 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval, Refinement, and Ranking for Text-to-Video Generation via Prompt Optimization and Test-Time Scaling
Mar 02, 2026While large-scale datasets have driven significant progress in Text-to-Video (T2V) generative models, these models remain highly sensitive to input prompts, demonstrating that prompt design is critical to generation quality. Current methods for improving video output often fall short: they either depend on complex, post-editing models, risking the introduction of artifacts, or require expensive fine-tuning of the core generator, which severely limits both scalability and accessibility. In this work, we introduce 3R, a novel RAG based prompt optimization framework. 3R utilizes the power of current state-of-the-art T2V diffusion model and vision language model. It can be used with any T2V model without any kind of model training. The framework leverages three key strategies: RAG-based modifiers extraction for enriched contextual grounding, diffusion-based Preference Optimization for aligning outputs with human preferences, and temporal frame interpolation for producing temporally consistent visual contents. Together, these components enable more accurate, efficient, and contextually aligned text-to-video generation. Experimental results demonstrate the efficacy of 3R in enhancing the static fidelity and dynamic coherence of generated videos, underscoring the importance of optimizing user prompts.
ROSER: Few-Shot Robotic Sequence Retrieval for Scalable Robot Learning
Mar 02, 2026A critical bottleneck in robot learning is the scarcity of task-labeled, segmented training data, despite the abundance of large-scale robotic datasets recorded as long, continuous interaction logs. Existing datasets contain vast amounts of diverse behaviors, yet remain structurally incompatible with modern learning frameworks that require cleanly segmented, task-specific trajectories. We address this data utilization crisis by formalizing robotic sequence retrieval: the task of extracting reusable, task-centric segments from unlabeled logs using only a few reference examples. We introduce ROSER, a lightweight few-shot retrieval framework that learns task-agnostic metric spaces over temporal windows, enabling accurate retrieval with as few as 3-5 demonstrations, without any task-specific training required. To validate our approach, we establish comprehensive evaluation protocols and benchmark ROSER against classical alignment methods, learned embeddings, and language model baselines across three large-scale datasets (e.g., LIBERO, DROID, and nuScenes). Our experiments demonstrate that ROSER consistently outperforms all prior methods in both accuracy and efficiency, achieving sub-millisecond per-match inference while maintaining superior distributional alignment. By reframing data curation as few-shot retrieval, ROSER provides a practical pathway to unlock underutilized robotic datasets, fundamentally improving data availability for robot learning.
Grounding Foundational Vision Models with 3D Human Poses for Robust Action Recognition
Nov 06, 2025For embodied agents to effectively understand and interact within the world around them, they require a nuanced comprehension of human actions grounded in physical space. Current action recognition models, often relying on RGB video, learn superficial correlations between patterns and action labels, so they struggle to capture underlying physical interaction dynamics and human poses in complex scenes. We propose a model architecture that grounds action recognition in physical space by fusing two powerful, complementary representations: V-JEPA 2's contextual, predictive world dynamics and CoMotion's explicit, occlusion-tolerant human pose data. Our model is validated on both the InHARD and UCF-19-Y-OCC benchmarks for general action recognition and high-occlusion action recognition, respectively. Our model outperforms three other baselines, especially within complex, occlusive scenes. Our findings emphasize a need for action recognition to be supported by spatial understanding instead of statistical pattern recognition.
$α$-TCVAE: On the relationship between Disentanglement and Diversity
Nov 01, 2024While disentangled representations have shown promise in generative modeling and representation learning, their downstream usefulness remains debated. Recent studies re-defined disentanglement through a formal connection to symmetries, emphasizing the ability to reduce latent domains and consequently enhance generative capabilities. However, from an information theory viewpoint, assigning a complex attribute to a specific latent variable may be infeasible, limiting the applicability of disentangled representations to simple datasets. In this work, we introduce $\alpha$-TCVAE, a variational autoencoder optimized using a novel total correlation (TC) lower bound that maximizes disentanglement and latent variables informativeness. The proposed TC bound is grounded in information theory constructs, generalizes the $\beta$-VAE lower bound, and can be reduced to a convex combination of the known variational information bottleneck (VIB) and conditional entropy bottleneck (CEB) terms. Moreover, we present quantitative analyses that support the idea that disentangled representations lead to better generative capabilities and diversity. Additionally, we perform downstream task experiments from both representation and RL domains to assess our questions from a broader ML perspective. Our results demonstrate that $\alpha$-TCVAE consistently learns more disentangled representations than baselines and generates more diverse observations without sacrificing visual fidelity. Notably, $\alpha$-TCVAE exhibits marked improvements on MPI3D-Real, the most realistic disentangled dataset in our study, confirming its ability to represent complex datasets when maximizing the informativeness of individual variables. Finally, testing the proposed model off-the-shelf on a state-of-the-art model-based RL agent, Director, significantly shows $\alpha$-TCVAE downstream usefulness on the loconav Ant Maze task.
Object-Centric Temporal Consistency via Conditional Autoregressive Inductive Biases
Oct 21, 2024



