 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen RL Benchmark: Comprehensive Tracked Experiments for Reinforcement Learning
Feb 05, 2024



In many Reinforcement Learning (RL) papers, learning curves are useful indicators to measure the effectiveness of RL algorithms. However, the complete raw data of the learning curves are rarely available. As a result, it is usually necessary to reproduce the experiments from scratch, which can be time-consuming and error-prone. We present Open RL Benchmark, a set of fully tracked RL experiments, including not only the usual data such as episodic return, but also all algorithm-specific and system metrics. Open RL Benchmark is community-driven: anyone can download, use, and contribute to the data. At the time of writing, more than 25,000 runs have been tracked, for a cumulative duration of more than 8 years. Open RL Benchmark covers a wide range of RL libraries and reference implementations. Special care is taken to ensure that each experiment is precisely reproducible by providing not only the full parameters, but also the versions of the dependencies used to generate it. In addition, Open RL Benchmark comes with a command-line interface (CLI) for easy fetching and generating figures to present the results. In this document, we include two case studies to demonstrate the usefulness of Open RL Benchmark in practice. To the best of our knowledge, Open RL Benchmark is the first RL benchmark of its kind, and the authors hope that it will improve and facilitate the work of researchers in the field.
Real-Time Neural Light Field on Mobile Devices
Dec 15, 2022Recent efforts in Neural Rendering Fields (NeRF) have shown impressive results on novel view synthesis by utilizing implicit neural representation to represent 3D scenes. Due to the process of volumetric rendering, the inference speed for NeRF is extremely slow, limiting the application scenarios of utilizing NeRF on resource-constrained hardware, such as mobile devices. Many works have been conducted to reduce the latency of running NeRF models. However, most of them still require high-end GPU for acceleration or extra storage memory, which is all unavailable on mobile devices. Another emerging direction utilizes the neural light field (NeLF) for speedup, as only one forward pass is performed on a ray to predict the pixel color. Nevertheless, to reach a similar rendering quality as NeRF, the network in NeLF is designed with intensive computation, which is not mobile-friendly. In this work, we propose an efficient network that runs in real-time on mobile devices for neural rendering. We follow the setting of NeLF to train our network. Unlike existing works, we introduce a novel network architecture that runs efficiently on mobile devices with low latency and small size, i.e., saving $15\times \sim 24\times$ storage compared with MobileNeRF. Our model achieves high-resolution generation while maintaining real-time inference for both synthetic and real-world scenes on mobile devices, e.g., $18.04$ms (iPhone 13) for rendering one $1008\times756$ image of real 3D scenes. Additionally, we achieve similar image quality as NeRF and better quality than MobileNeRF (PSNR $26.15$ vs. $25.91$ on the real-world forward-facing dataset).
