 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen RL Benchmark: Comprehensive Tracked Experiments for Reinforcement Learning
Feb 05, 2024



In many Reinforcement Learning (RL) papers, learning curves are useful indicators to measure the effectiveness of RL algorithms. However, the complete raw data of the learning curves are rarely available. As a result, it is usually necessary to reproduce the experiments from scratch, which can be time-consuming and error-prone. We present Open RL Benchmark, a set of fully tracked RL experiments, including not only the usual data such as episodic return, but also all algorithm-specific and system metrics. Open RL Benchmark is community-driven: anyone can download, use, and contribute to the data. At the time of writing, more than 25,000 runs have been tracked, for a cumulative duration of more than 8 years. Open RL Benchmark covers a wide range of RL libraries and reference implementations. Special care is taken to ensure that each experiment is precisely reproducible by providing not only the full parameters, but also the versions of the dependencies used to generate it. In addition, Open RL Benchmark comes with a command-line interface (CLI) for easy fetching and generating figures to present the results. In this document, we include two case studies to demonstrate the usefulness of Open RL Benchmark in practice. To the best of our knowledge, Open RL Benchmark is the first RL benchmark of its kind, and the authors hope that it will improve and facilitate the work of researchers in the field.
marl-jax: Multi-agent Reinforcement Leaning framework for Social Generalization
Mar 24, 2023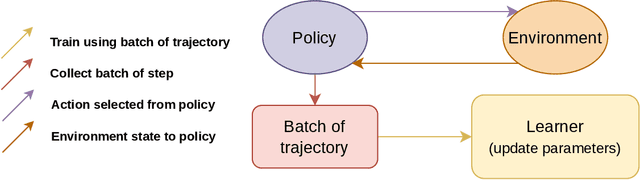
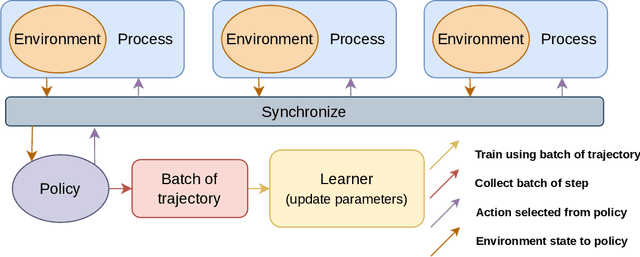
Recent advances in Reinforcement Learning (RL) have led to many exciting applications. These advancements have been driven by improvements in both algorithms and engineering, which have resulted in faster training of RL agents. We present marl-jax, a multi-agent reinforcement learning software package for training and evaluating social generalization of the agents. The package is designed for training a population of agents in multi-agent environments and evaluating their ability to generalize to diverse background agents. It is built on top of DeepMind's JAX ecosystem~\cite{deepmind2020jax} and leverages the RL ecosystem developed by DeepMind. Our framework marl-jax is capable of working in cooperative and competitive, simultaneous-acting environments with multiple agents. The package offers an intuitive and user-friendly command-line interface for training a population and evaluating its generalization capabilities. In conclusion, marl-jax provides a valuable resource for researchers interested in exploring social generalization in the context of MARL. The open-source code for marl-jax is available at: \href{https://github.com/kinalmehta/marl-jax}{https://github.com/kinalmehta/marl-jax}
Effects of Spectral Normalization in Multi-agent Reinforcement Learning
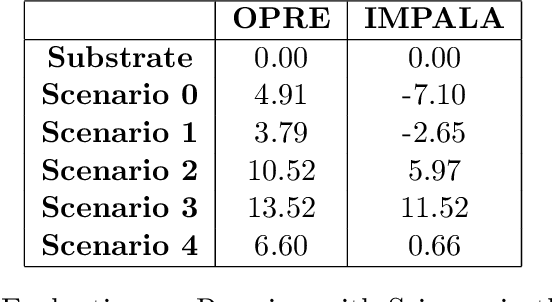
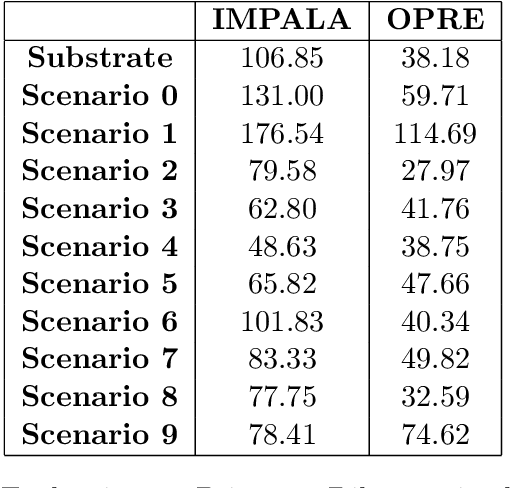
Dec 10, 2022A reliable critic is central to on-policy actor-critic learning. But it becomes challenging to learn a reliable critic in a multi-agent sparse reward scenario due to two factors: 1) The joint action space grows exponentially with the number of agents 2) This, combined with the reward sparseness and environment noise, leads to large sample requirements for accurate learning. We show that regularising the critic with spectral normalization (SN) enables it to learn more robustly, even in multi-agent on-policy sparse reward scenarios. Our experiments show that the regularised critic is quickly able to learn from the sparse rewarding experience in the complex SMAC and RWARE domains. These findings highlight the importance of regularisation in the critic for stable learning.
