 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA trained humanoid robot can perform human-like crossmodal social attention conflict resolution
Paper and Code
Nov 02, 2021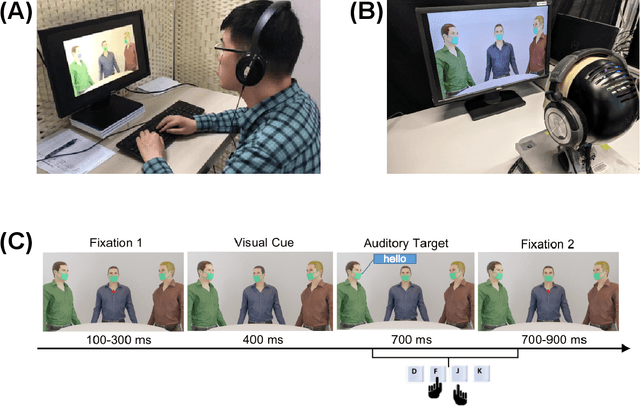
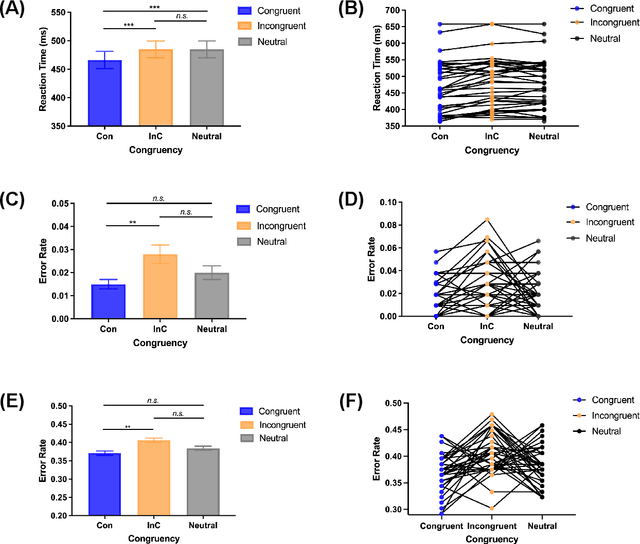
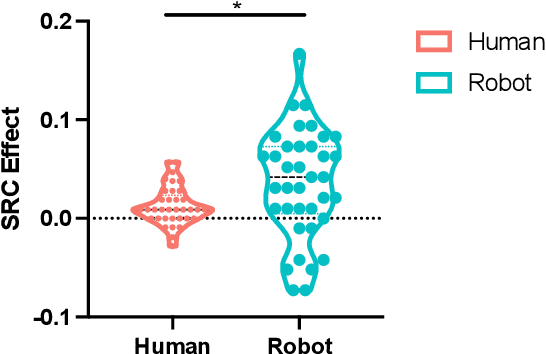

Due to the COVID-19 pandemic, robots could be seen as potential resources in tasks like helping people work remotely, sustaining social distancing, and improving mental or physical health. To enhance human-robot interaction, it is essential for robots to become more socialised, via processing multiple social cues in a complex real-world environment. Our study adopted a neurorobotic paradigm of gaze-triggered audio-visual crossmodal integration to make an iCub robot express human-like social attention responses. At first, a behavioural experiment was conducted on 37 human participants. To improve ecological validity, a round-table meeting scenario with three masked animated avatars was designed with the middle one capable of performing gaze shift, and the other two capable of generating sound. The gaze direction and the sound location are either congruent or incongruent. Masks were used to cover all facial visual cues other than the avatars' eyes. We observed that the avatar's gaze could trigger crossmodal social attention with better human performance in the audio-visual congruent condition than in the incongruent condition. Then, our computational model, GASP, was trained to implement social cue detection, audio-visual saliency prediction, and selective attention. After finishing the model training, the iCub robot was exposed to similar laboratory conditions as human participants, demonstrating that it can replicate similar attention responses as humans regarding the congruency and incongruency performance, while overall the human performance was still superior. Therefore, this interdisciplinary work provides new insights on mechanisms of crossmodal social attention and how it can be modelled in robots in a complex environment.