 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligner-Encoders: Self-Attention Transformers Can Be Self-Transducers
Feb 06, 2025



Modern systems for automatic speech recognition, including the RNN-Transducer and Attention-based Encoder-Decoder (AED), are designed so that the encoder is not required to alter the time-position of information from the audio sequence into the embedding; alignment to the final text output is processed during decoding. We discover that the transformer-based encoder adopted in recent years is actually capable of performing the alignment internally during the forward pass, prior to decoding. This new phenomenon enables a simpler and more efficient model, the "Aligner-Encoder". To train it, we discard the dynamic programming of RNN-T in favor of the frame-wise cross-entropy loss of AED, while the decoder employs the lighter text-only recurrence of RNN-T without learned cross-attention -- it simply scans embedding frames in order from the beginning, producing one token each until predicting the end-of-message. We conduct experiments demonstrating performance remarkably close to the state of the art, including a special inference configuration enabling long-form recognition. In a representative comparison, we measure the total inference time for our model to be 2x faster than RNN-T and 16x faster than AED. Lastly, we find that the audio-text alignment is clearly visible in the self-attention weights of a certain layer, which could be said to perform "self-transduction".
Extreme Encoder Output Frame Rate Reduction: Improving Computational Latencies of Large End-to-End Models
Feb 27, 2024The accuracy of end-to-end (E2E) automatic speech recognition (ASR) models continues to improve as they are scaled to larger sizes, with some now reaching billions of parameters. Widespread deployment and adoption of these models, however, requires computationally efficient strategies for decoding. In the present work, we study one such strategy: applying multiple frame reduction layers in the encoder to compress encoder outputs into a small number of output frames. While similar techniques have been investigated in previous work, we achieve dramatically more reduction than has previously been demonstrated through the use of multiple funnel reduction layers. Through ablations, we study the impact of various architectural choices in the encoder to identify the most effective strategies. We demonstrate that we can generate one encoder output frame for every 2.56 sec of input speech, without significantly affecting word error rate on a large-scale voice search task, while improving encoder and decoder latencies by 48% and 92% respectively, relative to a strong but computationally expensive baseline.
Massive End-to-end Models for Short Search Queries
Sep 22, 2023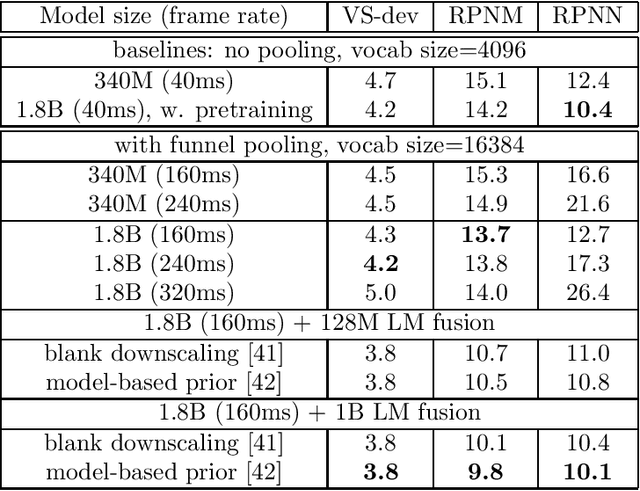
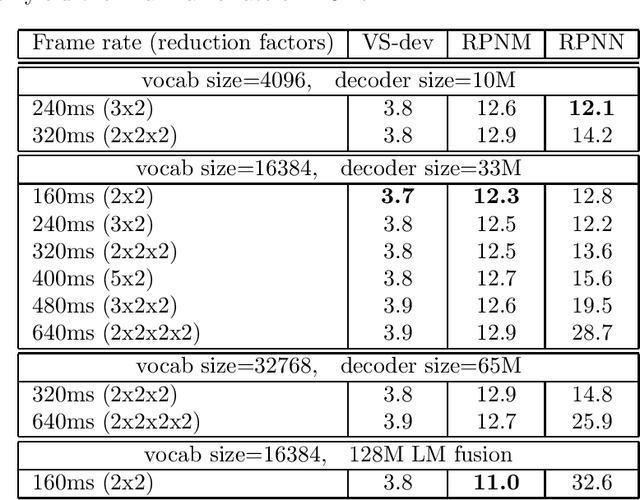
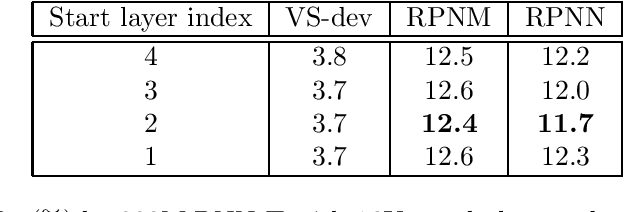
