 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptable Cardiovascular Disease Risk Prediction from Heterogeneous Data using Large Language Models
May 30, 2025Cardiovascular disease (CVD) risk prediction models are essential for identifying high-risk individuals and guiding preventive actions. However, existing models struggle with the challenges of real-world clinical practice as they oversimplify patient profiles, rely on rigid input schemas, and are sensitive to distribution shifts. We developed AdaCVD, an adaptable CVD risk prediction framework built on large language models extensively fine-tuned on over half a million participants from the UK Biobank. In benchmark comparisons, AdaCVD surpasses established risk scores and standard machine learning approaches, achieving state-of-the-art performance. Crucially, for the first time, it addresses key clinical challenges across three dimensions: it flexibly incorporates comprehensive yet variable patient information; it seamlessly integrates both structured data and unstructured text; and it rapidly adapts to new patient populations using minimal additional data. In stratified analyses, it demonstrates robust performance across demographic, socioeconomic, and clinical subgroups, including underrepresented cohorts. AdaCVD offers a promising path toward more flexible, AI-driven clinical decision support tools suited to the realities of heterogeneous and dynamic healthcare environments.
Multi-megabase scale genome interpretation with genetic language models
Jan 13, 2025Understanding how molecular changes caused by genetic variation drive disease risk is crucial for deciphering disease mechanisms. However, interpreting genome sequences is challenging because of the vast size of the human genome, and because its consequences manifest across a wide range of cells, tissues and scales -- spanning from molecular to whole organism level. Here, we present Phenformer, a multi-scale genetic language model that learns to generate mechanistic hypotheses as to how differences in genome sequence lead to disease-relevant changes in expression across cell types and tissues directly from DNA sequences of up to 88 million base pairs. Using whole genome sequencing data from more than 150 000 individuals, we show that Phenformer generates mechanistic hypotheses about disease-relevant cell and tissue types that match literature better than existing state-of-the-art methods, while using only sequence data. Furthermore, disease risk predictors enriched by Phenformer show improved prediction performance and generalisation to diverse populations. Accurate multi-megabase scale interpretation of whole genomes without additional experimental data enables both a deeper understanding of molecular mechanisms involved in disease and improved disease risk prediction at the level of individuals.
