 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual-Evasive Attacks on ADMM in Distributed Optimization
Apr 22, 2025This paper presents two attack strategies designed to evade detection in ADMM-based systems by preventing significant changes to the residual during the attacked iteration. While many detection algorithms focus on identifying false data injection through residual changes, we show that our attacks remain undetected by keeping the residual largely unchanged. The first strategy uses a random starting point combined with Gram-Schmidt orthogonalization to ensure stealth, with potential for refinement by enhancing the orthogonal component to increase system disruption. The second strategy builds on the first, targeting financial gains by manipulating reactive power and pushing the system to its upper voltage limit, exploiting operational constraints. The effectiveness of the proposed attack-resilient mechanism is demonstrated through case studies on the IEEE 14-bus system. A comparison of the two strategies, along with commonly used naive attacks, reveals trade-offs between simplicity, detectability, and effectiveness, providing insights into ADMM system vulnerabilities. These findings underscore the need for more robust monitoring algorithms to protect against advanced attack strategies.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Multilingual and Fully Non-Autoregressive ASR with Large Language Model Fusion: A Comprehensive Study
Jan 23, 2024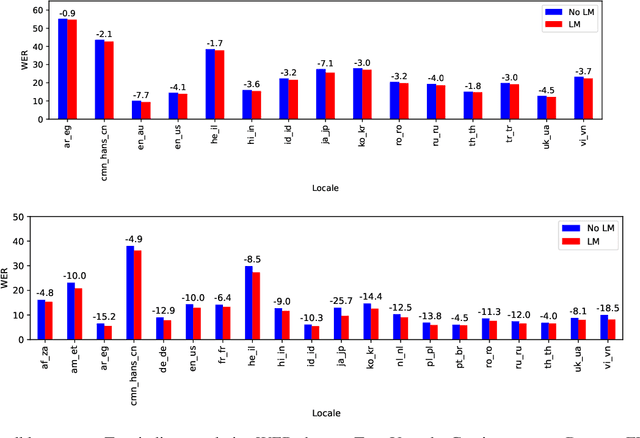
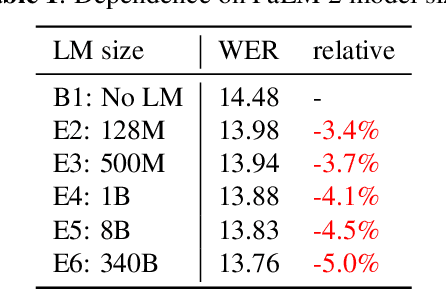
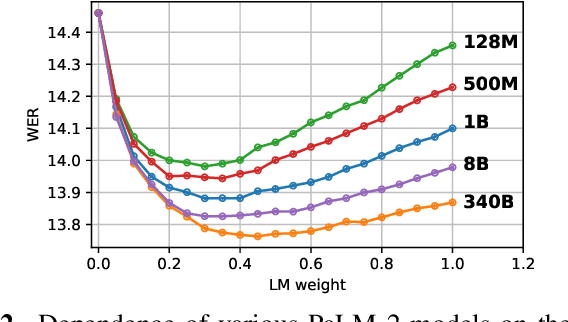
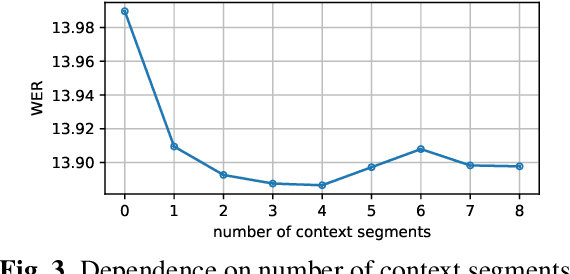
