 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Prosocial Ranking Challenge: Reducing Polarization on Social Media without Sacrificing Engagement
Mar 20, 2026We report the first direct comparisons of multiple alternative social media algorithms on multiple platforms on outcomes of societal interest. We used a browser extension to modify which posts were shown to desktop social media users, randomly assigning 9,386 users to a control group or one of five alternative ranking algorithms which simultaneously altered content across three platforms for six months during the US 2024 presidential election. This reduced our preregistered index of affective polarization by an average of 0.03 standard deviations (p < 0.05), including a 1.5 degree decrease in differences between the 100 point inparty and outparty feeling thermometers. We saw reductions in active use time for Facebook (-0.37 min/day) and Reddit (-0.2 min/day), but an increase of 0.32 min/day (p < 0.01) for X/Twitter. We saw an increase in reports of negative social media experiences but found no effects on well-being, news knowledge, outgroup empathy, perceptions of and support for partisan violence. This implies that bridging content can improve some societal outcomes without necessarily conflicting with the engagement-driven business model of social media.
Language Models Can Reduce Asymmetry in Information Markets
Mar 21, 2024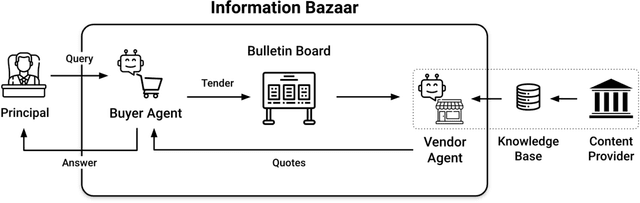

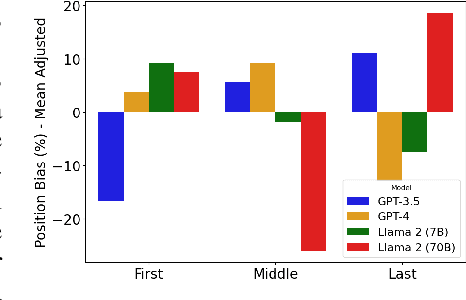
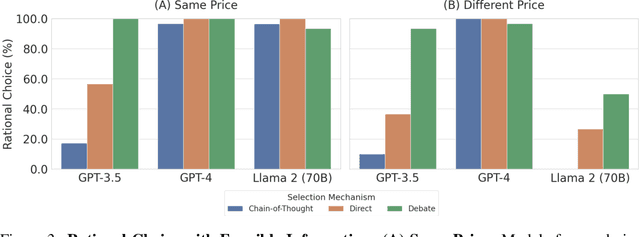
This work addresses the buyer's inspection paradox for information markets. The paradox is that buyers need to access information to determine its value, while sellers need to limit access to prevent theft. To study this, we introduce an open-source simulated digital marketplace where intelligent agents, powered by language models, buy and sell information on behalf of external participants. The central mechanism enabling this marketplace is the agents' dual capabilities: they not only have the capacity to assess the quality of privileged information but also come equipped with the ability to forget. This ability to induce amnesia allows vendors to grant temporary access to proprietary information, significantly reducing the risk of unauthorized retention while enabling agents to accurately gauge the information's relevance to specific queries or tasks. To perform well, agents must make rational decisions, strategically explore the marketplace through generated sub-queries, and synthesize answers from purchased information. Concretely, our experiments (a) uncover biases in language models leading to irrational behavior and evaluate techniques to mitigate these biases, (b) investigate how price affects demand in the context of informational goods, and (c) show that inspection and higher budgets both lead to higher quality outcomes.
Real Robot Challenge 2022: Learning Dexterous Manipulation from Offline Data in the Real World
Sep 04, 2023Experimentation on real robots is demanding in terms of time and costs. For this reason, a large part of the reinforcement learning (RL) community uses simulators to develop and benchmark algorithms. However, insights gained in simulation do not necessarily translate to real robots, in particular for tasks involving complex interactions with the environment. The Real Robot Challenge 2022 therefore served as a bridge between the RL and robotics communities by allowing participants to experiment remotely with a real robot - as easily as in simulation. In the last years, offline reinforcement learning has matured into a promising paradigm for learning from pre-collected datasets, alleviating the reliance on expensive online interactions. We therefore asked the participants to learn two dexterous manipulation tasks involving pushing, grasping, and in-hand orientation from provided real-robot datasets. An extensive software documentation and an initial stage based on a simulation of the real set-up made the competition particularly accessible. By giving each team plenty of access budget to evaluate their offline-learned policies on a cluster of seven identical real TriFinger platforms, we organized an exciting competition for machine learners and roboticists alike. In this work we state the rules of the competition, present the methods used by the winning teams and compare their results with a benchmark of state-of-the-art offline RL algorithms on the challenge datasets.