Unlearning via Sparse Representations
Nov 26, 2023Machine \emph{unlearning}, which involves erasing knowledge about a \emph{forget set} from a trained model, can prove to be costly and infeasible by existing techniques. We propose a nearly compute-free zero-shot unlearning technique based on a discrete representational bottleneck. We show that the proposed technique efficiently unlearns the forget set and incurs negligible damage to the model's performance on the rest of the data set. We evaluate the proposed technique on the problem of \textit{class unlearning} using three datasets: CIFAR-10, CIFAR-100, and LACUNA-100. We compare the proposed technique to SCRUB, a state-of-the-art approach which uses knowledge distillation for unlearning. Across all three datasets, the proposed technique performs as well as, if not better than SCRUB while incurring almost no computational cost.
A General Purpose Neural Architecture for Geospatial Systems
Nov 04, 2022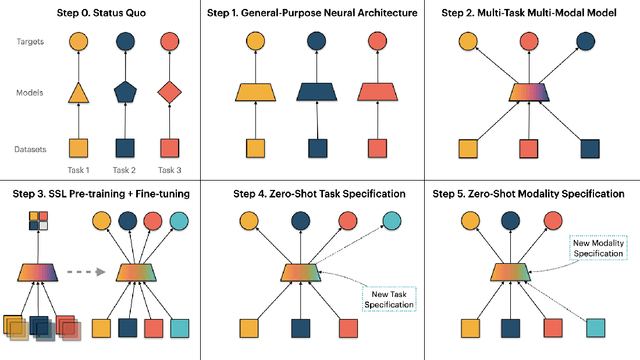
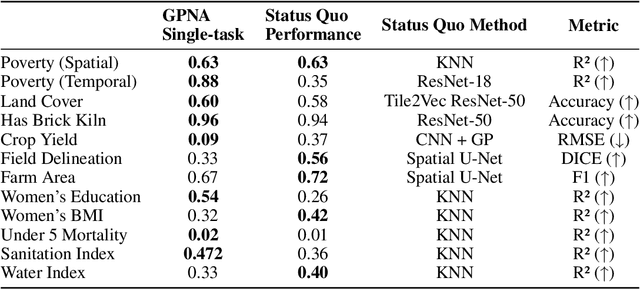
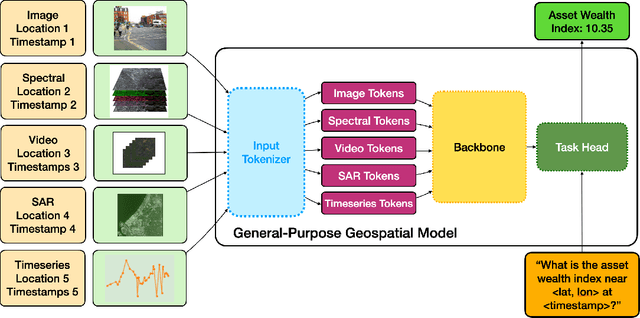
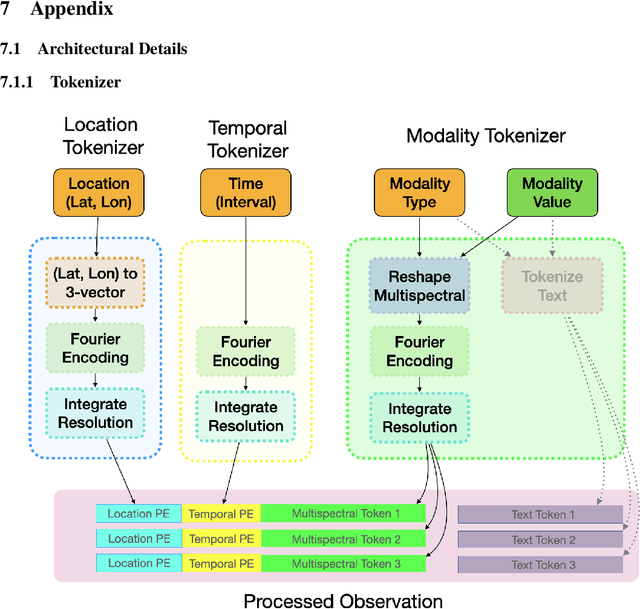
Geospatial Information Systems are used by researchers and Humanitarian Assistance and Disaster Response (HADR) practitioners to support a wide variety of important applications. However, collaboration between these actors is difficult due to the heterogeneous nature of geospatial data modalities (e.g., multi-spectral images of various resolutions, timeseries, weather data) and diversity of tasks (e.g., regression of human activity indicators or detecting forest fires). In this work, we present a roadmap towards the construction of a general-purpose neural architecture (GPNA) with a geospatial inductive bias, pre-trained on large amounts of unlabelled earth observation data in a self-supervised manner. We envision how such a model may facilitate cooperation between members of the community. We show preliminary results on the first step of the roadmap, where we instantiate an architecture that can process a wide variety of geospatial data modalities and demonstrate that it can achieve competitive performance with domain-specific architectures on tasks relating to the U.N.'s Sustainable Development Goals.
DCI-ES: An Extended Disentanglement Framework with Connections to Identifiability
Oct 01, 2022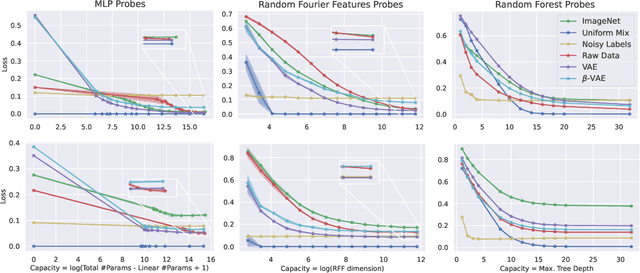
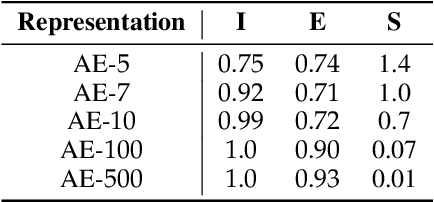
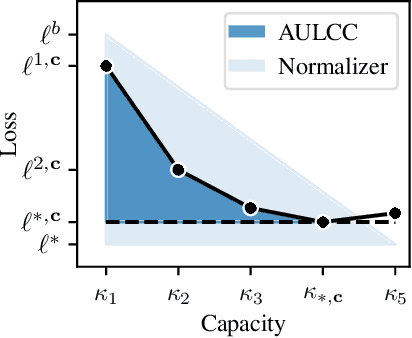
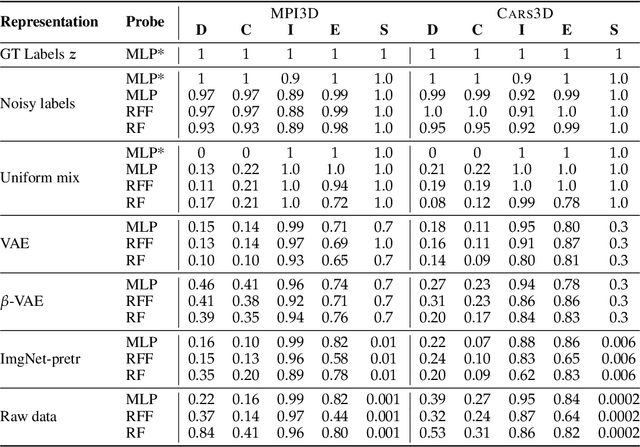
