 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Real-World Datasets Contain Natural Experiments? An Empirical Study Using Causal Feature Selection
Jun 02, 2026In nature, events that affect some individuals or groups but not others constitute an implicit intervention and are known as natural experiments. For example, the COVID-19 pandemic was an intervention by the coronavirus on the sub-population infected with COVID. We ask, do natural experiments occur in existing real-world datasets? If yes, how should we treat them? To detect natural experiments in data, we use causal discovery to recover the underlying causal graph and perform feature selection based on causal links. If downstream performance improves by treating the data as interventional rather than observational, we argue that this suggests the dataset contains natural experiments. We first validate this hypothesis by simulating datasets with and without natural experiments using synthetic graphs. We then perform a systematic empirical evaluation on a large suite of real-world datasets. Our results indicate that real-world datasets do contain natural experiments and we can take advantage of those natural experiments to improve model performance using causal inference. Our work represents the initial foray into this area, offering a preliminary exploration within a limited scope.
Can foundation models actively gather information in interactive environments to test hypotheses?
Dec 09, 2024



While problem solving is a standard evaluation task for foundation models, a crucial component of problem solving -- actively and strategically gathering information to test hypotheses -- has not been closely investigated. To assess the information gathering abilities of foundation models in interactive environments, we introduce a framework in which a model must determine the factors influencing a hidden reward function by iteratively reasoning about its previously gathered information and proposing its next exploratory action to maximize information gain at each step. We implement this framework in both a text-based environment, which offers a tightly controlled setting and enables high-throughput parameter sweeps, and in an embodied 3D environment, which requires addressing complexities of multi-modal interaction more relevant to real-world applications. We further investigate whether approaches such as self-correction and increased inference time improve information gathering efficiency. In a relatively simple task that requires identifying a single rewarding feature, we find that LLM's information gathering capability is close to optimal. However, when the model must identify a conjunction of rewarding features, performance is suboptimal. The hit in performance is due partly to the model translating task description to a policy and partly to the model's effectiveness in using its in-context memory. Performance is comparable in both text and 3D embodied environments, although imperfect visual object recognition reduces its accuracy in drawing conclusions from gathered information in the 3D embodied case. For single-feature-based rewards, we find that smaller models curiously perform better; for conjunction-based rewards, incorporating self correction into the model improves performance.
Racing Thoughts: Explaining Large Language Model Contextualization Errors
Oct 02, 2024



The profound success of transformer-based language models can largely be attributed to their ability to integrate relevant contextual information from an input sequence in order to generate a response or complete a task. However, we know very little about the algorithms that a model employs to implement this capability, nor do we understand their failure modes. For example, given the prompt "John is going fishing, so he walks over to the bank. Can he make an ATM transaction?", a model may incorrectly respond "Yes" if it has not properly contextualized "bank" as a geographical feature, rather than a financial institution. We propose the LLM Race Conditions Hypothesis as an explanation of contextualization errors of this form. This hypothesis identifies dependencies between tokens (e.g., "bank" must be properly contextualized before the final token, "?", integrates information from "bank"), and claims that contextualization errors are a result of violating these dependencies. Using a variety of techniques from mechanistic intepretability, we provide correlational and causal evidence in support of the hypothesis, and suggest inference-time interventions to address it.
AI-Assisted Generation of Difficult Math Questions
Jul 30, 2024



