 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding Vision and Language to 3D Masks for Long-Horizon Box Rearrangement
Mar 24, 2026We study long-horizon planning in 3D environments from under-specified natural-language goals using only visual observations, focusing on multi-step 3D box rearrangement tasks. Existing approaches typically rely on symbolic planners with brittle relational grounding of states and goals, or on direct action-sequence generation from 2D vision-language models (VLMs). Both approaches struggle with reasoning over many objects, rich 3D geometry, and implicit semantic constraints. Recent advances in 3D VLMs demonstrate strong grounding of natural-language referents to 3D segmentation masks, suggesting the potential for more general planning capabilities. We extend existing 3D grounding models and propose Reactive Action Mask Planner (RAMP-3D), which formulates long-horizon planning as sequential reactive prediction of paired 3D masks: a "which-object" mask indicating what to pick and a "which-target-region" mask specifying where to place it. The resulting system processes RGB-D observations and natural-language task specifications to reactively generate multi-step pick-and-place actions for 3D box rearrangement. We conduct experiments across 11 task variants in warehouse-style environments with 1-30 boxes and diverse natural-language constraints. RAMP-3D achieves 79.5% success rate on long-horizon rearrangement tasks and significantly outperforms 2D VLM-based baselines, establishing mask-based reactive policies as a promising alternative to symbolic pipelines for long-horizon planning.
Unlearning via Sparse Representations