ReF -- Rotation Equivariant Features for Local Feature Matching
Mar 10, 2022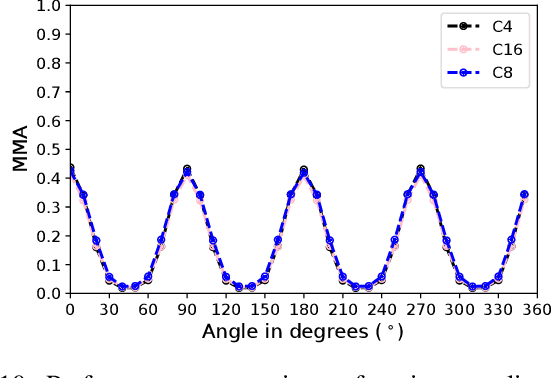
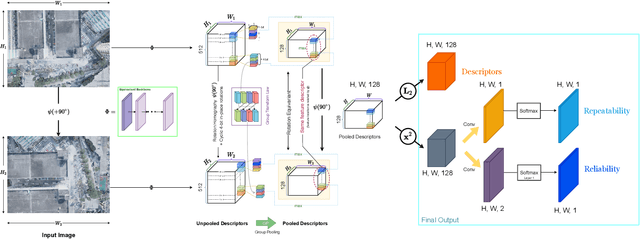
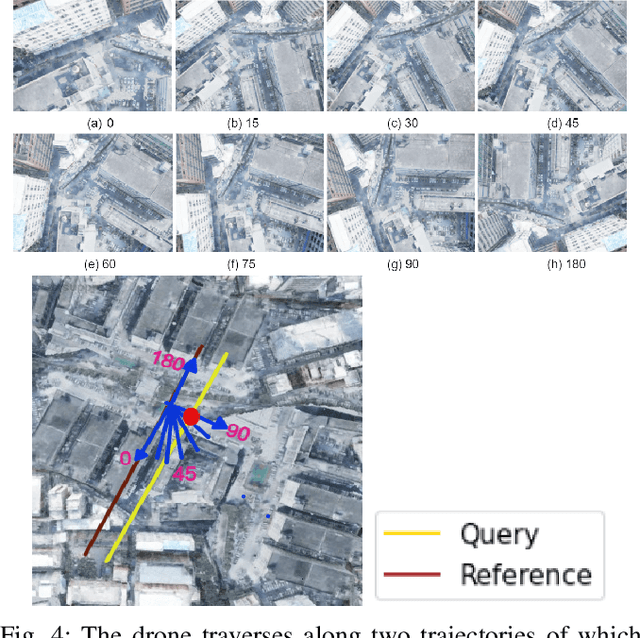
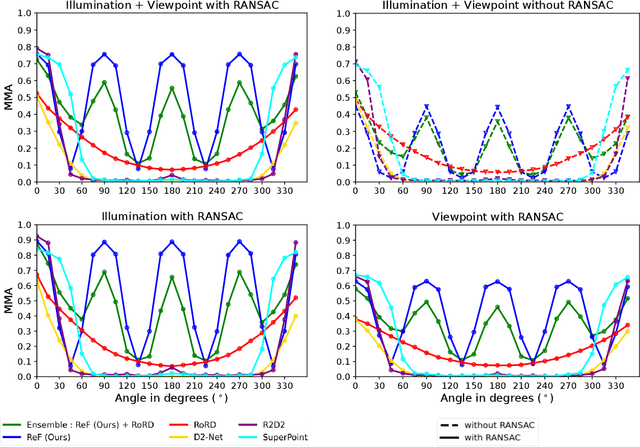
Sparse local feature matching is pivotal for many computer vision and robotics tasks. To improve their invariance to challenging appearance conditions and viewing angles, and hence their usefulness, existing learning-based methods have primarily focused on data augmentation-based training. In this work, we propose an alternative, complementary approach that centers on inducing bias in the model architecture itself to generate `rotation-specific' features using Steerable E2-CNNs, that are then group-pooled to achieve rotation-invariant local features. We demonstrate that this high performance, rotation-specific coverage from the steerable CNNs can be expanded to all rotation angles by combining it with augmentation-trained standard CNNs which have broader coverage but are often inaccurate, thus creating a state-of-the-art rotation-robust local feature matcher. We benchmark our proposed methods against existing techniques on HPatches and a newly proposed UrbanScenes3D-Air dataset for visual place recognition. Furthermore, we present a detailed analysis of the performance effects of ensembling, robust estimation, network architecture variations, and the use of rotation priors.
