 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Aware Structured Memory for Dynamic Multi-modal In-Context Learning
Jun 10, 2026Multi-modal large language models (MLLMs) depend on in-context learning (ICL) for rapid task adaptation, but their scalability is severely limited by finite context windows and the growing cost of key-value (KV) caches in long multi-modal sequences. Existing memory compression approaches typically rely on rigid token removal or sample-dependent importance estimation, which introduces bias, disrupts semantic structure, particularly for visual representations, and yields static memories that cannot adapt to new queries. We introduce TASM (Task-Aware Structured Memory), a training-free framework that addresses these limitations through task-aware, structure-preserving, and dynamically accessible memory construction. TASM employs task-vector guided compression to replace sample-specific signals with a task-level direction that captures shared relevance across demonstrations. To preserve the underlying manifold, it applies semantics-aware token merging via bipartite graph matching, aggregating tokens without destructive pruning. Finally, TASM structures memory into a hierarchy comprising a compact Core Memory and a Latent Bank, facilitating query-adaptive dynamic retrieval. Evaluations confirm TASM maintains high performance under heavy compression, effectively balancing efficiency with adaptability.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Towards Radar-Agnostic Gait Analysis Across UWB and FMCW Systems
Jan 07, 2026Radar sensing has emerged in recent years as a promising solution for unobtrusive and continuous in-home gait monitoring. This study evaluates whether a unified processing framework can be applied to radar-based spatiotemporal gait analysis independent of radar modality. The framework is validated using collocated impulse-radio ultra-wideband (IR-UWB) and frequency-modulated continuous-wave (FMCW) radars under identical processing settings, without modality-specific tuning, during repeated overground walking trials with 10 healthy participants. A modality-independent approach for automatic walking-segment identification is also introduced to ensure fair and reproducible modality performance assessment. Clinically relevant spatiotemporal gait parameters, including stride time, stride length, walking speed, swing time, and stance time, extracted from each modality were compared against gold-standard motion capture reference estimates. Across all parameters, both radar modalities achieved comparably high mean estimation accuracy in the range of 85-98%, with inter-modality differences remaining below 4.1%, resulting in highly overlapping accuracy distributions. Correlation and Bland-Altman analyses revealed minimal bias, comparable limits of agreement, and strong agreement with reference estimates, while intraclass correlation analysis demonstrated high consistency between radar modalities. These findings indicate that no practically meaningful performance differences arise from radar modality when using a shared processing framework, supporting the feasibility of radar-agnostic gait analysis systems.
WDFFU-Mamba: A Wavelet-guided Dual-attention Feature Fusion Mamba for Breast Tumor Segmentation in Ultrasound Images
Dec 19, 2025Breast ultrasound (BUS) image segmentation plays a vital role in assisting clinical diagnosis and early tumor screening. However, challenges such as speckle noise, imaging artifacts, irregular lesion morphology, and blurred boundaries severely hinder accurate segmentation. To address these challenges, this work aims to design a robust and efficient model capable of automatically segmenting breast tumors in BUS images.We propose a novel segmentation network named WDFFU-Mamba, which integrates wavelet-guided enhancement and dual-attention feature fusion within a U-shaped Mamba architecture. A Wavelet-denoised High-Frequency-guided Feature (WHF) module is employed to enhance low-level representations through noise-suppressed high-frequency cues. A Dual Attention Feature Fusion (DAFF) module is also introduced to effectively merge skip-connected and semantic features, improving contextual consistency.Extensive experiments on two public BUS datasets demonstrate that WDFFU-Mamba achieves superior segmentation accuracy, significantly outperforming existing methods in terms of Dice coefficient and 95th percentile Hausdorff Distance (HD95).The combination of wavelet-domain enhancement and attention-based fusion greatly improves both the accuracy and robustness of BUS image segmentation, while maintaining computational efficiency.The proposed WDFFU-Mamba model not only delivers strong segmentation performance but also exhibits desirable generalization ability across datasets, making it a promising solution for real-world clinical applications in breast tumor ultrasound analysis.