In the era of large models, the autoregressive nature of decoding often results in latency serving as a significant bottleneck. We propose a non-autoregressive LM-fused ASR system that effectively leverages the parallelization capabilities of accelerator hardware. Our approach combines the Universal Speech Model (USM) and the PaLM 2 language model in per-segment scoring mode, achieving an average relative WER improvement across all languages of 10.8% on FLEURS and 3.6% on YouTube captioning. Furthermore, our comprehensive ablation study analyzes key parameters such as LLM size, context length, vocabulary size, fusion methodology. For instance, we explore the impact of LLM size ranging from 128M to 340B parameters on ASR performance. This study provides valuable insights into the factors influencing the effectiveness of practical large-scale LM-fused speech recognition systems.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Massive End-to-end Models for Short Search Queries
Sep 22, 2023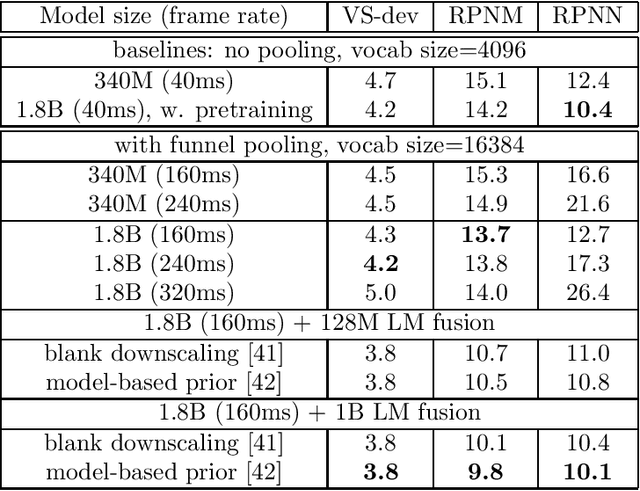
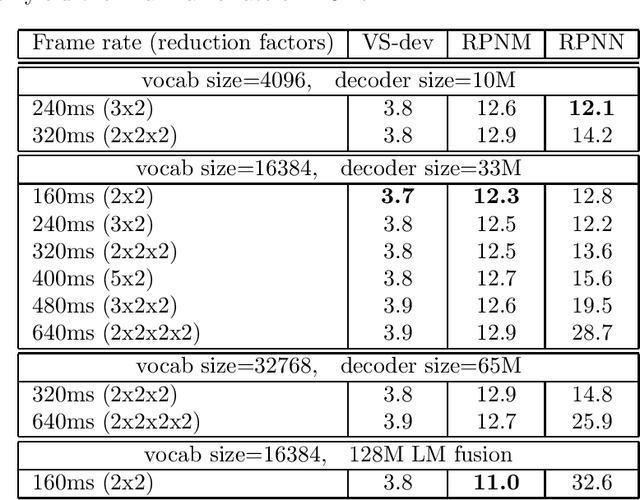
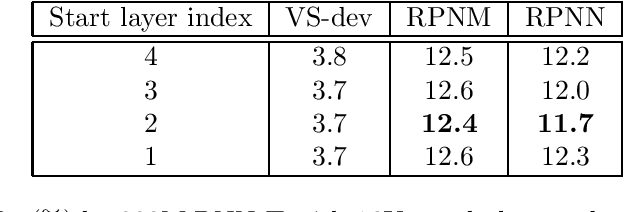
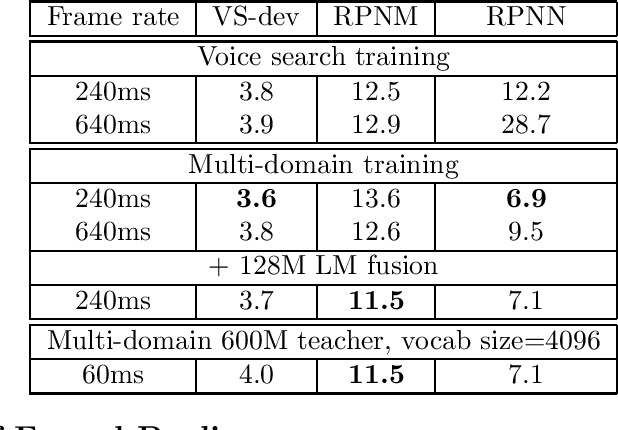
In this work, we investigate two popular end-to-end automatic speech recognition (ASR) models, namely Connectionist Temporal Classification (CTC) and RNN-Transducer (RNN-T), for offline recognition of voice search queries, with up to 2B model parameters. The encoders of our models use the neural architecture of Google's universal speech model (USM), with additional funnel pooling layers to significantly reduce the frame rate and speed up training and inference. We perform extensive studies on vocabulary size, time reduction strategy, and its generalization performance on long-form test sets. Despite the speculation that, as the model size increases, CTC can be as good as RNN-T which builds label dependency into the prediction, we observe that a 900M RNN-T clearly outperforms a 1.8B CTC and is more tolerant to severe time reduction, although the WER gap can be largely removed by LM shallow fusion.