Generative Social Choice
Sep 03, 2023Traditionally, social choice theory has only been applicable to choices among a few predetermined alternatives but not to more complex decisions such as collectively selecting a textual statement. We introduce generative social choice, a framework that combines the mathematical rigor of social choice theory with large language models' capability to generate text and extrapolate preferences. This framework divides the design of AI-augmented democratic processes into two components: first, proving that the process satisfies rigorous representation guarantees when given access to oracle queries; second, empirically validating that these queries can be approximately implemented using a large language model. We illustrate this framework by applying it to the problem of generating a slate of statements that is representative of opinions expressed as free-form text, for instance in an online deliberative process.
Benchmarking Offline Reinforcement Learning on Real-Robot Hardware
Jul 28, 2023



Learning policies from previously recorded data is a promising direction for real-world robotics tasks, as online learning is often infeasible. Dexterous manipulation in particular remains an open problem in its general form. The combination of offline reinforcement learning with large diverse datasets, however, has the potential to lead to a breakthrough in this challenging domain analogously to the rapid progress made in supervised learning in recent years. To coordinate the efforts of the research community toward tackling this problem, we propose a benchmark including: i) a large collection of data for offline learning from a dexterous manipulation platform on two tasks, obtained with capable RL agents trained in simulation; ii) the option to execute learned policies on a real-world robotic system and a simulation for efficient debugging. We evaluate prominent open-sourced offline reinforcement learning algorithms on the datasets and provide a reproducible experimental setup for offline reinforcement learning on real systems.
Dexterous Robotic Manipulation using Deep Reinforcement Learning and Knowledge Transfer for Complex Sparse Reward-based Tasks
May 19, 2022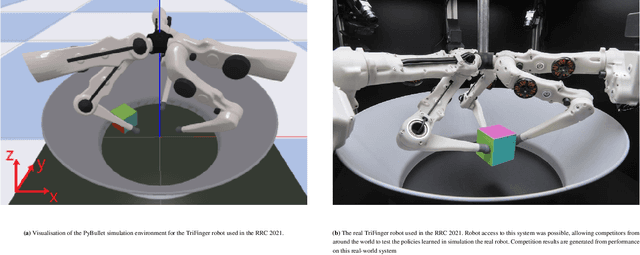

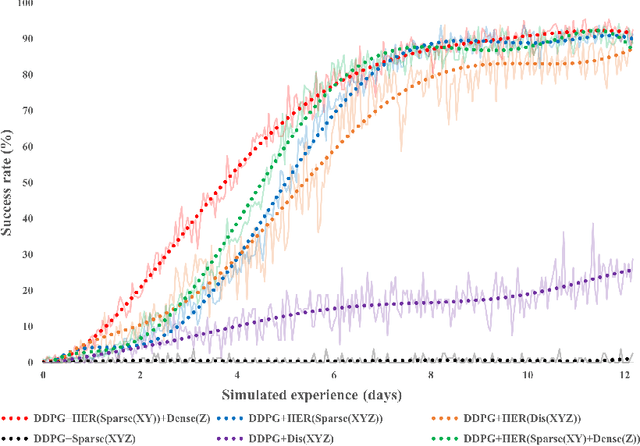

This paper describes a deep reinforcement learning (DRL) approach that won Phase 1 of the Real Robot Challenge (RRC) 2021, and then extends this method to a more difficult manipulation task. The RRC consisted of using a TriFinger robot to manipulate a cube along a specified positional trajectory, but with no requirement for the cube to have any specific orientation. We used a relatively simple reward function, a combination of goal-based sparse reward and distance reward, in conjunction with Hindsight Experience Replay (HER) to guide the learning of the DRL agent (Deep Deterministic Policy Gradient (DDPG)). Our approach allowed our agents to acquire dexterous robotic manipulation strategies in simulation. These strategies were then applied to the real robot and outperformed all other competition submissions, including those using more traditional robotic control techniques, in the final evaluation stage of the RRC. Here we extend this method, by modifying the task of Phase 1 of the RRC to require the robot to maintain the cube in a particular orientation, while the cube is moved along the required positional trajectory. The requirement to also orient the cube makes the agent unable to learn the task through blind exploration due to increased problem complexity. To circumvent this issue, we make novel use of a Knowledge Transfer (KT) technique that allows the strategies learned by the agent in the original task (which was agnostic to cube orientation) to be transferred to this task (where orientation matters). KT allowed the agent to learn and perform the extended task in the simulator, which improved the average positional deviation from 0.134 m to 0.02 m, and average orientation deviation from 142{\deg} to 76{\deg} during evaluation. This KT concept shows good generalisation properties and could be applied to any actor-critic learning algorithm.