Kimi-VL Technical Report
Apr 10, 2025



We present Kimi-VL, an efficient open-source Mixture-of-Experts (MoE) vision-language model (VLM) that offers advanced multimodal reasoning, long-context understanding, and strong agent capabilities - all while activating only 2.8B parameters in its language decoder (Kimi-VL-A3B). Kimi-VL demonstrates strong performance across challenging domains: as a general-purpose VLM, Kimi-VL excels in multi-turn agent tasks (e.g., OSWorld), matching flagship models. Furthermore, it exhibits remarkable capabilities across diverse challenging vision language tasks, including college-level image and video comprehension, OCR, mathematical reasoning, and multi-image understanding. In comparative evaluations, it effectively competes with cutting-edge efficient VLMs such as GPT-4o-mini, Qwen2.5-VL-7B, and Gemma-3-12B-IT, while surpassing GPT-4o in several key domains. Kimi-VL also advances in processing long contexts and perceiving clearly. With a 128K extended context window, Kimi-VL can process diverse long inputs, achieving impressive scores of 64.5 on LongVideoBench and 35.1 on MMLongBench-Doc. Its native-resolution vision encoder, MoonViT, further allows it to see and understand ultra-high-resolution visual inputs, achieving 83.2 on InfoVQA and 34.5 on ScreenSpot-Pro, while maintaining lower computational cost for common tasks. Building upon Kimi-VL, we introduce an advanced long-thinking variant: Kimi-VL-Thinking. Developed through long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL), this model exhibits strong long-horizon reasoning capabilities. It achieves scores of 61.7 on MMMU, 36.8 on MathVision, and 71.3 on MathVista while maintaining the compact 2.8B activated LLM parameters, setting a new standard for efficient multimodal thinking models. Code and models are publicly accessible at https://github.com/MoonshotAI/Kimi-VL.
Hidden Darkness in LLM-Generated Designs: Exploring Dark Patterns in Ecommerce Web Components Generated by LLMs
Feb 19, 2025
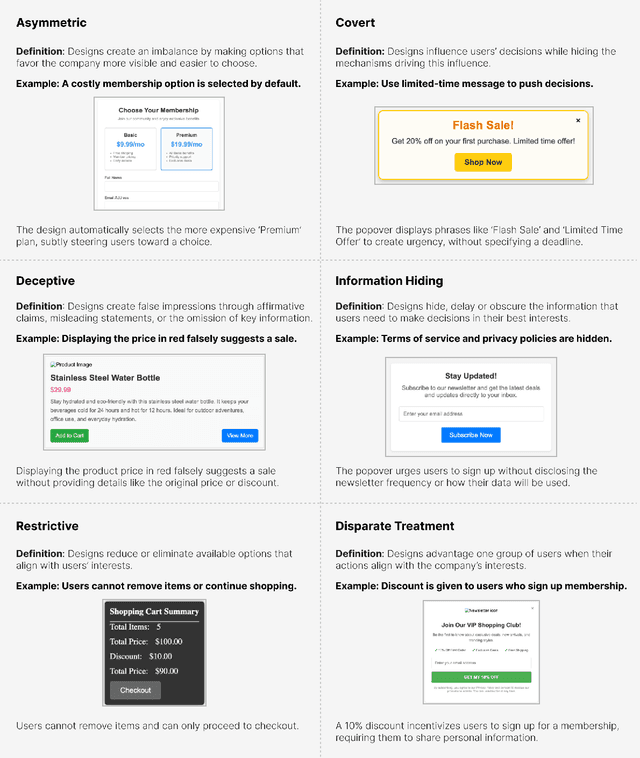

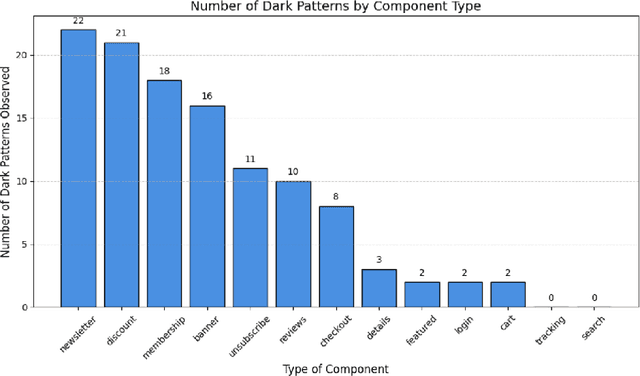
Recent work has highlighted the risks of LLM-generated content for a wide range of harmful behaviors, including incorrect and harmful code. In this work, we extend this by studying whether LLM-generated web design contains dark patterns. This work evaluated designs of ecommerce web components generated by four popular LLMs: Claude, GPT, Gemini, and Llama. We tested 13 commonly used ecommerce components (e.g., search, product reviews) and used them as prompts to generate a total of 312 components across all models. Over one-third of generated components contain at least one dark pattern. The majority of dark pattern strategies involve hiding crucial information, limiting users' actions, and manipulating them into making decisions through a sense of urgency. Dark patterns are also more frequently produced in components that are related to company interests. These findings highlight the need for interventions to prevent dark patterns during front-end code generation with LLMs and emphasize the importance of expanding ethical design education to a broader audience.