Current LLM training positions mathematical reasoning as a core capability. With publicly available sources fully tapped, there is unmet demand for diverse and challenging math questions. Relying solely on human experts is both time-consuming and costly, while LLM-generated questions often lack the requisite diversity and difficulty. We present a design framework that combines the strengths of LLMs with a human-in-the-loop approach to generate a diverse array of challenging math questions. We leverage LLM metacognition skills [Didolkar et al., 2024] of a strong LLM to extract core "skills" from existing math datasets. These skills serve as the basis for generating novel and difficult questions by prompting the LLM with random pairs of core skills. The use of two different skills within each question makes finding such questions an "out of distribution" task for both LLMs and humans. Our pipeline employs LLMs to iteratively generate and refine questions and solutions through multiturn prompting. Human annotators then verify and further refine the questions, with their efficiency enhanced via further LLM interactions. Applying this pipeline on skills extracted from the MATH dataset [Hendrycks et al., 2021] resulted in MATH$^2$ - a dataset of higher-quality math questions, as evidenced by: (a) Lower performance of all models on MATH$^2$ than on MATH (b) Higher performance on MATH when using MATH$^2$ questions as in-context examples. Although focused on mathematics, our methodology seems applicable to other domains requiring structured reasoning, and potentially as a component of scalable oversight. Also of interest is a striking relationship observed between models' performance on the new dataset: the success rate on MATH$^2$ is the square on MATH, suggesting that successfully solving the question in MATH$^2$ requires a nontrivial combination of two distinct math skills.
Metacognitive Capabilities of LLMs: An Exploration in Mathematical Problem Solving
May 20, 2024



Metacognitive knowledge refers to humans' intuitive knowledge of their own thinking and reasoning processes. Today's best LLMs clearly possess some reasoning processes. The paper gives evidence that they also have metacognitive knowledge, including ability to name skills and procedures to apply given a task. We explore this primarily in context of math reasoning, developing a prompt-guided interaction procedure to get a powerful LLM to assign sensible skill labels to math questions, followed by having it perform semantic clustering to obtain coarser families of skill labels. These coarse skill labels look interpretable to humans. To validate that these skill labels are meaningful and relevant to the LLM's reasoning processes we perform the following experiments. (a) We ask GPT-4 to assign skill labels to training questions in math datasets GSM8K and MATH. (b) When using an LLM to solve the test questions, we present it with the full list of skill labels and ask it to identify the skill needed. Then it is presented with randomly selected exemplar solved questions associated with that skill label. This improves accuracy on GSM8k and MATH for several strong LLMs, including code-assisted models. The methodology presented is domain-agnostic, even though this article applies it to math problems.
Can AI Be as Creative as Humans?
Jan 12, 2024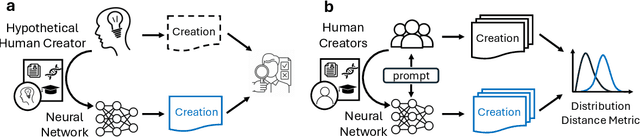
Creativity serves as a cornerstone for societal progress and innovation. With the rise of advanced generative AI models capable of tasks once reserved for human creativity, the study of AI's creative potential becomes imperative for its responsible development and application. In this paper, we provide a theoretical answer to the question of whether AI can be creative. We prove in theory that AI can be as creative as humans under the condition that AI can fit the existing data generated by human creators. Therefore, the debate on AI's creativity is reduced into the question of its ability of fitting a massive amount of data. To arrive at this conclusion, this paper first addresses the complexities in defining creativity by introducing a new concept called Relative Creativity. Instead of trying to define creativity universally, we shift the focus to whether AI can match the creative abilities of a hypothetical human. This perspective draws inspiration from the Turing Test, expanding upon it to address the challenges and subjectivities inherent in assessing creativity. This methodological shift leads to a statistically quantifiable assessment of AI's creativity, which we term Statistical Creativity. This concept allows for comparisons of AI's creative abilities with those of specific human groups, and facilitates the theoretical findings of AI's creative potential. Building on this foundation, we discuss the application of statistical creativity in prompt-conditioned autoregressive models, providing a practical means for evaluating creative abilities of contemporary AI models, such as Large Language Models (LLMs). In addition to defining and analyzing creativity, we introduce an actionable training guideline, effectively bridging the gap between theoretical quantification of creativity and practical model training.
Unlearning via Sparse Representations
Nov 26, 2023Machine \emph{unlearning}, which involves erasing knowledge about a \emph{forget set} from a trained model, can prove to be costly and infeasible by existing techniques. We propose a nearly compute-free zero-shot unlearning technique based on a discrete representational bottleneck. We show that the proposed technique efficiently unlearns the forget set and incurs negligible damage to the model's performance on the rest of the data set. We evaluate the proposed technique on the problem of \textit{class unlearning} using three datasets: CIFAR-10, CIFAR-100, and LACUNA-100. We compare the proposed technique to SCRUB, a state-of-the-art approach which uses knowledge distillation for unlearning. Across all three datasets, the proposed technique performs as well as, if not better than SCRUB while incurring almost no computational cost.
Leveraging the Third Dimension in Contrastive Learning
Jan 27, 2023
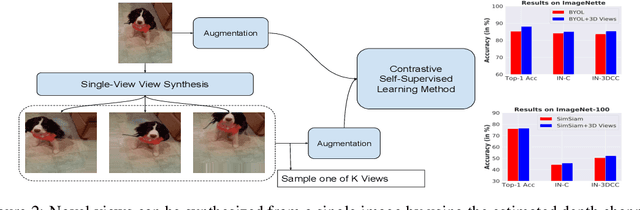


