 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction abstractions for amortized sampling
Oct 19, 2024As trajectories sampled by policies used by reinforcement learning (RL) and generative flow networks (GFlowNets) grow longer, credit assignment and exploration become more challenging, and the long planning horizon hinders mode discovery and generalization. The challenge is particularly pronounced in entropy-seeking RL methods, such as generative flow networks, where the agent must learn to sample from a structured distribution and discover multiple high-reward states, each of which take many steps to reach. To tackle this challenge, we propose an approach to incorporate the discovery of action abstractions, or high-level actions, into the policy optimization process. Our approach involves iteratively extracting action subsequences commonly used across many high-reward trajectories and `chunking' them into a single action that is added to the action space. In empirical evaluation on synthetic and real-world environments, our approach demonstrates improved sample efficiency performance in discovering diverse high-reward objects, especially on harder exploration problems. We also observe that the abstracted high-order actions are interpretable, capturing the latent structure of the reward landscape of the action space. This work provides a cognitively motivated approach to action abstraction in RL and is the first demonstration of hierarchical planning in amortized sequential sampling.
What if We Enrich day-ahead Solar Irradiance Time Series Forecasting with Spatio-Temporal Context?
Jun 01, 2023



Solar power harbors immense potential in mitigating climate change by substantially reducing CO$_{2}$ emissions. Nonetheless, the inherent variability of solar irradiance poses a significant challenge for seamlessly integrating solar power into the electrical grid. While the majority of prior research has centered on employing purely time series-based methodologies for solar forecasting, only a limited number of studies have taken into account factors such as cloud cover or the surrounding physical context. In this paper, we put forth a deep learning architecture designed to harness spatio-temporal context using satellite data, to attain highly accurate \textit{day-ahead} time-series forecasting for any given station, with a particular emphasis on forecasting Global Horizontal Irradiance (GHI). We also suggest a methodology to extract a distribution for each time step prediction, which can serve as a very valuable measure of uncertainty attached to the forecast. When evaluating models, we propose a testing scheme in which we separate particularly difficult examples from easy ones, in order to capture the model performances in crucial situations, which in the case of this study are the days suffering from varying cloudy conditions. Furthermore, we present a new multi-modal dataset gathering satellite imagery over a large zone and time series for solar irradiance and other related physical variables from multiple geographically diverse solar stations. Our approach exhibits robust performance in solar irradiance forecasting, including zero-shot generalization tests at unobserved solar stations, and holds great promise in promoting the effective integration of solar power into the grid.
MAgNet: Mesh Agnostic Neural PDE Solver
Oct 11, 2022



The computational complexity of classical numerical methods for solving Partial Differential Equations (PDE) scales significantly as the resolution increases. As an important example, climate predictions require fine spatio-temporal resolutions to resolve all turbulent scales in the fluid simulations. This makes the task of accurately resolving these scales computationally out of reach even with modern supercomputers. As a result, current numerical modelers solve PDEs on grids that are too coarse (3km to 200km on each side), which hinders the accuracy and usefulness of the predictions. In this paper, we leverage the recent advances in Implicit Neural Representations (INR) to design a novel architecture that predicts the spatially continuous solution of a PDE given a spatial position query. By augmenting coordinate-based architectures with Graph Neural Networks (GNN), we enable zero-shot generalization to new non-uniform meshes and long-term predictions up to 250 frames ahead that are physically consistent. Our Mesh Agnostic Neural PDE Solver (MAgNet) is able to make accurate predictions across a variety of PDE simulation datasets and compares favorably with existing baselines. Moreover, MAgNet generalizes well to different meshes and resolutions up to four times those trained on.
Stateful active facilitator: Coordination and Environmental Heterogeneity in Cooperative Multi-Agent Reinforcement Learning
Oct 07, 2022

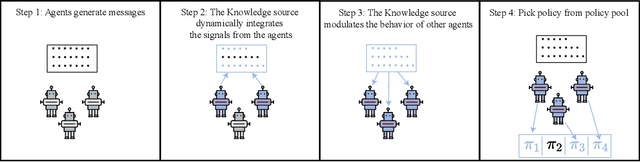
In cooperative multi-agent reinforcement learning, a team of agents works together to achieve a common goal. Different environments or tasks may require varying degrees of coordination among agents in order to achieve the goal in an optimal way. The nature of coordination will depend on properties of the environment -- its spatial layout, distribution of obstacles, dynamics, etc. We term this variation of properties within an environment as heterogeneity. Existing literature has not sufficiently addressed the fact that different environments may have different levels of heterogeneity. We formalize the notions of coordination level and heterogeneity level of an environment and present HECOGrid, a suite of multi-agent RL environments that facilitates empirical evaluation of different MARL approaches across different levels of coordination and environmental heterogeneity by providing a quantitative control over coordination and heterogeneity levels of the environment. Further, we propose a Centralized Training Decentralized Execution learning approach called Stateful Active Facilitator (SAF) that enables agents to work efficiently in high-coordination and high-heterogeneity environments through a differentiable and shared knowledge source used during training and dynamic selection from a shared pool of policies. We evaluate SAF and compare its performance against baselines IPPO and MAPPO on HECOGrid. Our results show that SAF consistently outperforms the baselines across different tasks and different heterogeneity and coordination levels.
Coordinating Policies Among Multiple Agents via an Intelligent Communication Channel
May 25, 2022

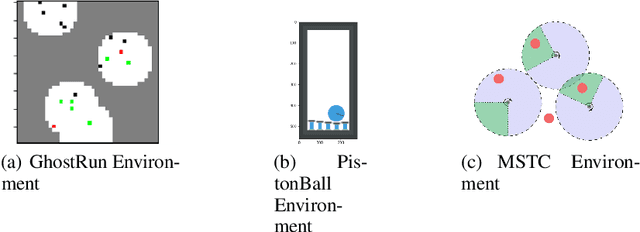

In Multi-Agent Reinforcement Learning (MARL), specialized channels are often introduced that allow agents to communicate directly with one another. In this paper, we propose an alternative approach whereby agents communicate through an intelligent facilitator that learns to sift through and interpret signals provided by all agents to improve the agents' collective performance. To ensure that this facilitator does not become a centralized controller, agents are incentivized to reduce their dependence on the messages it conveys, and the messages can only influence the selection of a policy from a fixed set, not instantaneous actions given the policy. We demonstrate the strength of this architecture over existing baselines on several cooperative MARL environments.