Nov 26, 2023Machine \emph{unlearning}, which involves erasing knowledge about a \emph{forget set} from a trained model, can prove to be costly and infeasible by existing techniques. We propose a nearly compute-free zero-shot unlearning technique based on a discrete representational bottleneck. We show that the proposed technique efficiently unlearns the forget set and incurs negligible damage to the model's performance on the rest of the data set. We evaluate the proposed technique on the problem of \textit{class unlearning} using three datasets: CIFAR-10, CIFAR-100, and LACUNA-100. We compare the proposed technique to SCRUB, a state-of-the-art approach which uses knowledge distillation for unlearning. Across all three datasets, the proposed technique performs as well as, if not better than SCRUB while incurring almost no computational cost.
Learning Dynamic Bipedal Walking Across Stepping Stones
May 03, 2022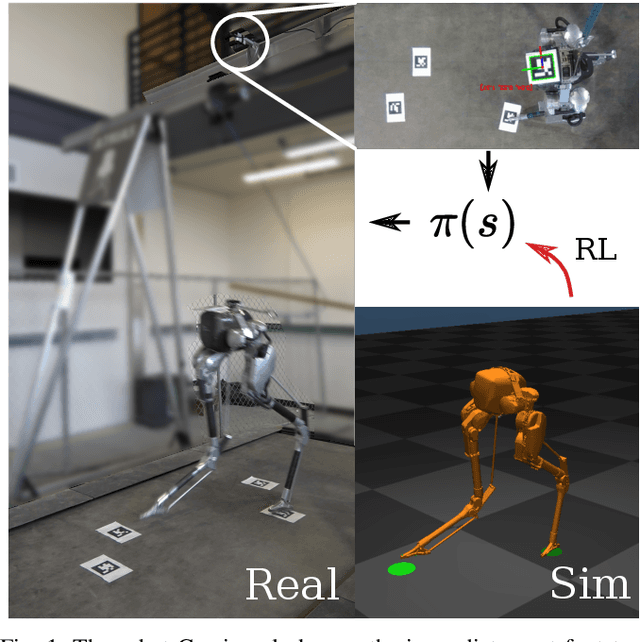
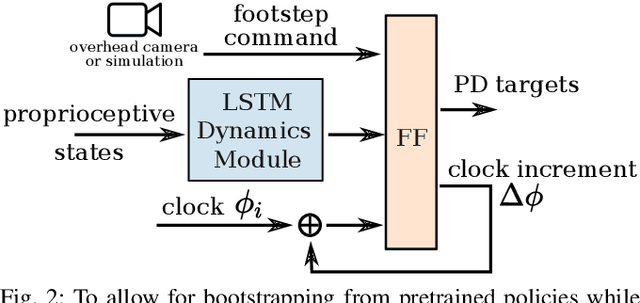
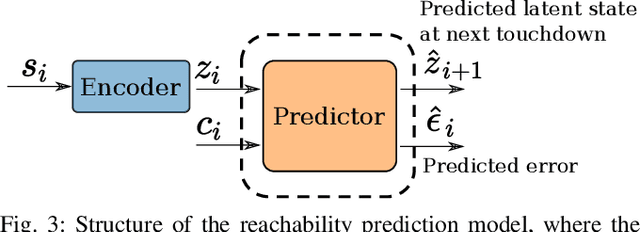
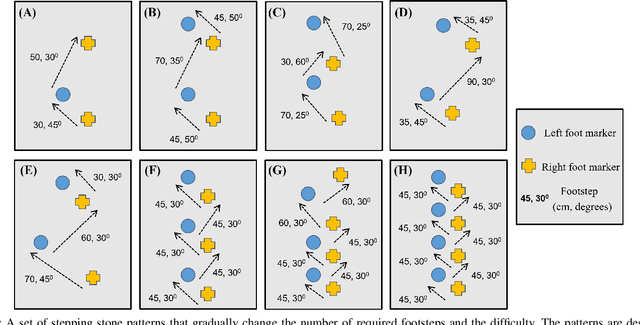
In this work, we propose a learning approach for 3D dynamic bipedal walking when footsteps are constrained to stepping stones. While recent work has shown progress on this problem, real-world demonstrations have been limited to relatively simple open-loop, perception-free scenarios. Our main contribution is a more advanced learning approach that enables real-world demonstrations, using the Cassie robot, of closed-loop dynamic walking over moderately difficult stepping-stone patterns. Our approach first uses reinforcement learning (RL) in simulation to train a controller that maps footstep commands onto joint actions without any reference motion information. We then learn a model of that controller's capabilities, which enables prediction of feasible footsteps given the robot's current dynamic state. The resulting controller and model are then integrated with a real-time overhead camera system for detecting stepping stone locations. For evaluation, we develop a benchmark set of stepping stone patterns, which are used to test performance in both simulation and the real world. Overall, we demonstrate that sim-to-real learning is extremely promising for enabling dynamic locomotion over stepping stones. We also identify challenges remaining that motivate important future research directions.