Self-Supervised Learning (SSL) methods operate on unlabeled data to learn robust representations useful for downstream tasks. Most SSL methods rely on augmentations obtained by transforming the 2D image pixel map. These augmentations ignore the fact that biological vision takes place in an immersive three-dimensional, temporally contiguous environment, and that low-level biological vision relies heavily on depth cues. Using a signal provided by a pretrained state-of-the-art monocular RGB-to-depth model (the \emph{Depth Prediction Transformer}, Ranftl et al., 2021), we explore two distinct approaches to incorporating depth signals into the SSL framework. First, we evaluate contrastive learning using an RGB+depth input representation. Second, we use the depth signal to generate novel views from slightly different camera positions, thereby producing a 3D augmentation for contrastive learning. We evaluate these two approaches on three different SSL methods -- BYOL, SimSiam, and SwAV -- using ImageNette (10 class subset of ImageNet), ImageNet-100 and ImageNet-1k datasets. We find that both approaches to incorporating depth signals improve the robustness and generalization of the baseline SSL methods, though the first approach (with depth-channel concatenation) is superior. For instance, BYOL with the additional depth channel leads to an increase in downstream classification accuracy from 85.3\% to 88.0\% on ImageNette and 84.1\% to 87.0\% on ImageNet-C.
Stateful active facilitator: Coordination and Environmental Heterogeneity in Cooperative Multi-Agent Reinforcement Learning
Oct 07, 2022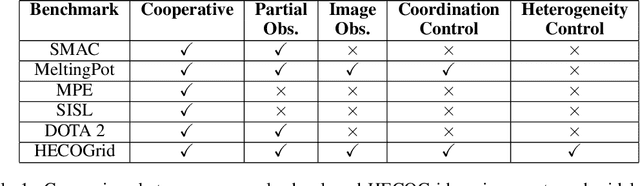