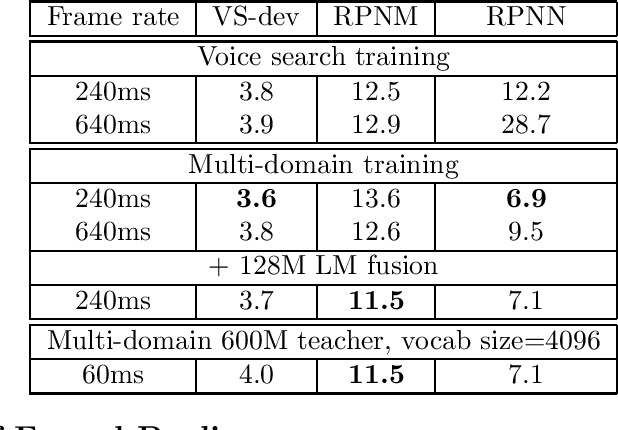
In this work, we investigate two popular end-to-end automatic speech recognition (ASR) models, namely Connectionist Temporal Classification (CTC) and RNN-Transducer (RNN-T), for offline recognition of voice search queries, with up to 2B model parameters. The encoders of our models use the neural architecture of Google's universal speech model (USM), with additional funnel pooling layers to significantly reduce the frame rate and speed up training and inference. We perform extensive studies on vocabulary size, time reduction strategy, and its generalization performance on long-form test sets. Despite the speculation that, as the model size increases, CTC can be as good as RNN-T which builds label dependency into the prediction, we observe that a 900M RNN-T clearly outperforms a 1.8B CTC and is more tolerant to severe time reduction, although the WER gap can be largely removed by LM shallow fusion.
Open-Ended Learning Leads to Generally Capable Agents
Jul 31, 2021
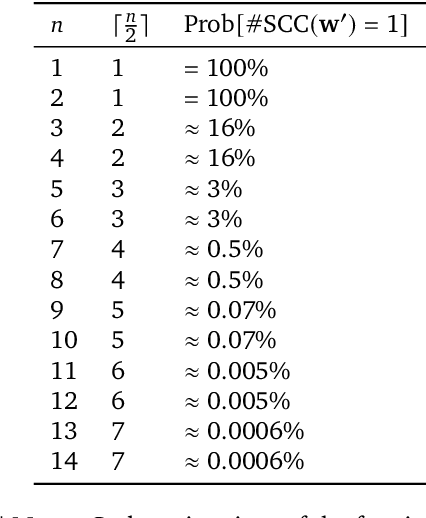
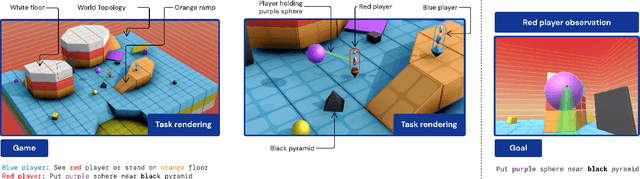

In this work we create agents that can perform well beyond a single, individual task, that exhibit much wider generalisation of behaviour to a massive, rich space of challenges. We define a universe of tasks within an environment domain and demonstrate the ability to train agents that are generally capable across this vast space and beyond. The environment is natively multi-agent, spanning the continuum of competitive, cooperative, and independent games, which are situated within procedurally generated physical 3D worlds. The resulting space is exceptionally diverse in terms of the challenges posed to agents, and as such, even measuring the learning progress of an agent is an open research problem. We propose an iterative notion of improvement between successive generations of agents, rather than seeking to maximise a singular objective, allowing us to quantify progress despite tasks being incomparable in terms of achievable rewards. We show that through constructing an open-ended learning process, which dynamically changes the training task distributions and training objectives such that the agent never stops learning, we achieve consistent learning of new behaviours. The resulting agent is able to score reward in every one of our humanly solvable evaluation levels, with behaviour generalising to many held-out points in the universe of tasks. Examples of this zero-shot generalisation include good performance on Hide and Seek, Capture the Flag, and Tag. Through analysis and hand-authored probe tasks we characterise the behaviour of our agent, and find interesting emergent heuristic behaviours such as trial-and-error experimentation, simple tool use, option switching, and cooperation. Finally, we demonstrate that the general capabilities of this agent could unlock larger scale transfer of behaviour through cheap finetuning.