RoRD: Rotation-Robust Descriptors and Orthographic Views for Local Feature Matching
Mar 15, 2021


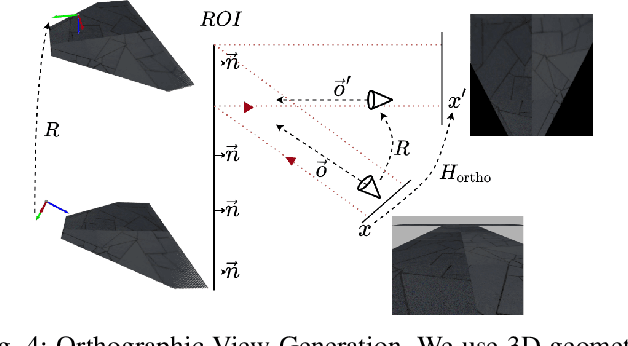
The use of local detectors and descriptors in typical computer vision pipelines work well until variations in viewpoint and appearance change become extreme. Past research in this area has typically focused on one of two approaches to this challenge: the use of projections into spaces more suitable for feature matching under extreme viewpoint changes, and attempting to learn features that are inherently more robust to viewpoint change. In this paper, we present a novel framework that combines learning of invariant descriptors through data augmentation and orthographic viewpoint projection. We propose rotation-robust local descriptors, learnt through training data augmentation based on rotation homographies, and a correspondence ensemble technique that combines vanilla feature correspondences with those obtained through rotation-robust features. Using a range of benchmark datasets as well as contributing a new bespoke dataset for this research domain, we evaluate the effectiveness of the proposed approach on key tasks including pose estimation and visual place recognition. Our system outperforms a range of baseline and state-of-the-art techniques, including enabling higher levels of place recognition precision across opposing place viewpoints and achieves practically-useful performance levels even under extreme viewpoint changes.
W-Net: Reinforced U-Net for Density Map Estimation
Mar 29, 2019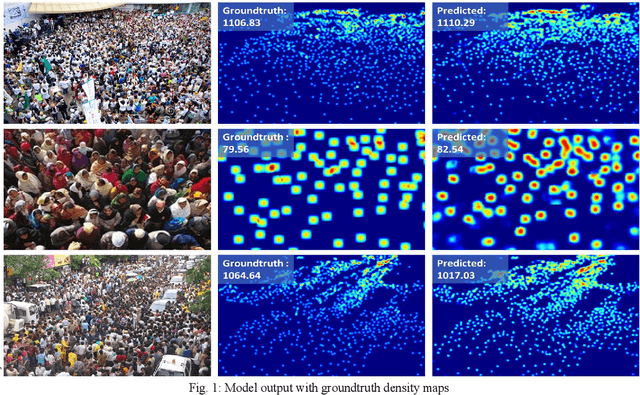

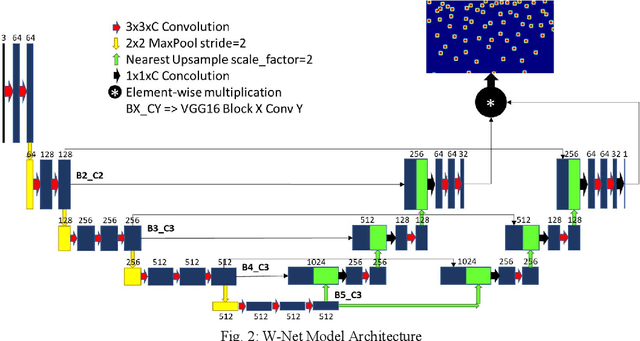
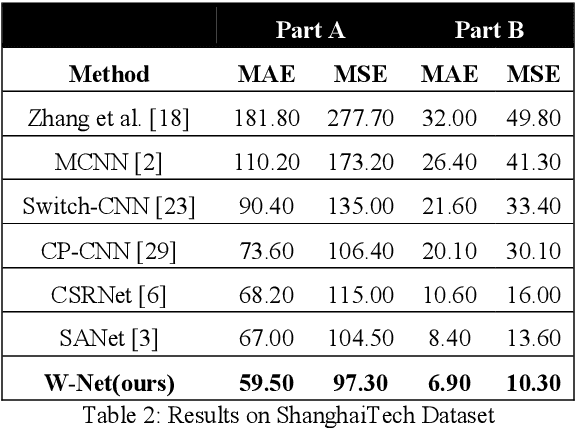
Crowd management is of paramount importance when it comes to preventing stampedes and saving lives, especially in a countries like China and India where the combined population is a third of the global population. Millions of people convene annually all around the nation to celebrate a myriad of events and crowd count estimation is the linchpin of the crowd management system that could prevent stampedes and save lives. We present a network for crowd counting which reports state of the art results on crowd counting benchmarks. Our contributions are, first, a U-Net inspired model which affords us to report state of the art results. Second, we propose an independent decoding Reinforcement branch which helps the network converge much earlier and also enables the network to estimate density maps with high Structural Similarity Index (SSIM). Third, we discuss the drawbacks of the contemporary architectures and empirically show that even though our architecture achieves state of the art results, the merit may be due to the encoder-decoder pipeline instead. Finally, we report the error analysis which shows that the contemporary line of work is at saturation and leaves certain prominent problems unsolved.