 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Horizon Planning for Multi-Agent Robots in Partially Observable Environments
Jul 14, 2024



The ability of Language Models (LMs) to understand natural language makes them a powerful tool for parsing human instructions into task plans for autonomous robots. Unlike traditional planning methods that rely on domain-specific knowledge and handcrafted rules, LMs generalize from diverse data and adapt to various tasks with minimal tuning, acting as a compressed knowledge base. However, LMs in their standard form face challenges with long-horizon tasks, particularly in partially observable multi-agent settings. We propose an LM-based Long-Horizon Planner for Multi-Agent Robotics (LLaMAR), a cognitive architecture for planning that achieves state-of-the-art results in long-horizon tasks within partially observable environments. LLaMAR employs a plan-act-correct-verify framework, allowing self-correction from action execution feedback without relying on oracles or simulators. Additionally, we present MAP-THOR, a comprehensive test suite encompassing household tasks of varying complexity within the AI2-THOR environment. Experiments show that LLaMAR achieves a 30% higher success rate compared to other state-of-the-art LM-based multi-agent planners.
Generalization Across Observation Shifts in Reinforcement Learning
Jun 07, 2023



Learning policies which are robust to changes in the environment are critical for real world deployment of Reinforcement Learning agents. They are also necessary for achieving good generalization across environment shifts. We focus on bisimulation metrics, which provide a powerful means for abstracting task relevant components of the observation and learning a succinct representation space for training the agent using reinforcement learning. In this work, we extend the bisimulation framework to also account for context dependent observation shifts. Specifically, we focus on the simulator based learning setting and use alternate observations to learn a representation space which is invariant to observation shifts using a novel bisimulation based objective. This allows us to deploy the agent to varying observation settings during test time and generalize to unseen scenarios. We further provide novel theoretical bounds for simulator fidelity and performance transfer guarantees for using a learnt policy to unseen shifts. Empirical analysis on the high-dimensional image based control domains demonstrates the efficacy of our method.
marl-jax: Multi-agent Reinforcement Leaning framework for Social Generalization
Mar 24, 2023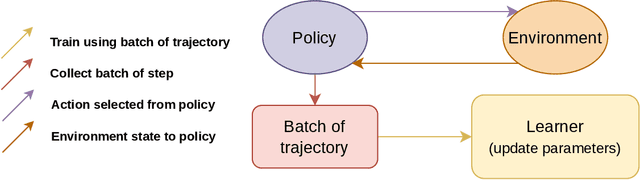
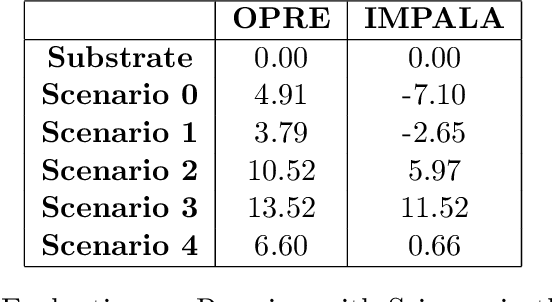
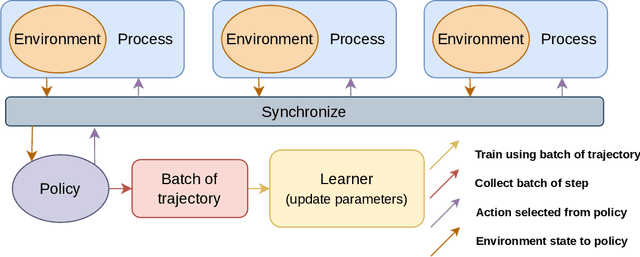
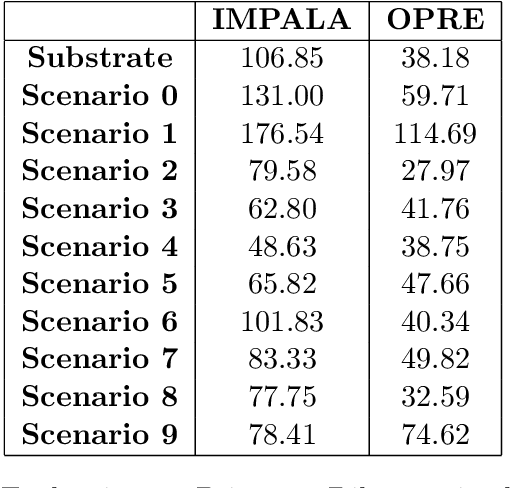
Recent advances in Reinforcement Learning (RL) have led to many exciting applications. These advancements have been driven by improvements in both algorithms and engineering, which have resulted in faster training of RL agents. We present marl-jax, a multi-agent reinforcement learning software package for training and evaluating social generalization of the agents. The package is designed for training a population of agents in multi-agent environments and evaluating their ability to generalize to diverse background agents. It is built on top of DeepMind's JAX ecosystem~\cite{deepmind2020jax} and leverages the RL ecosystem developed by DeepMind. Our framework marl-jax is capable of working in cooperative and competitive, simultaneous-acting environments with multiple agents. The package offers an intuitive and user-friendly command-line interface for training a population and evaluating its generalization capabilities. In conclusion, marl-jax provides a valuable resource for researchers interested in exploring social generalization in the context of MARL. The open-source code for marl-jax is available at: \href{https://github.com/kinalmehta/marl-jax}{https://github.com/kinalmehta/marl-jax}