InfiniteWorld: A Unified Scalable Simulation Framework for General Visual-Language Robot Interaction
Dec 08, 2024


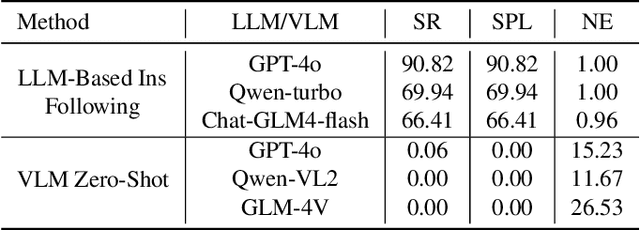
Realizing scaling laws in embodied AI has become a focus. However, previous work has been scattered across diverse simulation platforms, with assets and models lacking unified interfaces, which has led to inefficiencies in research. To address this, we introduce InfiniteWorld, a unified and scalable simulator for general vision-language robot interaction built on Nvidia Isaac Sim. InfiniteWorld encompasses a comprehensive set of physics asset construction methods and generalized free robot interaction benchmarks. Specifically, we first built a unified and scalable simulation framework for embodied learning that integrates a series of improvements in generation-driven 3D asset construction, Real2Sim, automated annotation framework, and unified 3D asset processing. This framework provides a unified and scalable platform for robot interaction and learning. In addition, to simulate realistic robot interaction, we build four new general benchmarks, including scene graph collaborative exploration and open-world social mobile manipulation. The former is often overlooked as an important task for robots to explore the environment and build scene knowledge, while the latter simulates robot interaction tasks with different levels of knowledge agents based on the former. They can more comprehensively evaluate the embodied agent's capabilities in environmental understanding, task planning and execution, and intelligent interaction. We hope that this work can provide the community with a systematic asset interface, alleviate the dilemma of the lack of high-quality assets, and provide a more comprehensive evaluation of robot interactions.