Sim-to-Real Learning of Footstep-Constrained Bipedal Dynamic Walking
Mar 15, 2022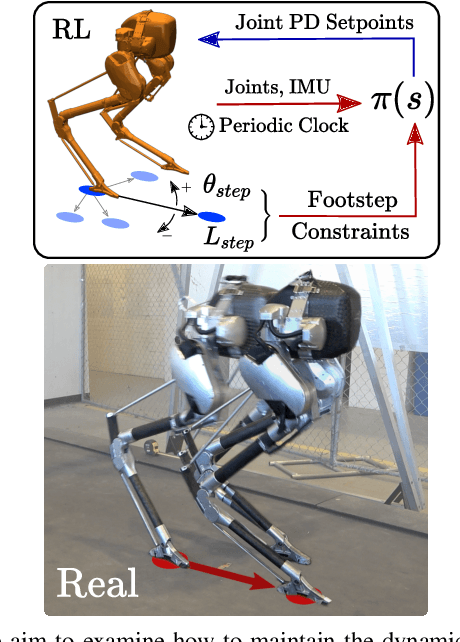
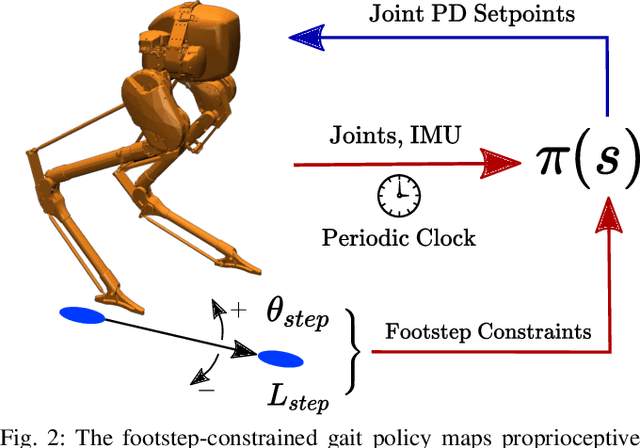
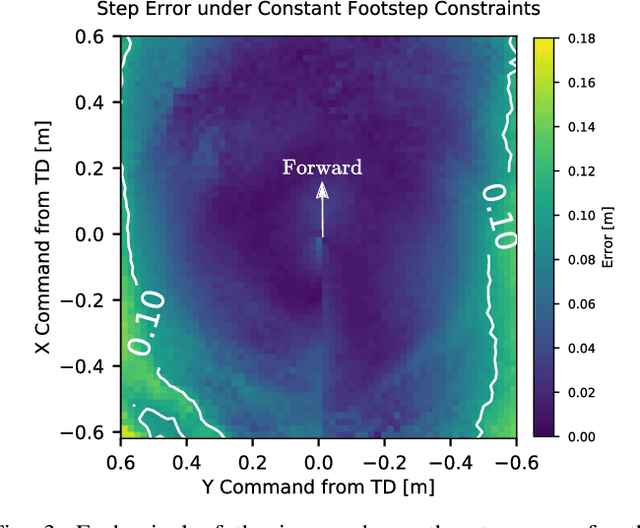
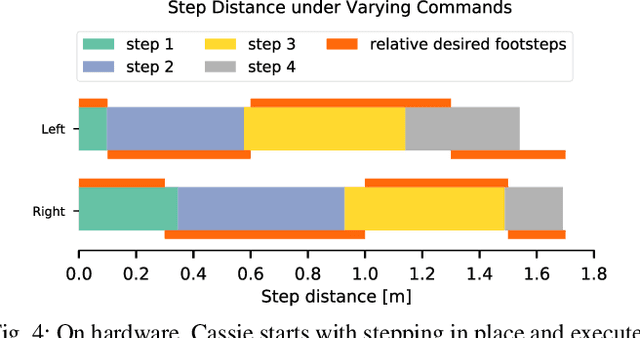
Recently, work on reinforcement learning (RL) for bipedal robots has successfully learned controllers for a variety of dynamic gaits with robust sim-to-real demonstrations. In order to maintain balance, the learned controllers have full freedom of where to place the feet, resulting in highly robust gaits. In the real world however, the environment will often impose constraints on the feasible footstep locations, typically identified by perception systems. Unfortunately, most demonstrated RL controllers on bipedal robots do not allow for specifying and responding to such constraints. This missing control interface greatly limits the real-world application of current RL controllers. In this paper, we aim to maintain the robust and dynamic nature of learned gaits while also respecting footstep constraints imposed externally. We develop an RL formulation for training dynamic gait controllers that can respond to specified touchdown locations. We then successfully demonstrate simulation and sim-to-real performance on the bipedal robot Cassie. In addition, we use supervised learning to induce a transition model for accurately predicting the next touchdown locations that the controller can achieve given the robot's proprioceptive observations. This model paves the way for integrating the learned controller into a full-order robot locomotion planner that robustly satisfies both balance and environmental constraints.