Trust-Region-Free Policy Optimization for Stochastic Policies
Feb 15, 2023Trust Region Policy Optimization (TRPO) is an iterative method that simultaneously maximizes a surrogate objective and enforces a trust region constraint over consecutive policies in each iteration. The combination of the surrogate objective maximization and the trust region enforcement has been shown to be crucial to guarantee a monotonic policy improvement. However, solving a trust-region-constrained optimization problem can be computationally intensive as it requires many steps of conjugate gradient and a large number of on-policy samples. In this paper, we show that the trust region constraint over policies can be safely substituted by a trust-region-free constraint without compromising the underlying monotonic improvement guarantee. The key idea is to generalize the surrogate objective used in TRPO in a way that a monotonic improvement guarantee still emerges as a result of constraining the maximum advantage-weighted ratio between policies. This new constraint outlines a conservative mechanism for iterative policy optimization and sheds light on practical ways to optimize the generalized surrogate objective. We show that the new constraint can be effectively enforced by being conservative when optimizing the generalized objective function in practice. We call the resulting algorithm Trust-REgion-Free Policy Optimization (TREFree) as it is free of any explicit trust region constraints. Empirical results show that TREFree outperforms TRPO and Proximal Policy Optimization (PPO) in terms of policy performance and sample efficiency.
SMACv2: An Improved Benchmark for Cooperative Multi-Agent Reinforcement Learning
Dec 14, 2022
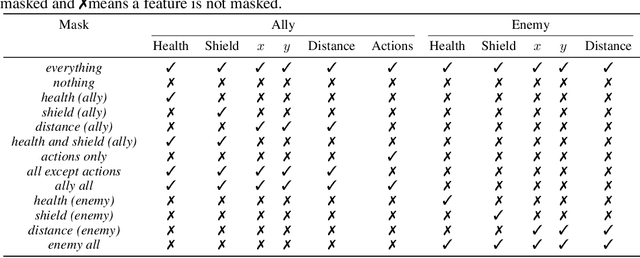
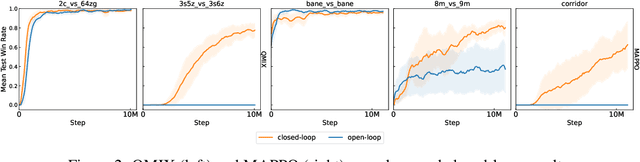
The availability of challenging benchmarks has played a key role in the recent progress of machine learning. In cooperative multi-agent reinforcement learning, the StarCraft Multi-Agent Challenge (SMAC) has become a popular testbed for centralised training with decentralised execution. However, after years of sustained improvement on SMAC, algorithms now achieve near-perfect performance. In this work, we conduct new analysis demonstrating that SMAC is not sufficiently stochastic to require complex closed-loop policies. In particular, we show that an open-loop policy conditioned only on the timestep can achieve non-trivial win rates for many SMAC scenarios. To address this limitation, we introduce SMACv2, a new version of the benchmark where scenarios are procedurally generated and require agents to generalise to previously unseen settings (from the same distribution) during evaluation. We show that these changes ensure the benchmark requires the use of closed-loop policies. We evaluate state-of-the-art algorithms on SMACv2 and show that it presents significant challenges not present in the original benchmark. Our analysis illustrates that SMACv2 addresses the discovered deficiencies of SMAC and can help benchmark the next generation of MARL methods. Videos of training are available at https://sites.google.com/view/smacv2
Effects of Spectral Normalization in Multi-agent Reinforcement Learning
Dec 10, 2022A reliable critic is central to on-policy actor-critic learning. But it becomes challenging to learn a reliable critic in a multi-agent sparse reward scenario due to two factors: 1) The joint action space grows exponentially with the number of agents 2) This, combined with the reward sparseness and environment noise, leads to large sample requirements for accurate learning. We show that regularising the critic with spectral normalization (SN) enables it to learn more robustly, even in multi-agent on-policy sparse reward scenarios. Our experiments show that the regularised critic is quickly able to learn from the sparse rewarding experience in the complex SMAC and RWARE domains. These findings highlight the importance of regularisation in the critic for stable learning.