In representation learning, a common approach is to seek representations which disentangle the underlying factors of variation. Eastwood & Williams (2018) proposed three metrics for quantifying the quality of such disentangled representations: disentanglement (D), completeness (C) and informativeness (I). In this work, we first connect this DCI framework to two common notions of linear and nonlinear identifiability, thus establishing a formal link between disentanglement and the closely-related field of independent component analysis. We then propose an extended DCI-ES framework with two new measures of representation quality - explicitness (E) and size (S) - and point out how D and C can be computed for black-box predictors. Our main idea is that the functional capacity required to use a representation is an important but thus-far neglected aspect of representation quality, which we quantify using explicitness or ease-of-use (E). We illustrate the relevance of our extensions on the MPI3D and Cars3D datasets.
Discrete Key-Value Bottleneck
Jul 22, 2022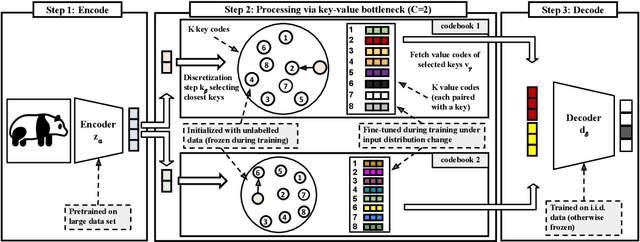
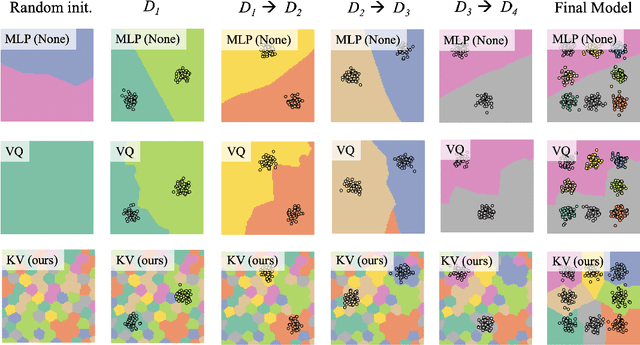

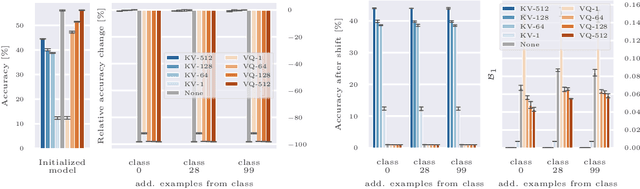
Deep neural networks perform well on prediction and classification tasks in the canonical setting where data streams are i.i.d., labeled data is abundant, and class labels are balanced. Challenges emerge with distribution shifts, including non-stationary or imbalanced data streams. One powerful approach that has addressed this challenge involves self-supervised pretraining of large encoders on volumes of unlabeled data, followed by task-specific tuning. Given a new task, updating the weights of these encoders is challenging as a large number of weights needs to be fine-tuned, and as a result, they forget information about the previous tasks. In the present work, we propose a model architecture to address this issue, building upon a discrete bottleneck containing pairs of separate and learnable (key, value) codes. In this setup, we follow the encode; process the representation via a discrete bottleneck; and decode paradigm, where the input is fed to the pretrained encoder, the output of the encoder is used to select the nearest keys, and the corresponding values are fed to the decoder to solve the current task. The model can only fetch and re-use a limited number of these (key, value) pairs during inference, enabling localized and context-dependent model updates. We theoretically investigate the ability of the proposed model to minimize the effect of the distribution shifts and show that such a discrete bottleneck with (key, value) pairs reduces the complexity of the hypothesis class. We empirically verified the proposed methods' benefits under challenging distribution shift scenarios across various benchmark datasets and show that the proposed model reduces the common vulnerability to non-i.i.d. and non-stationary training distributions compared to various other baselines.