Zero-shot generalization using cascaded system-representations
Dec 11, 2019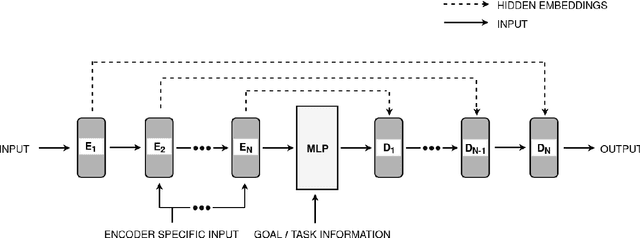
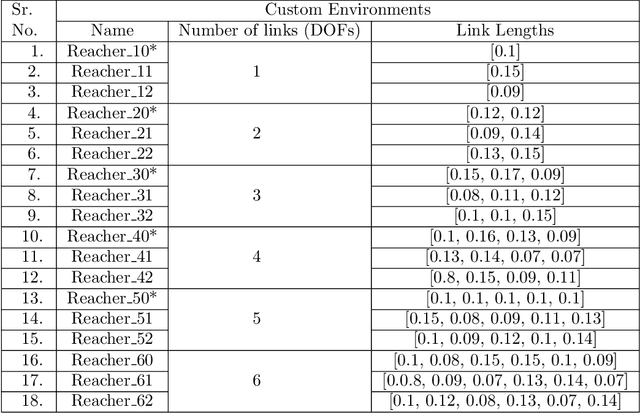
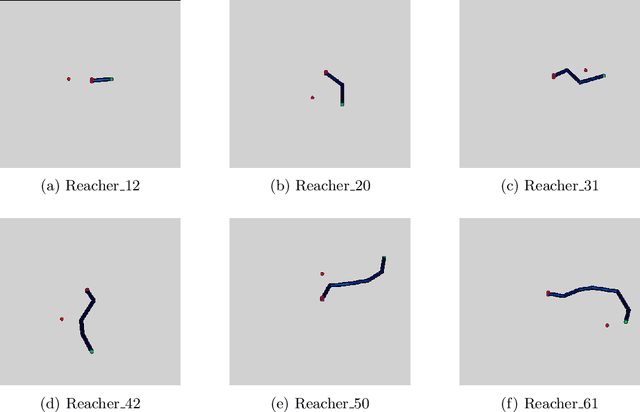
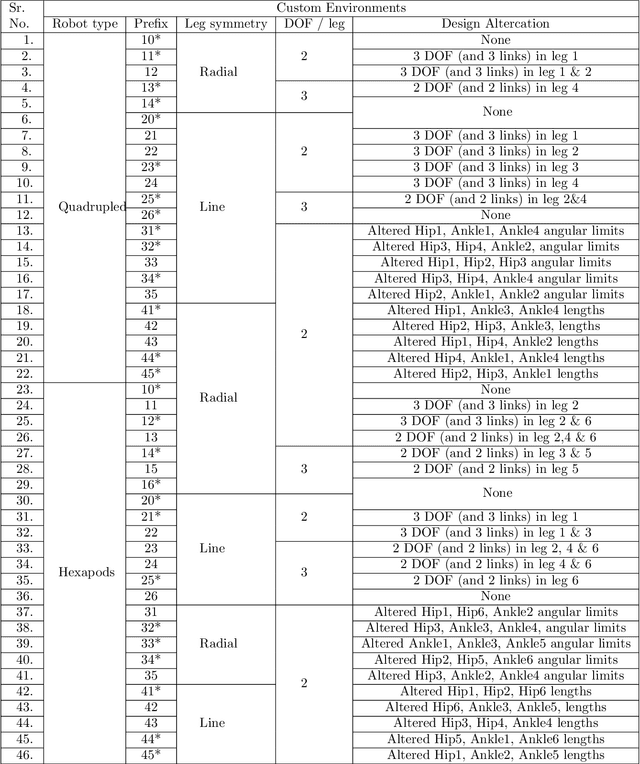
This paper proposes a new framework named CASNET to learn control policies that generalize over similar robot types with different morphologies. The proposed framework leverages the structural similarities in robots to learn general-purpose system-representations. These representations can then be used with the choice of learning algorithms to learn policies that generalize over different robots. The learned policies can be used to design general-purpose robot-controllers that are applicable to a wide variety of robots. We demonstrate the effectiveness of the proposed framework by learning control policies for two separate domains: planer manipulation and legged locomotion. The policy learned for planer manipulation is capable of controlling planer manipulators with varying degrees of freedom and link-lengths. For legged locomotion, the learned policy generalizes over different morphologies of the crawling robots. These policies perform on-par with the expert policies trained for individual robot models and achieves zero-shot generalization on models unseen during training, establishing that the final performance of the general policy is bottlenecked by the learning algorithm rather than the proposed framework.