Decoupling Representation Learning from Reinforcement Learning
Sep 30, 2020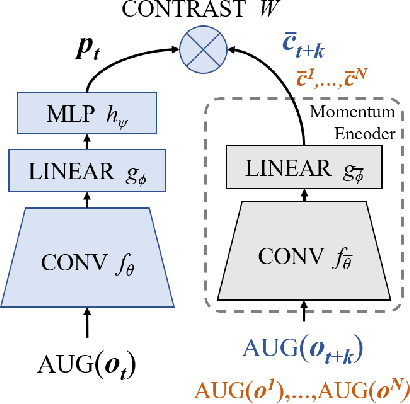

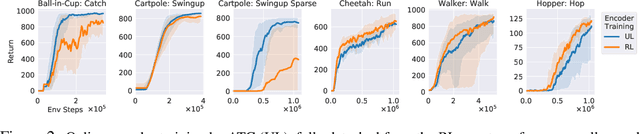
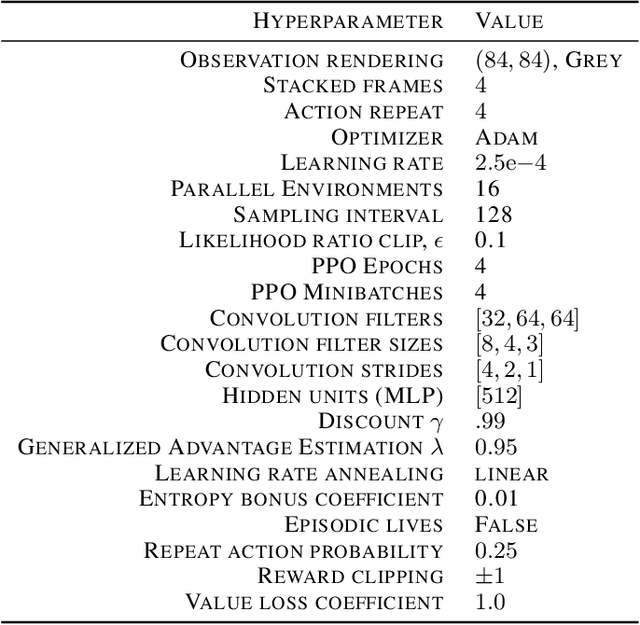
In an effort to overcome limitations of reward-driven feature learning in deep reinforcement learning (RL) from images, we propose decoupling representation learning from policy learning. To this end, we introduce a new unsupervised learning (UL) task, called Augmented Temporal Contrast (ATC), which trains a convolutional encoder to associate pairs of observations separated by a short time difference, under image augmentations and using a contrastive loss. In online RL experiments, we show that training the encoder exclusively using ATC matches or outperforms end-to-end RL in most environments. Additionally, we benchmark several leading UL algorithms by pre-training encoders on expert demonstrations and using them, with weights frozen, in RL agents; we find that agents using ATC-trained encoders outperform all others. We also train multi-task encoders on data from multiple environments and show generalization to different downstream RL tasks. Finally, we ablate components of ATC, and introduce a new data augmentation to enable replay of (compressed) latent images from pre-trained encoders when RL requires augmentation. Our experiments span visually diverse RL benchmarks in DeepMind Control, DeepMind Lab, and Atari, and our complete code is available at https://github.com/astooke/rlpyt/tree/master/rlpyt/ul.
