 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling End-to-End Models for Large-Scale Multilingual ASR
Paper and Code
Apr 30, 2021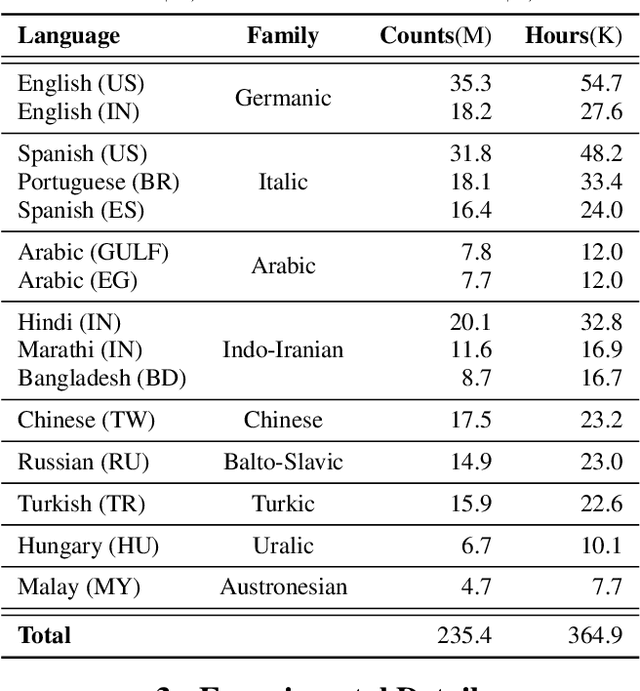
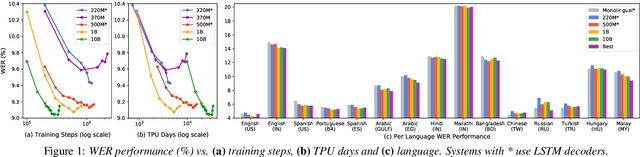

Building ASR models across many language families is a challenging multi-task learning problem due to large language variations and heavily unbalanced data. Existing work has shown positive transfer from high resource to low resource languages. However, degradations on high resource languages are commonly observed due to interference from the heterogeneous multilingual data and reduction in per-language capacity. We conduct a capacity study on a 15-language task, with the amount of data per language varying from 7.7K to 54.7K hours. We adopt GShard [1] to efficiently scale up to 10B parameters. Empirically, we find that (1) scaling the number of model parameters is an effective way to solve the capacity bottleneck - our 500M-param model is already better than monolingual baselines and scaling it to 1B and 10B brought further quality gains; (2) larger models are not only more data efficient, but also more efficient in terms of training cost as measured in TPU days - the 1B-param model reaches the same accuracy at 34% of training time as the 500M-param model; (3) given a fixed capacity budget, adding depth usually works better than width and large encoders tend to do better than large decoders.