AudioPaLM: A Large Language Model That Can Speak and Listen
Jun 22, 2023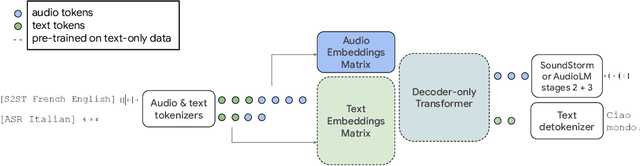



We introduce AudioPaLM, a large language model for speech understanding and generation. AudioPaLM fuses text-based and speech-based language models, PaLM-2 [Anil et al., 2023] and AudioLM [Borsos et al., 2022], into a unified multimodal architecture that can process and generate text and speech with applications including speech recognition and speech-to-speech translation. AudioPaLM inherits the capability to preserve paralinguistic information such as speaker identity and intonation from AudioLM and the linguistic knowledge present only in text large language models such as PaLM-2. We demonstrate that initializing AudioPaLM with the weights of a text-only large language model improves speech processing, successfully leveraging the larger quantity of text training data used in pretraining to assist with the speech tasks. The resulting model significantly outperforms existing systems for speech translation tasks and has the ability to perform zero-shot speech-to-text translation for many languages for which input/target language combinations were not seen in training. AudioPaLM also demonstrates features of audio language models, such as transferring a voice across languages based on a short spoken prompt. We release examples of our method at https://google-research.github.io/seanet/audiopalm/examples
Efficient Adapters for Giant Speech Models
Jun 13, 2023


Large pre-trained speech models are widely used as the de-facto paradigm, especially in scenarios when there is a limited amount of labeled data available. However, finetuning all parameters from the self-supervised learned model can be computationally expensive, and becomes infeasiable as the size of the model and the number of downstream tasks scales. In this paper, we propose a novel approach called Two Parallel Adapter (TPA) that is inserted into the conformer-based model pre-trained model instead. TPA is based on systematic studies of the residual adapter, a popular approach for finetuning a subset of parameters. We evaluate TPA on various public benchmarks and experiment results demonstrates its superior performance, which is close to the full finetuning on different datasets and speech tasks. These results show that TPA is an effective and efficient approach for serving large pre-trained speech models. Ablation studies show that TPA can also be pruned, especially for lower blocks.
Google USM: Scaling Automatic Speech Recognition Beyond 100 Languages
Mar 03, 2023
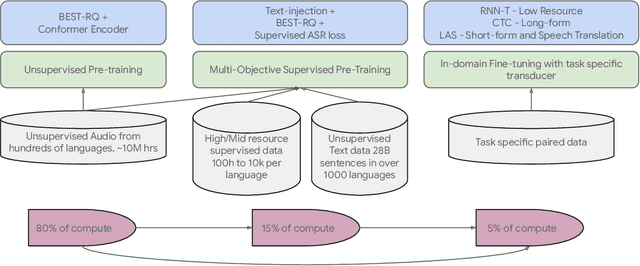
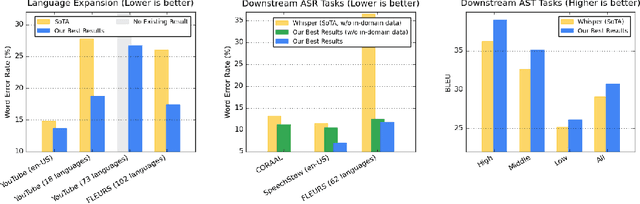

We introduce the Universal Speech Model (USM), a single large model that performs automatic speech recognition (ASR) across 100+ languages. This is achieved by pre-training the encoder of the model on a large unlabeled multilingual dataset of 12 million (M) hours spanning over 300 languages, and fine-tuning on a smaller labeled dataset. We use multilingual pre-training with random-projection quantization and speech-text modality matching to achieve state-of-the-art performance on downstream multilingual ASR and speech-to-text translation tasks. We also demonstrate that despite using a labeled training set 1/7-th the size of that used for the Whisper model, our model exhibits comparable or better performance on both in-domain and out-of-domain speech recognition tasks across many languages.