A Robot Cluster for Reproducible Research in Dexterous Manipulation
Sep 22, 2021

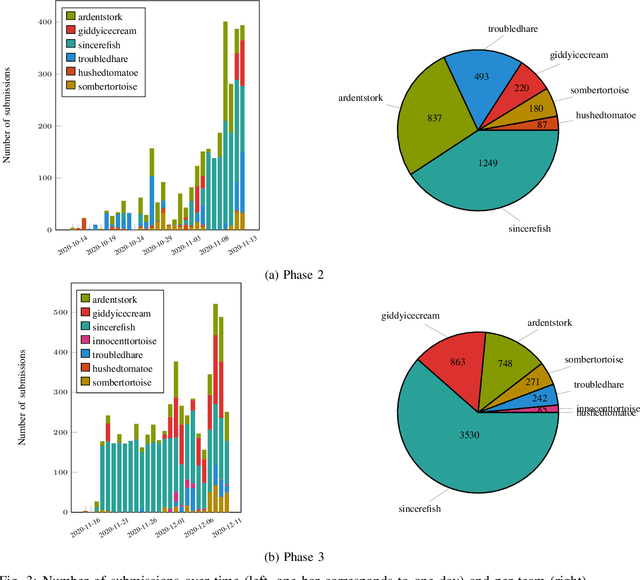
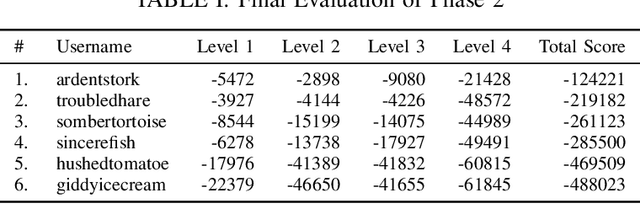
Dexterous manipulation remains an open problem in robotics. To coordinate efforts of the research community towards tackling this problem, we propose a shared benchmark. We designed and built robotic platforms that are hosted at the MPI-IS and can be accessed remotely. Each platform consists of three robotic fingers that are capable of dexterous object manipulation. Users are able to control the platforms remotely by submitting code that is executed automatically, akin to a computational cluster. Using this setup, i) we host robotics competitions, where teams from anywhere in the world access our platforms to tackle challenging tasks, ii) we publish the datasets collected during these competitions (consisting of hundreds of robot hours), and iii) we give researchers access to these platforms for their own projects.
Transferring Dexterous Manipulation from GPU Simulation to a Remote Real-World TriFinger
Aug 22, 2021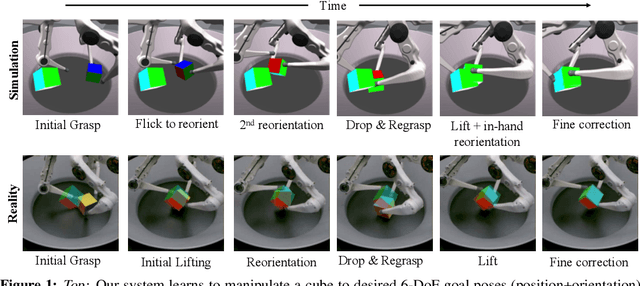
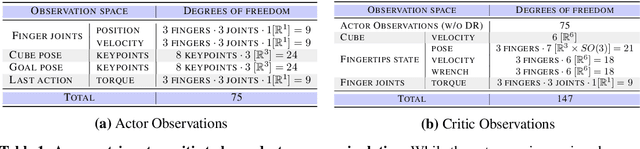
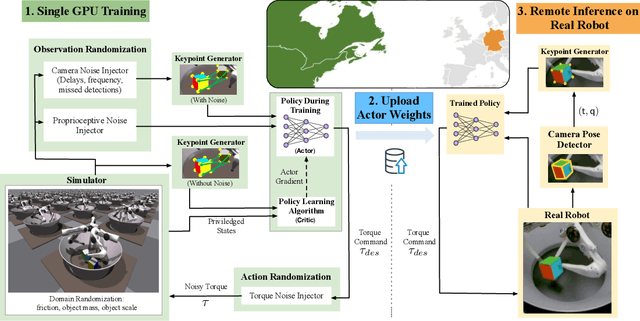
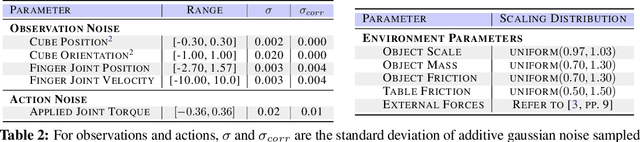
We present a system for learning a challenging dexterous manipulation task involving moving a cube to an arbitrary 6-DoF pose with only 3-fingers trained with NVIDIA's IsaacGym simulator. We show empirical benefits, both in simulation and sim-to-real transfer, of using keypoints as opposed to position+quaternion representations for the object pose in 6-DoF for policy observations and in reward calculation to train a model-free reinforcement learning agent. By utilizing domain randomization strategies along with the keypoint representation of the pose of the manipulated object, we achieve a high success rate of 83% on a remote TriFinger system maintained by the organizers of the Real Robot Challenge. With the aim of assisting further research in learning in-hand manipulation, we make the codebase of our system, along with trained checkpoints that come with billions of steps of experience available, at https://s2r2-ig.github.io