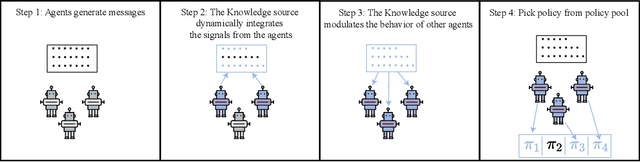
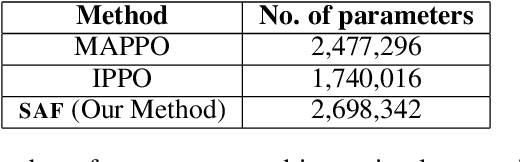
In cooperative multi-agent reinforcement learning, a team of agents works together to achieve a common goal. Different environments or tasks may require varying degrees of coordination among agents in order to achieve the goal in an optimal way. The nature of coordination will depend on properties of the environment -- its spatial layout, distribution of obstacles, dynamics, etc. We term this variation of properties within an environment as heterogeneity. Existing literature has not sufficiently addressed the fact that different environments may have different levels of heterogeneity. We formalize the notions of coordination level and heterogeneity level of an environment and present HECOGrid, a suite of multi-agent RL environments that facilitates empirical evaluation of different MARL approaches across different levels of coordination and environmental heterogeneity by providing a quantitative control over coordination and heterogeneity levels of the environment. Further, we propose a Centralized Training Decentralized Execution learning approach called Stateful Active Facilitator (SAF) that enables agents to work efficiently in high-coordination and high-heterogeneity environments through a differentiable and shared knowledge source used during training and dynamic selection from a shared pool of policies. We evaluate SAF and compare its performance against baselines IPPO and MAPPO on HECOGrid. Our results show that SAF consistently outperforms the baselines across different tasks and different heterogeneity and coordination levels.
Discrete Key-Value Bottleneck
Jul 22, 2022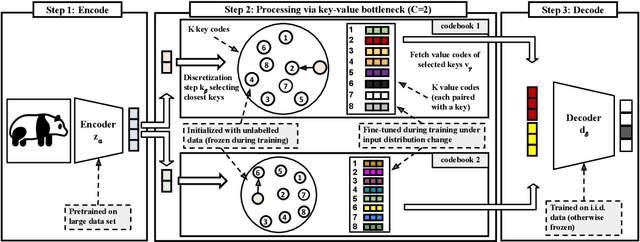
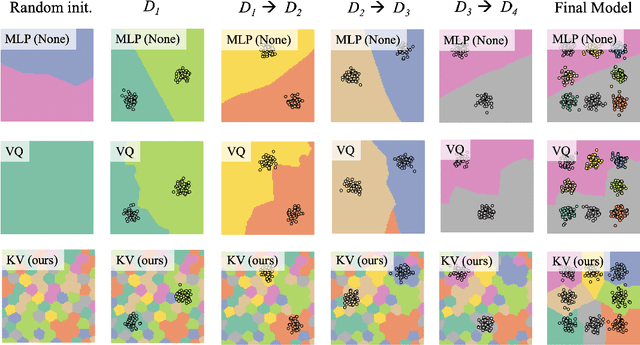

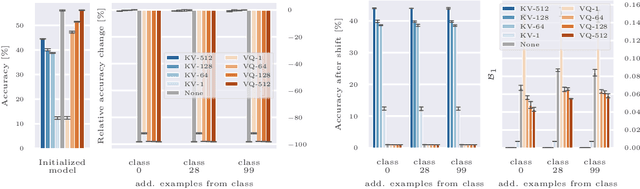
Deep neural networks perform well on prediction and classification tasks in the canonical setting where data streams are i.i.d., labeled data is abundant, and class labels are balanced. Challenges emerge with distribution shifts, including non-stationary or imbalanced data streams. One powerful approach that has addressed this challenge involves self-supervised pretraining of large encoders on volumes of unlabeled data, followed by task-specific tuning. Given a new task, updating the weights of these encoders is challenging as a large number of weights needs to be fine-tuned, and as a result, they forget information about the previous tasks. In the present work, we propose a model architecture to address this issue, building upon a discrete bottleneck containing pairs of separate and learnable (key, value) codes. In this setup, we follow the encode; process the representation via a discrete bottleneck; and decode paradigm, where the input is fed to the pretrained encoder, the output of the encoder is used to select the nearest keys, and the corresponding values are fed to the decoder to solve the current task. The model can only fetch and re-use a limited number of these (key, value) pairs during inference, enabling localized and context-dependent model updates. We theoretically investigate the ability of the proposed model to minimize the effect of the distribution shifts and show that such a discrete bottleneck with (key, value) pairs reduces the complexity of the hypothesis class. We empirically verified the proposed methods' benefits under challenging distribution shift scenarios across various benchmark datasets and show that the proposed model reduces the common vulnerability to non-i.i.d. and non-stationary training distributions compared to various other baselines.