LaMDA: Language Models for Dialog Applications
Feb 10, 2022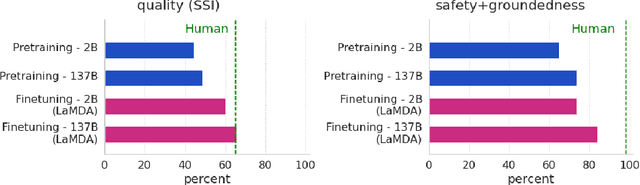
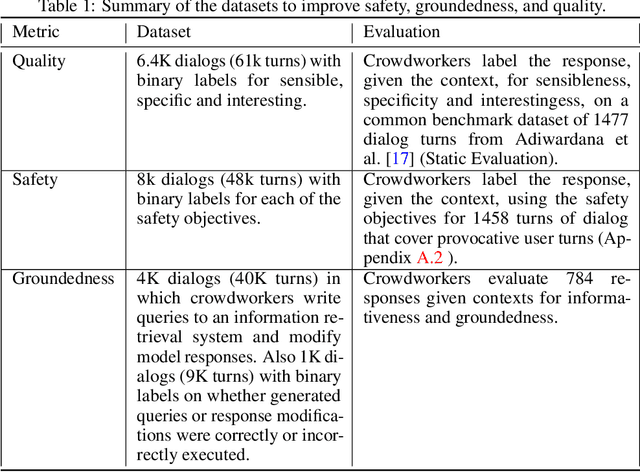

We present LaMDA: Language Models for Dialog Applications. LaMDA is a family of Transformer-based neural language models specialized for dialog, which have up to 137B parameters and are pre-trained on 1.56T words of public dialog data and web text. While model scaling alone can improve quality, it shows less improvements on safety and factual grounding. We demonstrate that fine-tuning with annotated data and enabling the model to consult external knowledge sources can lead to significant improvements towards the two key challenges of safety and factual grounding. The first challenge, safety, involves ensuring that the model's responses are consistent with a set of human values, such as preventing harmful suggestions and unfair bias. We quantify safety using a metric based on an illustrative set of human values, and we find that filtering candidate responses using a LaMDA classifier fine-tuned with a small amount of crowdworker-annotated data offers a promising approach to improving model safety. The second challenge, factual grounding, involves enabling the model to consult external knowledge sources, such as an information retrieval system, a language translator, and a calculator. We quantify factuality using a groundedness metric, and we find that our approach enables the model to generate responses grounded in known sources, rather than responses that merely sound plausible. Finally, we explore the use of LaMDA in the domains of education and content recommendations, and analyze their helpfulness and role consistency.
Self-supervised Learning with Random-projection Quantizer for Speech Recognition
Feb 03, 2022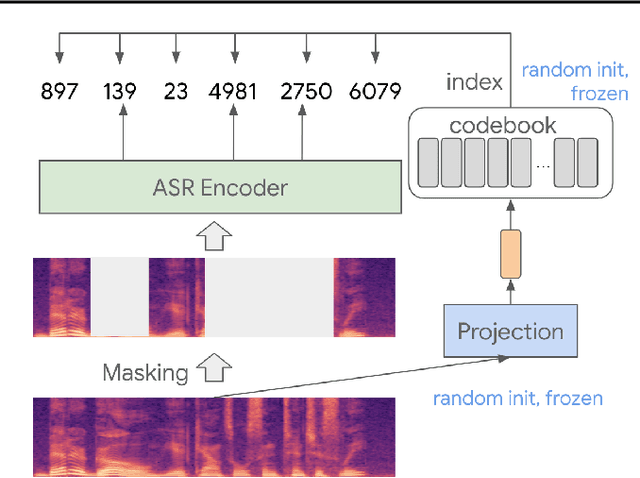

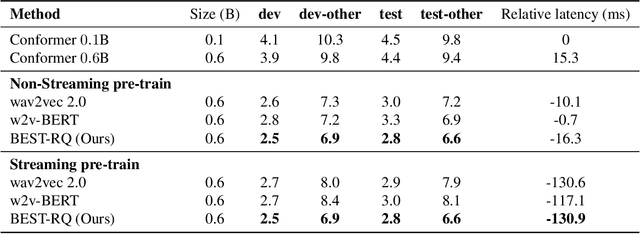
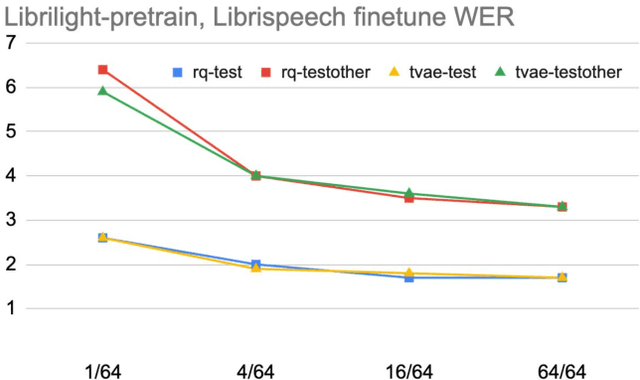
We present a simple and effective self-supervised learning approach for speech recognition. The approach learns a model to predict the masked speech signals, in the form of discrete labels generated with a random-projection quantizer. In particular the quantizer projects speech inputs with a randomly initialized matrix, and does a nearest-neighbor lookup in a randomly-initialized codebook. Neither the matrix nor the codebook is updated during self-supervised learning. Since the random-projection quantizer is not trained and is separated from the speech recognition model, the design makes the approach flexible and is compatible with universal speech recognition architecture. On LibriSpeech our approach achieves similar word-error-rates as previous work using self-supervised learning with non-streaming models, and provides lower word-error-rates and latency than wav2vec 2.0 and w2v-BERT with streaming models. On multilingual tasks the approach also provides significant improvement over wav2vec 2.0 and w2v-BERT.