Compositional Multi-Object Reinforcement Learning with Linear Relation Networks
Jan 31, 2022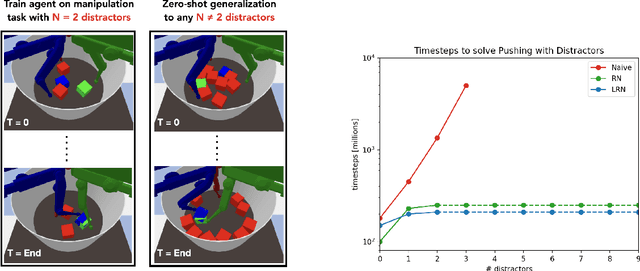

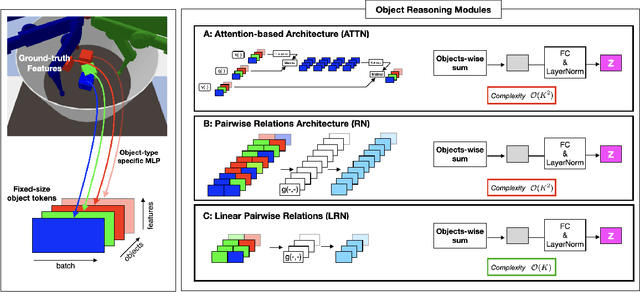
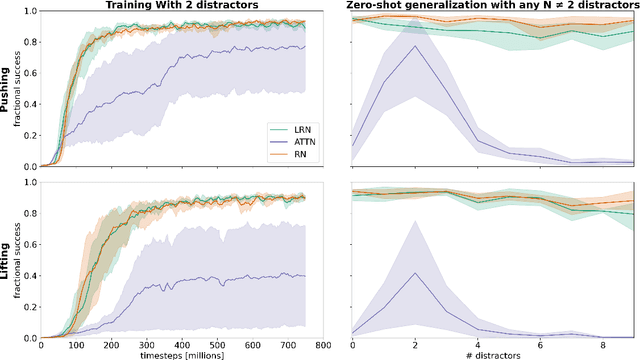
Although reinforcement learning has seen remarkable progress over the last years, solving robust dexterous object-manipulation tasks in multi-object settings remains a challenge. In this paper, we focus on models that can learn manipulation tasks in fixed multi-object settings and extrapolate this skill zero-shot without any drop in performance when the number of objects changes. We consider the generic task of bringing a specific cube out of a set to a goal position. We find that previous approaches, which primarily leverage attention and graph neural network-based architectures, do not generalize their skills when the number of input objects changes while scaling as $K^2$. We propose an alternative plug-and-play module based on relational inductive biases to overcome these limitations. Besides exceeding performances in their training environment, we show that our approach, which scales linearly in $K$, allows agents to extrapolate and generalize zero-shot to any new object number.
Boxhead: A Dataset for Learning Hierarchical Representations
Oct 07, 2021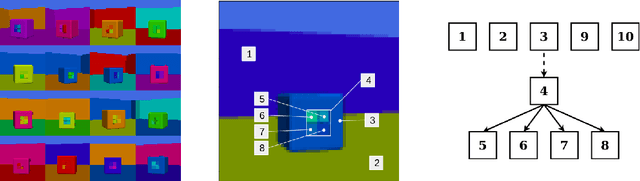

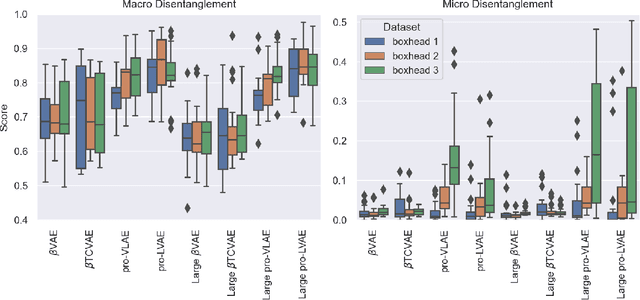

Disentanglement is hypothesized to be beneficial towards a number of downstream tasks. However, a common assumption in learning disentangled representations is that the data generative factors are statistically independent. As current methods are almost solely evaluated on toy datasets where this ideal assumption holds, we investigate their performance in hierarchical settings, a relevant feature of real-world data. In this work, we introduce Boxhead, a dataset with hierarchically structured ground-truth generative factors. We use this novel dataset to evaluate the performance of state-of-the-art autoencoder-based disentanglement models and observe that hierarchical models generally outperform single-layer VAEs in terms of disentanglement of hierarchically arranged factors.