Responsive Safety in Reinforcement Learning by PID Lagrangian Methods
Jul 08, 2020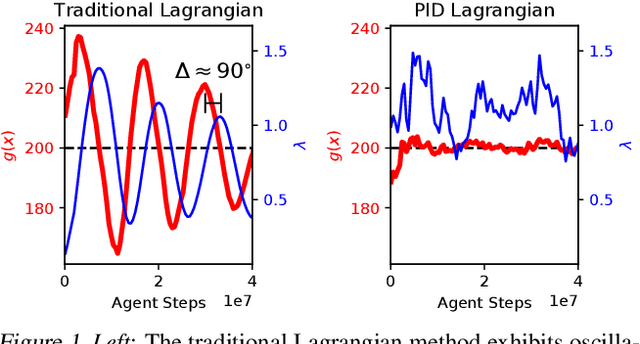
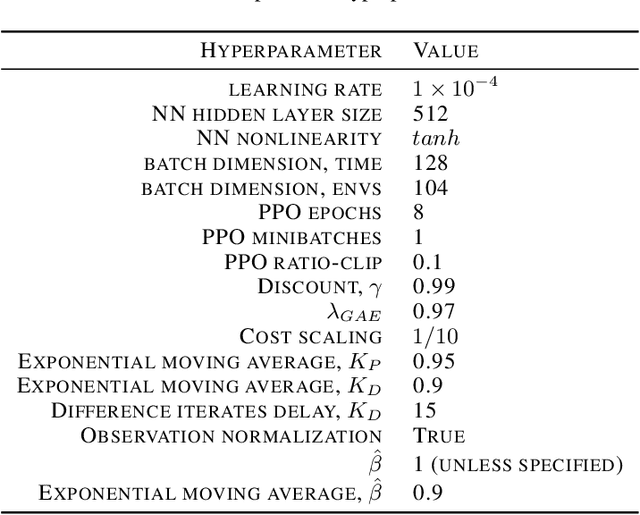
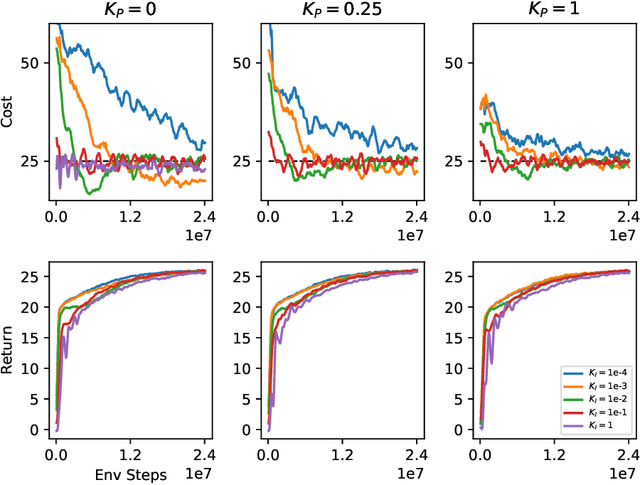

Lagrangian methods are widely used algorithms for constrained optimization problems, but their learning dynamics exhibit oscillations and overshoot which, when applied to safe reinforcement learning, leads to constraint-violating behavior during agent training. We address this shortcoming by proposing a novel Lagrange multiplier update method that utilizes derivatives of the constraint function. We take a controls perspective, wherein the traditional Lagrange multiplier update behaves as \emph{integral} control; our terms introduce \emph{proportional} and \emph{derivative} control, achieving favorable learning dynamics through damping and predictive measures. We apply our PID Lagrangian methods in deep RL, setting a new state of the art in Safety Gym, a safe RL benchmark. Lastly, we introduce a new method to ease controller tuning by providing invariance to the relative numerical scales of reward and cost. Our extensive experiments demonstrate improved performance and hyperparameter robustness, while our algorithms remain nearly as simple to derive and implement as the traditional Lagrangian approach.