Unsupervised object-centric learning from videos is a promising approach towards learning compositional representations that can be applied to various downstream tasks, such as prediction and reasoning. Recently, it was shown that pretrained Vision Transformers (ViTs) can be useful to learn object-centric representations on real-world video datasets. However, while these approaches succeed at extracting objects from the scenes, the slot-based representations fail to maintain temporal consistency across consecutive frames in a video, i.e. the mapping of objects to slots changes across the video. To address this, we introduce Conditional Autoregressive Slot Attention (CA-SA), a framework that enhances the temporal consistency of extracted object-centric representations in video-centric vision tasks. Leveraging an autoregressive prior network to condition representations on previous timesteps and a novel consistency loss function, CA-SA predicts future slot representations and imposes consistency across frames. We present qualitative and quantitative results showing that our proposed method outperforms the considered baselines on downstream tasks, such as video prediction and visual question-answering tasks.
Masked Generative Priors Improve World Models Sequence Modelling Capabilities
Oct 10, 2024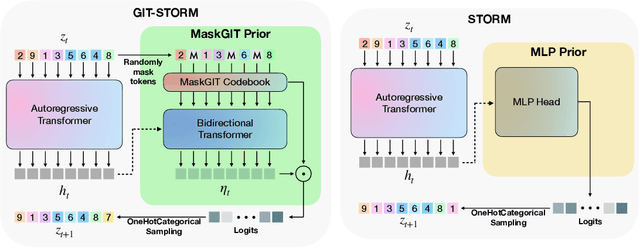


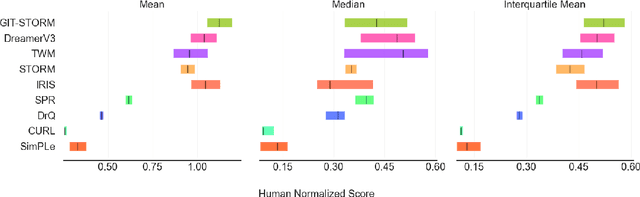
Deep Reinforcement Learning (RL) has become the leading approach for creating artificial agents in complex environments. Model-based approaches, which are RL methods with world models that predict environment dynamics, are among the most promising directions for improving data efficiency, forming a critical step toward bridging the gap between research and real-world deployment. In particular, world models enhance sample efficiency by learning in imagination, which involves training a generative sequence model of the environment in a self-supervised manner. Recently, Masked Generative Modelling has emerged as a more efficient and superior inductive bias for modelling and generating token sequences. Building on the Efficient Stochastic Transformer-based World Models (STORM) architecture, we replace the traditional MLP prior with a Masked Generative Prior (e.g., MaskGIT Prior) and introduce GIT-STORM. We evaluate our model on two downstream tasks: reinforcement learning and video prediction. GIT-STORM demonstrates substantial performance gains in RL tasks on the Atari 100k benchmark. Moreover, we apply Transformer-based World Models to continuous action environments for the first time, addressing a significant gap in prior research. To achieve this, we employ a state mixer function that integrates latent state representations with actions, enabling our model to handle continuous control tasks. We validate this approach through qualitative and quantitative analyses on the DeepMind Control Suite, showcasing the effectiveness of Transformer-based World Models in this new domain. Our results highlight the versatility and efficacy of the MaskGIT dynamics prior, paving the way for more accurate world models and effective RL policies.
Bayesian-LoRA: LoRA based Parameter Efficient Fine-Tuning using Optimal Quantization levels and Rank Values trough Differentiable Bayesian Gates
Jun 18, 2024