DeXtreme: Transfer of Agile In-hand Manipulation from Simulation to Reality
Oct 25, 2022Recent work has demonstrated the ability of deep reinforcement learning (RL) algorithms to learn complex robotic behaviours in simulation, including in the domain of multi-fingered manipulation. However, such models can be challenging to transfer to the real world due to the gap between simulation and reality. In this paper, we present our techniques to train a) a policy that can perform robust dexterous manipulation on an anthropomorphic robot hand and b) a robust pose estimator suitable for providing reliable real-time information on the state of the object being manipulated. Our policies are trained to adapt to a wide range of conditions in simulation. Consequently, our vision-based policies significantly outperform the best vision policies in the literature on the same reorientation task and are competitive with policies that are given privileged state information via motion capture systems. Our work reaffirms the possibilities of sim-to-real transfer for dexterous manipulation in diverse kinds of hardware and simulator setups, and in our case, with the Allegro Hand and Isaac Gym GPU-based simulation. Furthermore, it opens up possibilities for researchers to achieve such results with commonly-available, affordable robot hands and cameras. Videos of the resulting policy and supplementary information, including experiments and demos, can be found at \url{https://dextreme.org/}
EnvPool: A Highly Parallel Reinforcement Learning Environment Execution Engine
Jun 21, 2022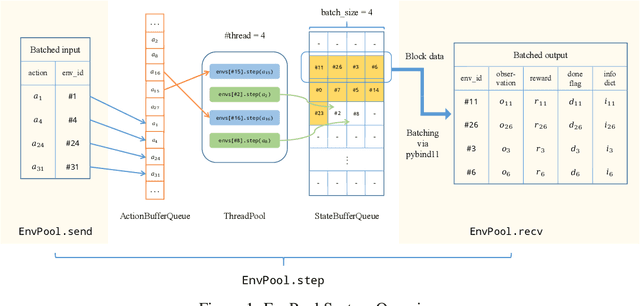
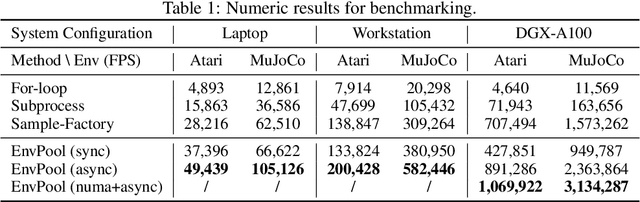
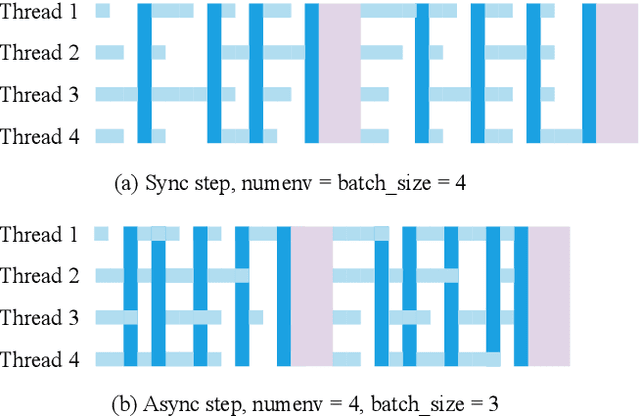
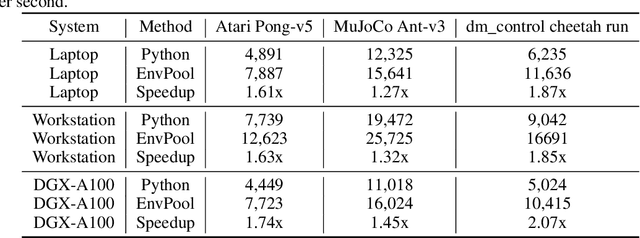
There has been significant progress in developing reinforcement learning (RL) training systems. Past works such as IMPALA, Apex, Seed RL, Sample Factory, and others aim to improve the system's overall throughput. In this paper, we try to address a common bottleneck in the RL training system, i.e., parallel environment execution, which is often the slowest part of the whole system but receives little attention. With a curated design for paralleling RL environments, we have improved the RL environment simulation speed across different hardware setups, ranging from a laptop, and a modest workstation, to a high-end machine like NVIDIA DGX-A100. On a high-end machine, EnvPool achieves 1 million frames per second for the environment execution on Atari environments and 3 million frames per second on MuJoCo environments. When running on a laptop, the speed of EnvPool is 2.8 times of the Python subprocess. Moreover, great compatibility with existing RL training libraries has been demonstrated in the open-sourced community, including CleanRL, rl_games, DeepMind Acme, etc. Finally, EnvPool allows researchers to iterate their ideas at a much faster pace and has the great potential to become the de facto RL environment execution engine. Example runs show that it takes only 5 minutes to train Atari Pong and MuJoCo Ant, both on a laptop. EnvPool has already been open-sourced at https://github.com/sail-sg/envpool.