Perception-Prediction-Reaction Agents for Deep Reinforcement Learning
Jun 26, 2020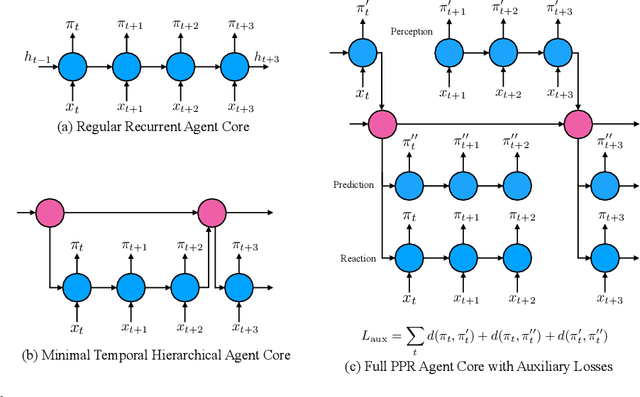

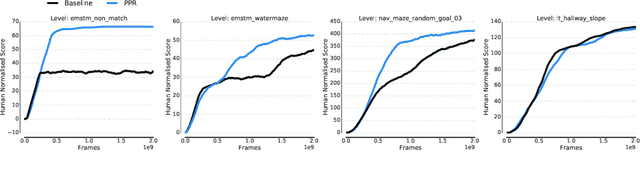
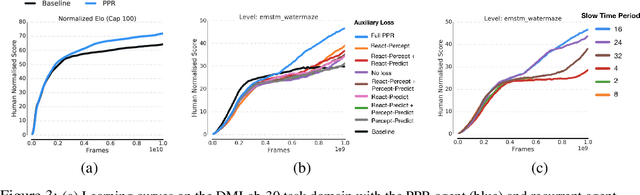
We introduce a new recurrent agent architecture and associated auxiliary losses which improve reinforcement learning in partially observable tasks requiring long-term memory. We employ a temporal hierarchy, using a slow-ticking recurrent core to allow information to flow more easily over long time spans, and three fast-ticking recurrent cores with connections designed to create an information asymmetry. The \emph{reaction} core incorporates new observations with input from the slow core to produce the agent's policy; the \emph{perception} core accesses only short-term observations and informs the slow core; lastly, the \emph{prediction} core accesses only long-term memory. An auxiliary loss regularizes policies drawn from all three cores against each other, enacting the prior that the policy should be expressible from either recent or long-term memory. We present the resulting \emph{Perception-Prediction-Reaction} (PPR) agent and demonstrate its improved performance over a strong LSTM-agent baseline in DMLab-30, particularly in tasks requiring long-term memory. We further show significant improvements in Capture the Flag, an environment requiring agents to acquire a complicated mixture of skills over long time scales. In a series of ablation experiments, we probe the importance of each component of the PPR agent, establishing that the entire, novel combination is necessary for this intriguing result.
Reinforcement Learning with Augmented Data
May 11, 2020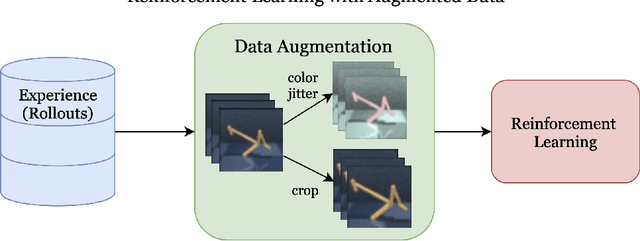
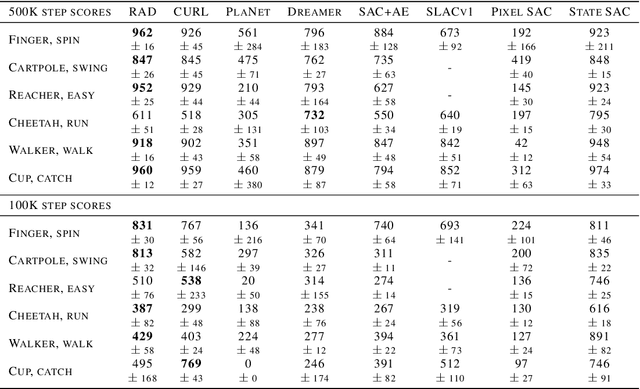

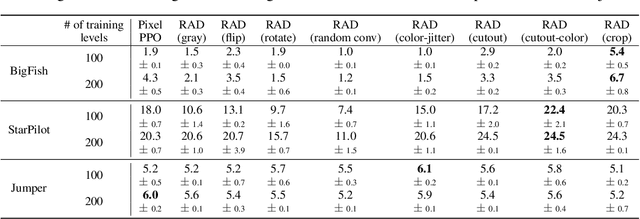
Learning from visual observations is a fundamental yet challenging problem in reinforcement learning (RL). Although algorithmic advancements combined with convolutional neural networks have proved to be a recipe for success, current methods are still lacking on two fronts: (a) sample efficiency of learning and (b) generalization to new environments. To this end, we present RAD: Reinforcement Learning with Augmented Data, a simple plug-and-play module that can enhance any RL algorithm. We show that data augmentations such as random crop, color jitter, patch cutout, and random convolutions can enable simple RL algorithms to match and even outperform complex state-of-the-art methods across common benchmarks in terms of data-efficiency, generalization, and wall-clock speed. We find that data diversity alone can make agents focus on meaningful information from high-dimensional observations without any changes to the reinforcement learning method. On the DeepMind Control Suite, we show that RAD is state-of-the-art in terms of data-efficiency and performance across 15 environments. We further demonstrate that RAD can significantly improve the test-time generalization on several OpenAI ProcGen benchmarks. Finally, our customized data augmentation modules enable faster wall-clock speed compared to competing RL techniques. Our RAD module and training code are available at https://www.github.com/MishaLaskin/rad.