It is a common practice in natural language processing to pre-train a single model on a general domain and then fine-tune it for downstream tasks. However, when it comes to Large Language Models, fine-tuning the entire model can be computationally expensive, resulting in very intensive energy consumption. As a result, several Parameter efficient fine-tuning (PEFT) approaches were recently proposed. One of the most popular approaches is low-rank adaptation (LoRA), where the key insight is decomposing the update weights of the pre-trained model into two low-rank matrices. However, the proposed approaches either use the same rank value across all different weight matrices or do not use any quantization technique, which has been shown to be one of the most important factors when it comes to a model's energy consumption. In this work, we propose Bayesian-LoRA (B-LoRA) which approaches matrix decomposition and quantization from a Bayesian perspective by employing a prior distribution on both quantization levels and rank values of the learned low-rank matrices. As a result, B-LoRA is able to fine-tune a pre-trained model on a specific downstream task, finding the optimal rank values and quantization levels for every low-rank matrix. We validate the proposed model fine-tuning a pre-trained DeBERTaV3 on the GLUE benchmark. Moreover, we compare it to relevant baselines and present both qualitative and quantitative results, showing how the proposed approach is able to learn optimal-rank quantized matrices. B-LoRA performs on par or better than baselines while reducing the total amount of bit operations of roughly 70% with respect to the baselines ones.
Precipitation Nowcasting Using Physics Informed Discriminator Generative Models
Jun 14, 2024


Nowcasting leverages real-time atmospheric conditions to forecast weather over short periods. State-of-the-art models, including PySTEPS, encounter difficulties in accurately forecasting extreme weather events because of their unpredictable distribution patterns. In this study, we design a physics-informed neural network to perform precipitation nowcasting using the precipitation and meteorological data from the Royal Netherlands Meteorological Institute (KNMI). This model draws inspiration from the novel Physics-Informed Discriminator GAN (PID-GAN) formulation, directly integrating physics-based supervision within the adversarial learning framework. The proposed model adopts a GAN structure, featuring a Vector Quantization Generative Adversarial Network (VQ-GAN) and a Transformer as the generator, with a temporal discriminator serving as the discriminator. Our findings demonstrate that the PID-GAN model outperforms numerical and SOTA deep generative models in terms of precipitation nowcasting downstream metrics.
Extreme Precipitation Nowcasting using Transformer-based Generative Models
Mar 06, 2024



This paper presents an innovative approach to extreme precipitation nowcasting by employing Transformer-based generative models, namely NowcastingGPT with Extreme Value Loss (EVL) regularization. Leveraging a comprehensive dataset from the Royal Netherlands Meteorological Institute (KNMI), our study focuses on predicting short-term precipitation with high accuracy. We introduce a novel method for computing EVL without assuming fixed extreme representations, addressing the limitations of current models in capturing extreme weather events. We present both qualitative and quantitative analyses, demonstrating the superior performance of the proposed NowcastingGPT-EVL in generating accurate precipitation forecasts, especially when dealing with extreme precipitation events. The code is available at \url{https://github.com/Cmeo97/NowcastingGPT}.
Discrete Messages Improve Communication Efficiency among Isolated Intelligent Agents
Dec 28, 2023



Individuals, despite having varied life experiences and learning processes, can communicate effectively through languages. This study aims to explore the efficiency of language as a communication medium. We put forth two specific hypotheses: First, discrete messages are more effective than continuous ones when agents have diverse personal experiences. Second, communications using multiple discrete tokens are more advantageous than those using a single token. To valdate these hypotheses, we designed multi-agent machine learning experiments to assess communication efficiency using various information transmission methods between speakers and listeners. Our empirical findings indicate that, in scenarios where agents are exposed to different data, communicating through sentences composed of discrete tokens offers the best inter-agent communication efficiency. The limitations of our finding include lack of systematic advantages over other more sophisticated encoder-decoder model such as variational autoencoder and lack of evluation on non-image dataset, which we will leave for future studies.