Generalization in Cooperative Multi-Agent Systems
Jan 31, 2022

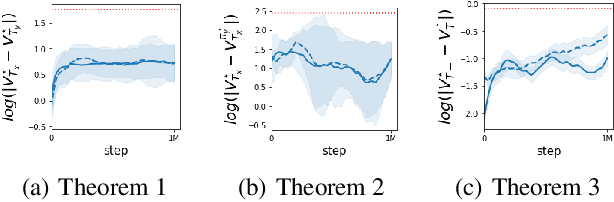

Collective intelligence is a fundamental trait shared by several species of living organisms. It has allowed them to thrive in the diverse environmental conditions that exist on our planet. From simple organisations in an ant colony to complex systems in human groups, collective intelligence is vital for solving complex survival tasks. As is commonly observed, such natural systems are flexible to changes in their structure. Specifically, they exhibit a high degree of generalization when the abilities or the total number of agents changes within a system. We term this phenomenon as Combinatorial Generalization (CG). CG is a highly desirable trait for autonomous systems as it can increase their utility and deployability across a wide range of applications. While recent works addressing specific aspects of CG have shown impressive results on complex domains, they provide no performance guarantees when generalizing towards novel situations. In this work, we shed light on the theoretical underpinnings of CG for cooperative multi-agent systems (MAS). Specifically, we study generalization bounds under a linear dependence of the underlying dynamics on the agent capabilities, which can be seen as a generalization of Successor Features to MAS. We then extend the results first for Lipschitz and then arbitrary dependence of rewards on team capabilities. Finally, empirical analysis on various domains using the framework of multi-agent reinforcement learning highlights important desiderata for multi-agent algorithms towards ensuring CG.
Reinforcement Learning in Factored Action Spaces using Tensor Decompositions
Oct 27, 2021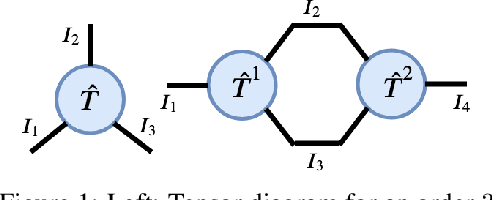
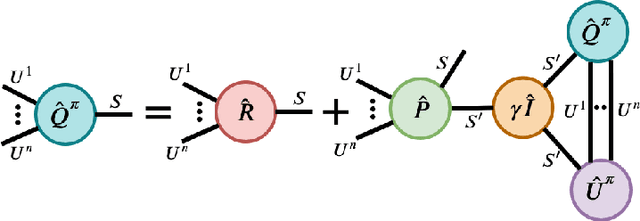
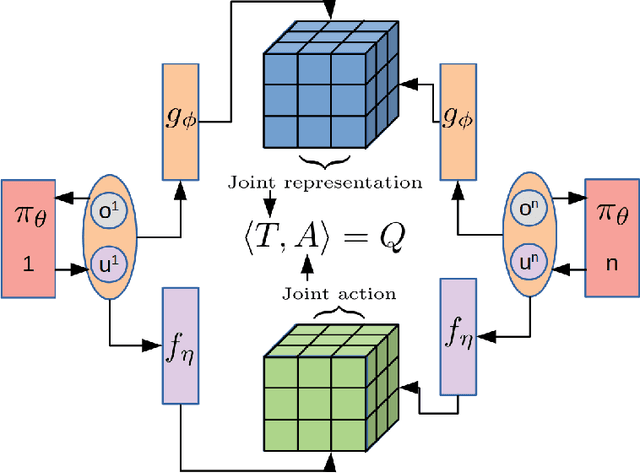
We present an extended abstract for the previously published work TESSERACT [Mahajan et al., 2021], which proposes a novel solution for Reinforcement Learning (RL) in large, factored action spaces using tensor decompositions. The goal of this abstract is twofold: (1) To garner greater interest amongst the tensor research community for creating methods and analysis for approximate RL, (2) To elucidate the generalised setting of factored action spaces where tensor decompositions can be used. We use cooperative multi-agent reinforcement learning scenario as the exemplary setting where the action space is naturally factored across agents and learning becomes intractable without resorting to approximation on the underlying hypothesis space for candidate solutions.