rlpyt: A Research Code Base for Deep Reinforcement Learning in PyTorch
Sep 24, 2019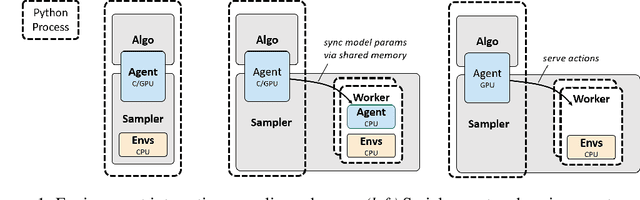

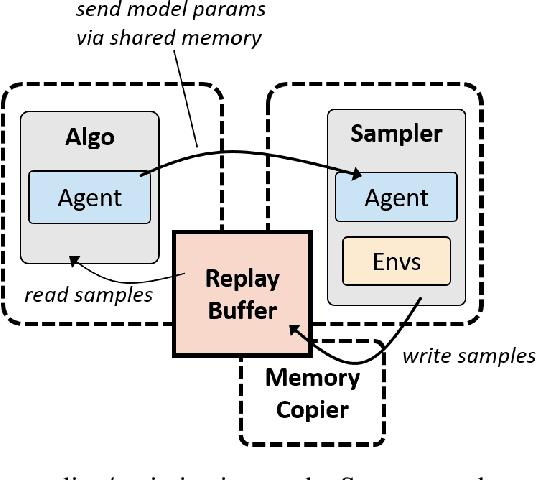
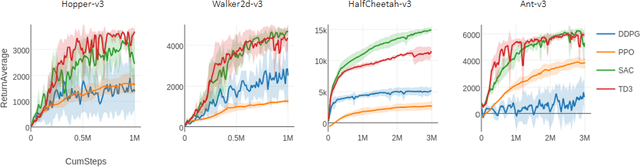
Since the recent advent of deep reinforcement learning for game play and simulated robotic control, a multitude of new algorithms have flourished. Most are model-free algorithms which can be categorized into three families: deep Q-learning, policy gradients, and Q-value policy gradients. These have developed along separate lines of research, such that few, if any, code bases incorporate all three kinds. Yet these algorithms share a great depth of common deep reinforcement learning machinery. We are pleased to share rlpyt, which implements all three algorithm families on top of a shared, optimized infrastructure, in a single repository. It contains modular implementations of many common deep RL algorithms in Python using PyTorch, a leading deep learning library. rlpyt is designed as a high-throughput code base for small- to medium-scale research in deep RL. This white paper summarizes its features, algorithms implemented, and relation to prior work, and concludes with detailed implementation and usage notes. rlpyt is available at https://github.com/astooke/rlpyt.
