 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyLoc: Towards Universal Visual Place Recognition
Aug 01, 2023Visual Place Recognition (VPR) is vital for robot localization. To date, the most performant VPR approaches are environment- and task-specific: while they exhibit strong performance in structured environments (predominantly urban driving), their performance degrades severely in unstructured environments, rendering most approaches brittle to robust real-world deployment. In this work, we develop a universal solution to VPR -- a technique that works across a broad range of structured and unstructured environments (urban, outdoors, indoors, aerial, underwater, and subterranean environments) without any re-training or fine-tuning. We demonstrate that general-purpose feature representations derived from off-the-shelf self-supervised models with no VPR-specific training are the right substrate upon which to build such a universal VPR solution. Combining these derived features with unsupervised feature aggregation enables our suite of methods, AnyLoc, to achieve up to 4X significantly higher performance than existing approaches. We further obtain a 6% improvement in performance by characterizing the semantic properties of these features, uncovering unique domains which encapsulate datasets from similar environments. Our detailed experiments and analysis lay a foundation for building VPR solutions that may be deployed anywhere, anytime, and across anyview. We encourage the readers to explore our project page and interactive demos: https://anyloc.github.io/.
ReF -- Rotation Equivariant Features for Local Feature Matching
Mar 10, 2022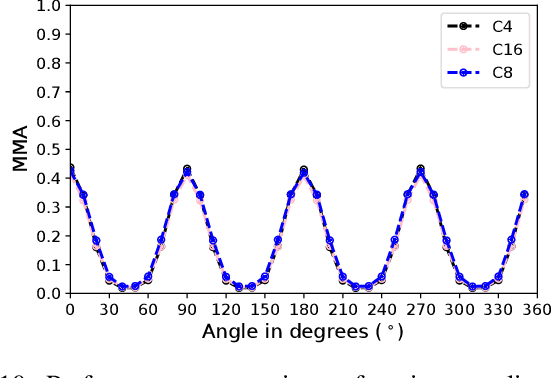
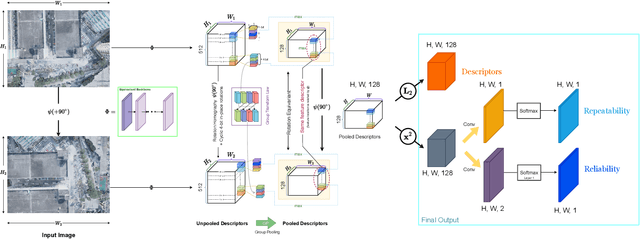
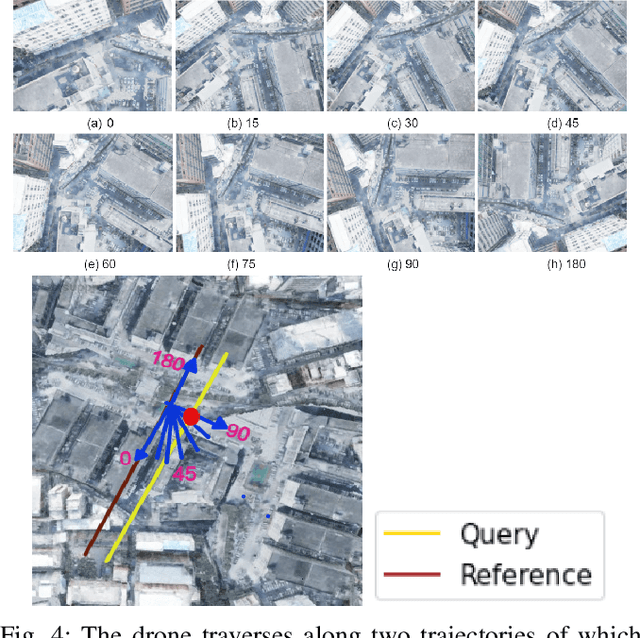
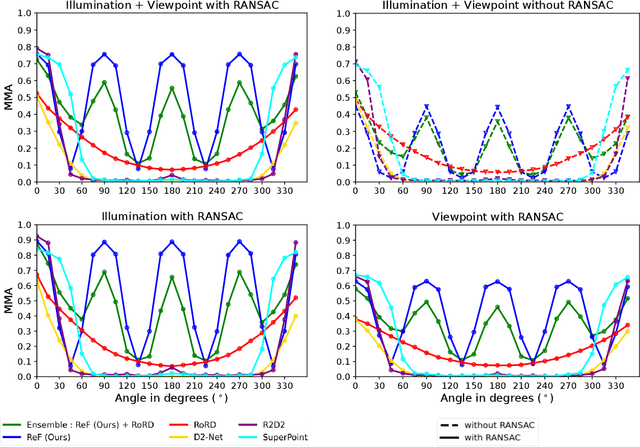
Sparse local feature matching is pivotal for many computer vision and robotics tasks. To improve their invariance to challenging appearance conditions and viewing angles, and hence their usefulness, existing learning-based methods have primarily focused on data augmentation-based training. In this work, we propose an alternative, complementary approach that centers on inducing bias in the model architecture itself to generate `rotation-specific' features using Steerable E2-CNNs, that are then group-pooled to achieve rotation-invariant local features. We demonstrate that this high performance, rotation-specific coverage from the steerable CNNs can be expanded to all rotation angles by combining it with augmentation-trained standard CNNs which have broader coverage but are often inaccurate, thus creating a state-of-the-art rotation-robust local feature matcher. We benchmark our proposed methods against existing techniques on HPatches and a newly proposed UrbanScenes3D-Air dataset for visual place recognition. Furthermore, we present a detailed analysis of the performance effects of ensembling, robust estimation, network architecture variations, and the use of rotation priors.