Transferring Dexterous Manipulation from GPU Simulation to a Remote Real-World TriFinger
Aug 22, 2021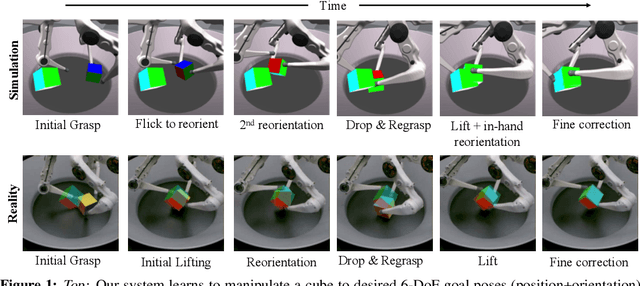
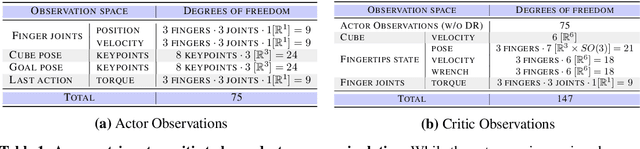
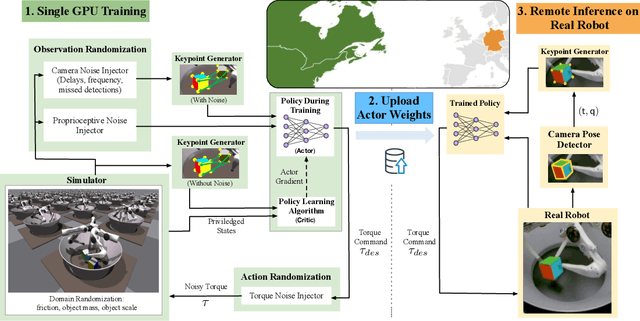
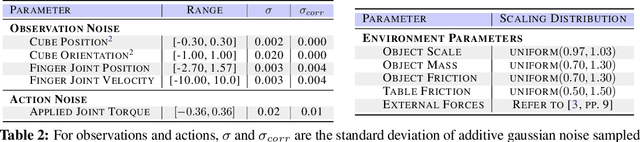
We present a system for learning a challenging dexterous manipulation task involving moving a cube to an arbitrary 6-DoF pose with only 3-fingers trained with NVIDIA's IsaacGym simulator. We show empirical benefits, both in simulation and sim-to-real transfer, of using keypoints as opposed to position+quaternion representations for the object pose in 6-DoF for policy observations and in reward calculation to train a model-free reinforcement learning agent. By utilizing domain randomization strategies along with the keypoint representation of the pose of the manipulated object, we achieve a high success rate of 83% on a remote TriFinger system maintained by the organizers of the Real Robot Challenge. With the aim of assisting further research in learning in-hand manipulation, we make the codebase of our system, along with trained checkpoints that come with billions of steps of experience available, at https://s2r2-ig.github.io
Is Independent Learning All You Need in the StarCraft Multi-Agent Challenge?
Nov 18, 2020


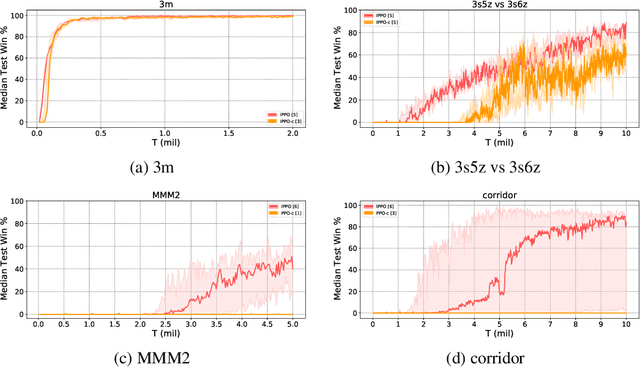
Most recently developed approaches to cooperative multi-agent reinforcement learning in the \emph{centralized training with decentralized execution} setting involve estimating a centralized, joint value function. In this paper, we demonstrate that, despite its various theoretical shortcomings, Independent PPO (IPPO), a form of independent learning in which each agent simply estimates its local value function, can perform just as well as or better than state-of-the-art joint learning approaches on popular multi-agent benchmark suite SMAC with little hyperparameter tuning. We also compare IPPO to several variants; the results suggest that IPPO's strong performance may be due to its robustness to some forms of environment non-stationarity.