Accelerated Methods for Deep Reinforcement Learning
Mar 07, 2018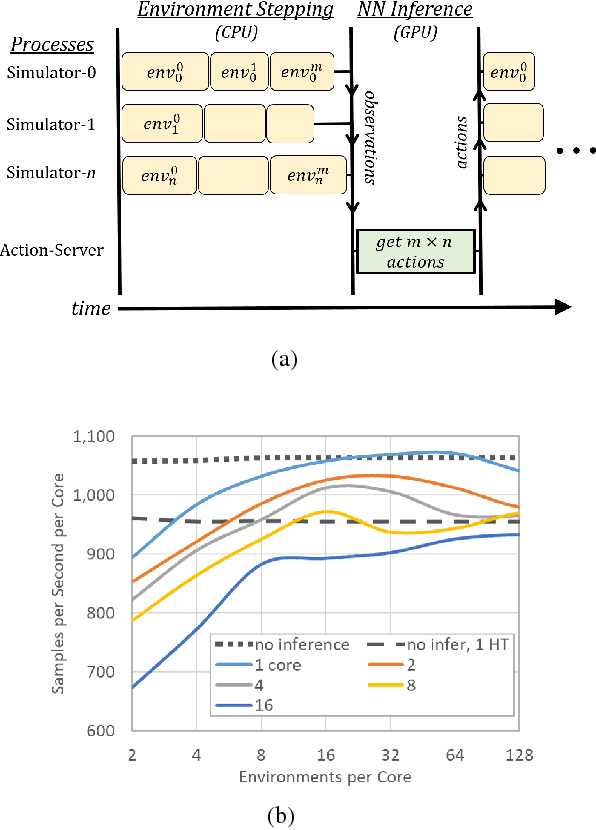
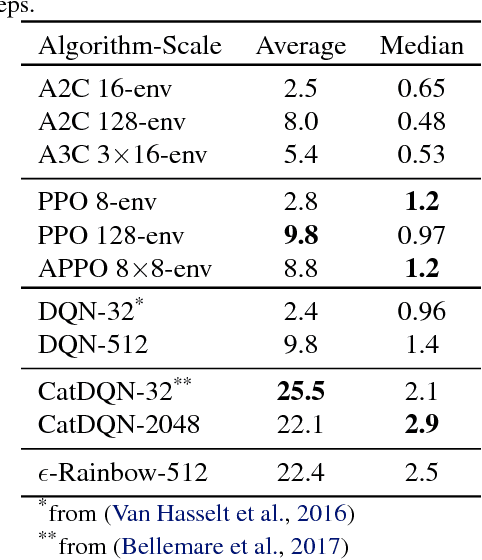
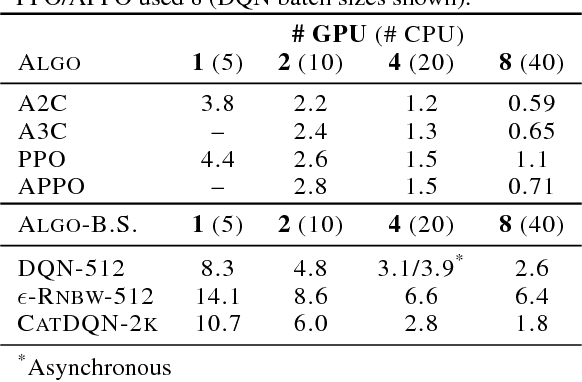
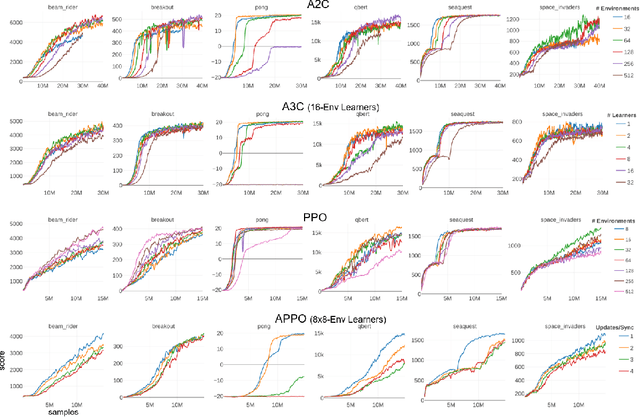
Deep reinforcement learning (RL) has achieved many recent successes, yet experiment turn-around time remains a key bottleneck in research and in practice. We investigate how to optimize existing deep RL algorithms for modern computers, specifically for a combination of CPUs and GPUs. We confirm that both policy gradient and Q-value learning algorithms can be adapted to learn using many parallel simulator instances. We further find it possible to train using batch sizes considerably larger than are standard, without negatively affecting sample complexity or final performance. We leverage these facts to build a unified framework for parallelization that dramatically hastens experiments in both classes of algorithm. All neural network computations use GPUs, accelerating both data collection and training. Our results include using an entire NVIDIA DGX-1 to learn successful strategies in Atari games in single-digit minutes, using both synchronous and asynchronous algorithms.