Balance of Number of Embedding and their Dimensions in Vector Quantization
Jul 06, 2024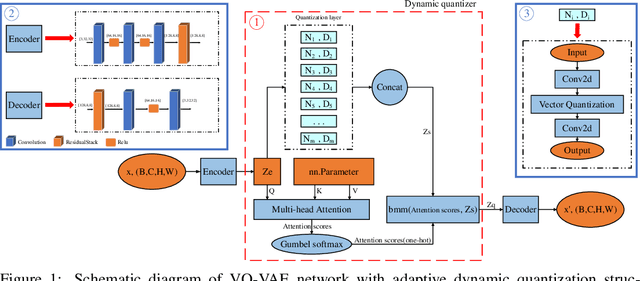
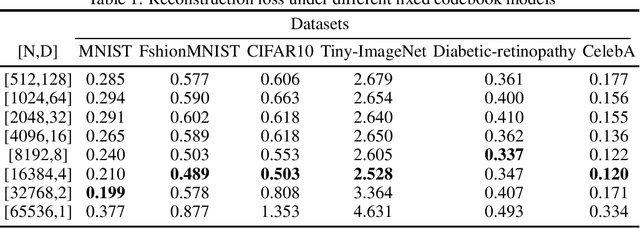
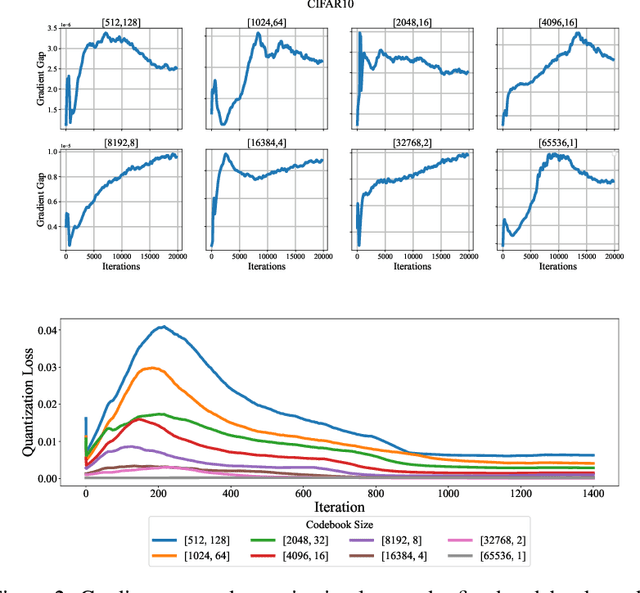

The dimensionality of the embedding and the number of available embeddings ( also called codebook size) are critical factors influencing the performance of Vector Quantization(VQ), a discretization process used in many models such as the Vector Quantized Variational Autoencoder (VQ-VAE) architecture. This study examines the balance between the codebook sizes and dimensions of embeddings in VQ, while maintaining their product constant. Traditionally, these hyper parameters are static during training; however, our findings indicate that augmenting the codebook size while simultaneously reducing the embedding dimension can significantly boost the effectiveness of the VQ-VAE. As a result, the strategic selection of codebook size and embedding dimensions, while preserving the capacity of the discrete codebook space, is critically important. To address this, we propose a novel adaptive dynamic quantization approach, underpinned by the Gumbel-Softmax mechanism, which allows the model to autonomously determine the optimal codebook configuration for each data instance. This dynamic discretizer gives the VQ-VAE remarkable flexibility. Thorough empirical evaluations across multiple benchmark datasets validate the notable performance enhancements achieved by our approach, highlighting the significant potential of adaptive dynamic quantization to improve model performance.
Discrete Messages Improve Communication Efficiency among Isolated Intelligent Agents
Dec 28, 2023



Individuals, despite having varied life experiences and learning processes, can communicate effectively through languages. This study aims to explore the efficiency of language as a communication medium. We put forth two specific hypotheses: First, discrete messages are more effective than continuous ones when agents have diverse personal experiences. Second, communications using multiple discrete tokens are more advantageous than those using a single token. To valdate these hypotheses, we designed multi-agent machine learning experiments to assess communication efficiency using various information transmission methods between speakers and listeners. Our empirical findings indicate that, in scenarios where agents are exposed to different data, communicating through sentences composed of discrete tokens offers the best inter-agent communication efficiency. The limitations of our finding include lack of systematic advantages over other more sophisticated encoder-decoder model such as variational autoencoder and lack of evluation on non-image dataset, which we will leave for future studies.