Model based Multi-agent Reinforcement Learning with Tensor Decompositions
Oct 27, 2021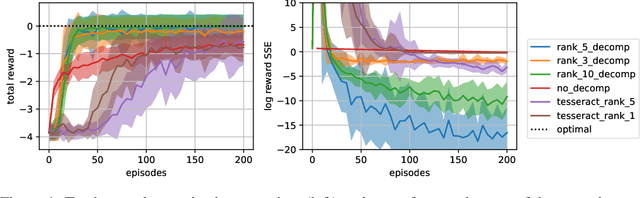
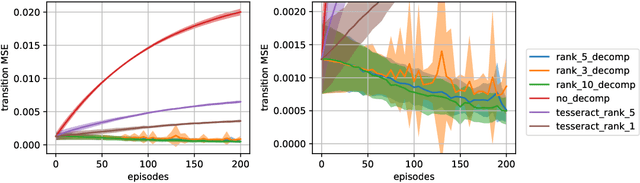
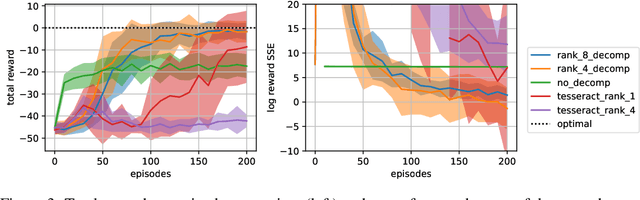
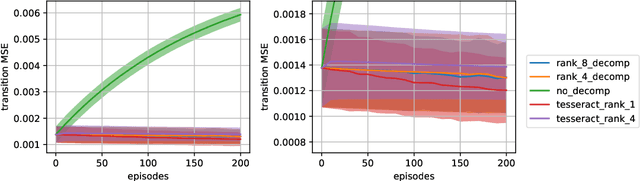
A challenge in multi-agent reinforcement learning is to be able to generalize over intractable state-action spaces. Inspired from Tesseract [Mahajan et al., 2021], this position paper investigates generalisation in state-action space over unexplored state-action pairs by modelling the transition and reward functions as tensors of low CP-rank. Initial experiments on synthetic MDPs show that using tensor decompositions in a model-based reinforcement learning algorithm can lead to much faster convergence if the true transition and reward functions are indeed of low rank.
Open-Ended Learning Leads to Generally Capable Agents
Jul 31, 2021
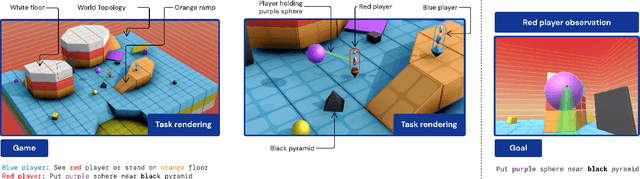

In this work we create agents that can perform well beyond a single, individual task, that exhibit much wider generalisation of behaviour to a massive, rich space of challenges. We define a universe of tasks within an environment domain and demonstrate the ability to train agents that are generally capable across this vast space and beyond. The environment is natively multi-agent, spanning the continuum of competitive, cooperative, and independent games, which are situated within procedurally generated physical 3D worlds. The resulting space is exceptionally diverse in terms of the challenges posed to agents, and as such, even measuring the learning progress of an agent is an open research problem. We propose an iterative notion of improvement between successive generations of agents, rather than seeking to maximise a singular objective, allowing us to quantify progress despite tasks being incomparable in terms of achievable rewards. We show that through constructing an open-ended learning process, which dynamically changes the training task distributions and training objectives such that the agent never stops learning, we achieve consistent learning of new behaviours. The resulting agent is able to score reward in every one of our humanly solvable evaluation levels, with behaviour generalising to many held-out points in the universe of tasks. Examples of this zero-shot generalisation include good performance on Hide and Seek, Capture the Flag, and Tag. Through analysis and hand-authored probe tasks we characterise the behaviour of our agent, and find interesting emergent heuristic behaviours such as trial-and-error experimentation, simple tool use, option switching, and cooperation. Finally, we demonstrate that the general capabilities of this agent could unlock larger scale transfer of behaviour through cheap finetuning.