Representation Learning for Out-Of-Distribution Generalization in Reinforcement Learning
Jul 12, 2021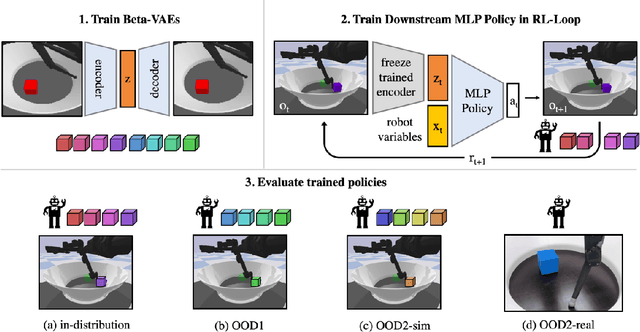
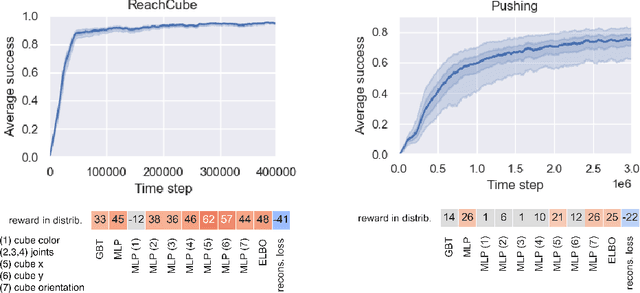
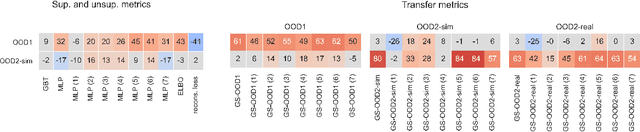
Learning data representations that are useful for various downstream tasks is a cornerstone of artificial intelligence. While existing methods are typically evaluated on downstream tasks such as classification or generative image quality, we propose to assess representations through their usefulness in downstream control tasks, such as reaching or pushing objects. By training over 10,000 reinforcement learning policies, we extensively evaluate to what extent different representation properties affect out-of-distribution (OOD) generalization. Finally, we demonstrate zero-shot transfer of these policies from simulation to the real world, without any domain randomization or fine-tuning. This paper aims to establish the first systematic characterization of the usefulness of learned representations for real-world OOD downstream tasks.
Regret Bounds for Gaussian-Process Optimization in Large Domains
Apr 29, 2021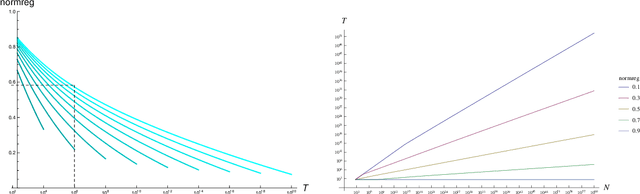
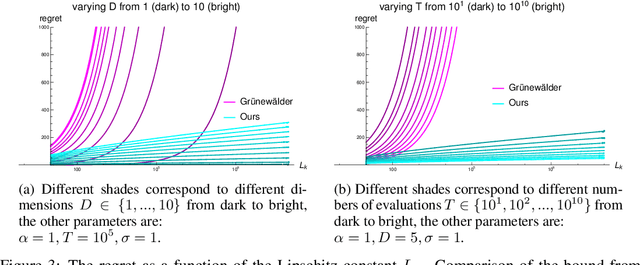
The goal of this paper is to characterize Gaussian-Process optimization in the setting where the function domain is large relative to the number of admissible function evaluations, i.e., where it is impossible to find the global optimum. We provide upper bounds on the suboptimality (Bayesian simple regret) of the solution found by optimization strategies that are closely related to the widely used expected improvement (EI) and upper confidence bound (UCB) algorithms. These regret bounds illuminate the relationship between the number of evaluations, the domain size (i.e. cardinality of finite domains / Lipschitz constant of the covariance function in continuous domains), and the optimality of the retrieved function value. In particular, they show that even when the number of evaluations is far too small to find the global optimum, we can find nontrivial function values (e.g. values that achieve a certain ratio with the optimal value).