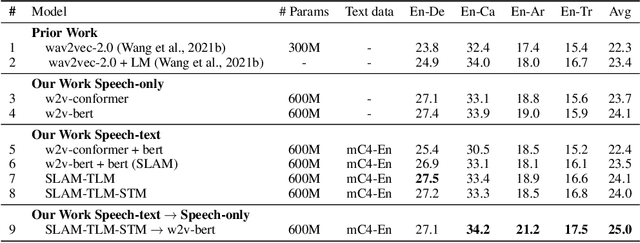
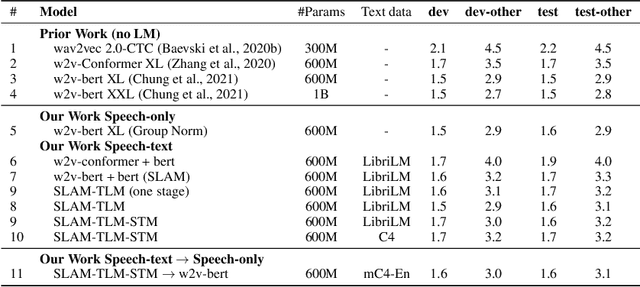
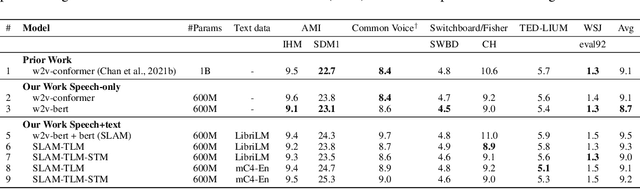
Unsupervised pre-training is now the predominant approach for both text and speech understanding. Self-attention models pre-trained on large amounts of unannotated data have been hugely successful when fine-tuned on downstream tasks from a variety of domains and languages. This paper takes the universality of unsupervised language pre-training one step further, by unifying speech and text pre-training within a single model. We build a single encoder with the BERT objective on unlabeled text together with the w2v-BERT objective on unlabeled speech. To further align our model representations across modalities, we leverage alignment losses, specifically Translation Language Modeling (TLM) and Speech Text Matching (STM) that make use of supervised speech-text recognition data. We demonstrate that incorporating both speech and text data during pre-training can significantly improve downstream quality on CoVoST~2 speech translation, by around 1 BLEU compared to single-modality pre-trained models, while retaining close to SotA performance on LibriSpeech and SpeechStew ASR tasks. On four GLUE tasks and text-normalization, we observe evidence of capacity limitations and interference between the two modalities, leading to degraded performance compared to an equivalent text-only model, while still being competitive with BERT. Through extensive empirical analysis we also demonstrate the importance of the choice of objective function for speech pre-training, and the beneficial effect of adding additional supervised signals on the quality of the learned representations.