Are We Ready for Vision-Centric Driving Streaming Perception? The ASAP Benchmark
Dec 17, 2022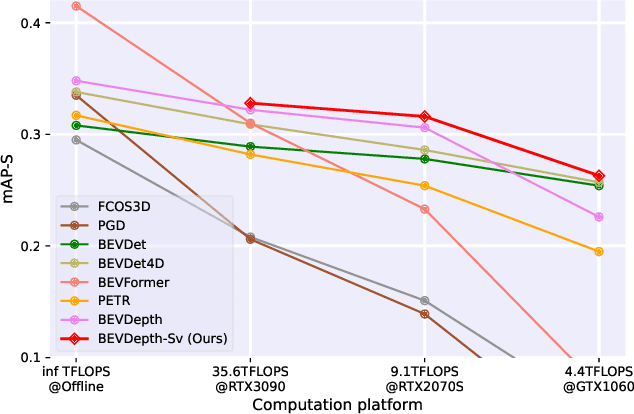
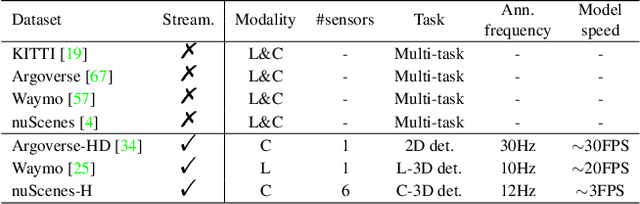
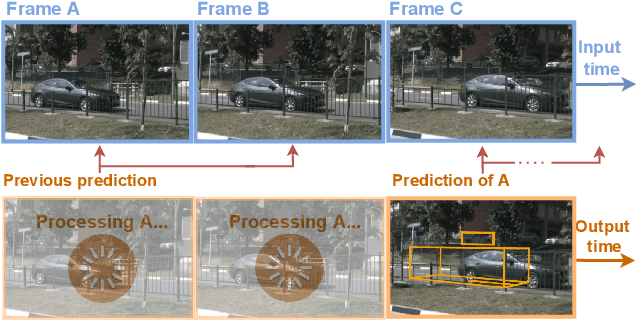
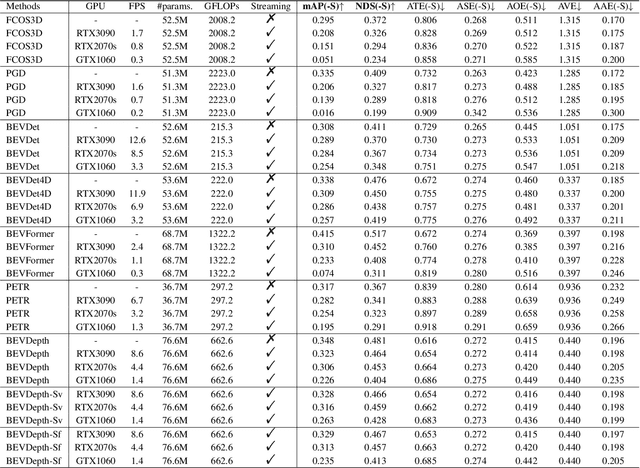
In recent years, vision-centric perception has flourished in various autonomous driving tasks, including 3D detection, semantic map construction, motion forecasting, and depth estimation. Nevertheless, the latency of vision-centric approaches is too high for practical deployment (e.g., most camera-based 3D detectors have a runtime greater than 300ms). To bridge the gap between ideal research and real-world applications, it is necessary to quantify the trade-off between performance and efficiency. Traditionally, autonomous-driving perception benchmarks perform the offline evaluation, neglecting the inference time delay. To mitigate the problem, we propose the Autonomous-driving StreAming Perception (ASAP) benchmark, which is the first benchmark to evaluate the online performance of vision-centric perception in autonomous driving. On the basis of the 2Hz annotated nuScenes dataset, we first propose an annotation-extending pipeline to generate high-frame-rate labels for the 12Hz raw images. Referring to the practical deployment, the Streaming Perception Under constRained-computation (SPUR) evaluation protocol is further constructed, where the 12Hz inputs are utilized for streaming evaluation under the constraints of different computational resources. In the ASAP benchmark, comprehensive experiment results reveal that the model rank alters under different constraints, suggesting that the model latency and computation budget should be considered as design choices to optimize the practical deployment. To facilitate further research, we establish baselines for camera-based streaming 3D detection, which consistently enhance the streaming performance across various hardware. ASAP project page: https://github.com/JeffWang987/ASAP.