Visual Representation Learning Does Not Generalize Strongly Within the Same Domain
Jul 23, 2021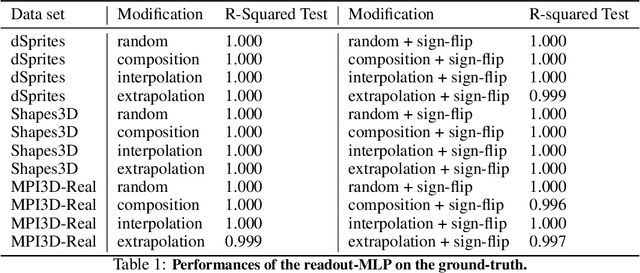



An important component for generalization in machine learning is to uncover underlying latent factors of variation as well as the mechanism through which each factor acts in the world. In this paper, we test whether 17 unsupervised, weakly supervised, and fully supervised representation learning approaches correctly infer the generative factors of variation in simple datasets (dSprites, Shapes3D, MPI3D). In contrast to prior robustness work that introduces novel factors of variation during test time, such as blur or other (un)structured noise, we here recompose, interpolate, or extrapolate only existing factors of variation from the training data set (e.g., small and medium-sized objects during training and large objects during testing). Models that learn the correct mechanism should be able to generalize to this benchmark. In total, we train and test 2000+ models and observe that all of them struggle to learn the underlying mechanism regardless of supervision signal and architectural bias. Moreover, the generalization capabilities of all tested models drop significantly as we move from artificial datasets towards more realistic real-world datasets. Despite their inability to identify the correct mechanism, the models are quite modular as their ability to infer other in-distribution factors remains fairly stable, providing only a single factor is out-of-distribution. These results point to an important yet understudied problem of learning mechanistic models of observations that can facilitate generalization.
Representation Learning for Out-Of-Distribution Generalization in Reinforcement Learning
Jul 12, 2021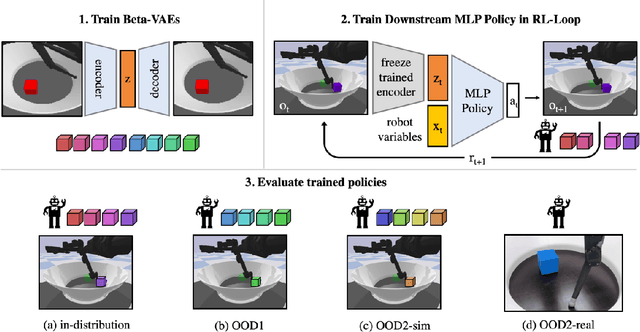
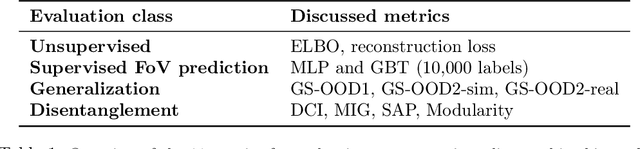
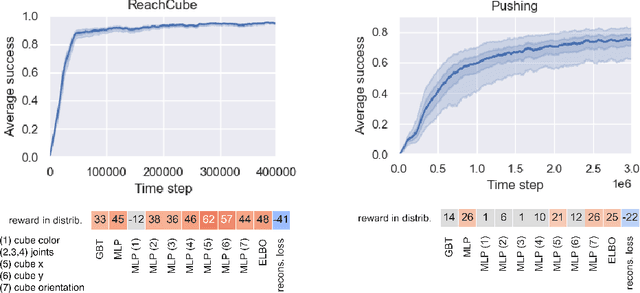
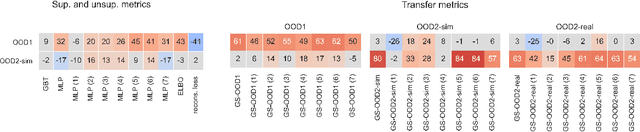
Learning data representations that are useful for various downstream tasks is a cornerstone of artificial intelligence. While existing methods are typically evaluated on downstream tasks such as classification or generative image quality, we propose to assess representations through their usefulness in downstream control tasks, such as reaching or pushing objects. By training over 10,000 reinforcement learning policies, we extensively evaluate to what extent different representation properties affect out-of-distribution (OOD) generalization. Finally, we demonstrate zero-shot transfer of these policies from simulation to the real world, without any domain randomization or fine-tuning. This paper aims to establish the first systematic characterization of the usefulness of learned representations for real-world OOD downstream tasks.