 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFabuLight-ASD: Unveiling Speech Activity via Body Language
Nov 20, 2024Active speaker detection (ASD) in multimodal environments is crucial for various applications, from video conferencing to human-robot interaction. This paper introduces FabuLight-ASD, an advanced ASD model that integrates facial, audio, and body pose information to enhance detection accuracy and robustness. Our model builds upon the existing Light-ASD framework by incorporating human pose data, represented through skeleton graphs, which minimises computational overhead. Using the Wilder Active Speaker Detection (WASD) dataset, renowned for reliable face and body bounding box annotations, we demonstrate FabuLight-ASD's effectiveness in real-world scenarios. Achieving an overall mean average precision (mAP) of 94.3%, FabuLight-ASD outperforms Light-ASD, which has an overall mAP of 93.7% across various challenging scenarios. The incorporation of body pose information shows a particularly advantageous impact, with notable improvements in mAP observed in scenarios with speech impairment, face occlusion, and human voice background noise. Furthermore, efficiency analysis indicates only a modest increase in parameter count (27.3%) and multiply-accumulate operations (up to 2.4%), underscoring the model's efficiency and feasibility. These findings validate the efficacy of FabuLight-ASD in enhancing ASD performance through the integration of body pose data. FabuLight-ASD's code and model weights are available at https://github.com/knowledgetechnologyuhh/FabuLight-ASD.
Whose Emotion Matters? Speaker Detection without Prior Knowledge
Dec 08, 2022The task of emotion recognition in conversations (ERC) benefits from the availability of multiple modalities, as offered, for example, in the video-based MELD dataset. However, only a few research approaches use both acoustic and visual information from the MELD videos. There are two reasons for this: First, label-to-video alignments in MELD are noisy, making those videos an unreliable source of emotional speech data. Second, conversations can involve several people in the same scene, which requires the detection of the person speaking the utterance. In this paper we demonstrate that by using recent automatic speech recognition and active speaker detection models, we are able to realign the videos of MELD, and capture the facial expressions from uttering speakers in 96.92% of the utterances provided in MELD. Experiments with a self-supervised voice recognition model indicate that the realigned MELD videos more closely match the corresponding utterances offered in the dataset. Finally, we devise a model for emotion recognition in conversations trained on the face and audio information of the MELD realigned videos, which outperforms state-of-the-art models for ERC based on vision alone. This indicates that active speaker detection is indeed effective for extracting facial expressions from the uttering speakers, and that faces provide more informative visual cues than the visual features state-of-the-art models have been using so far.
A trained humanoid robot can perform human-like crossmodal social attention conflict resolution
Nov 02, 2021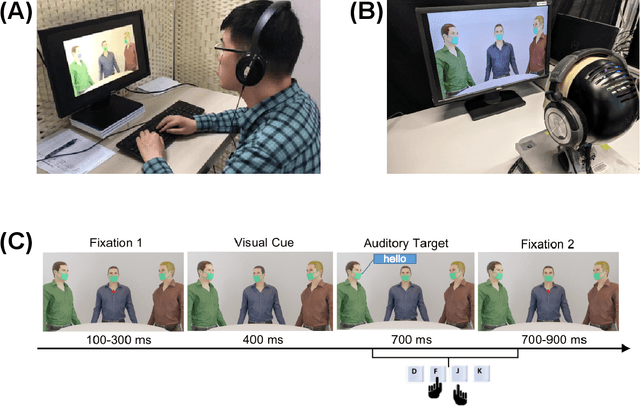
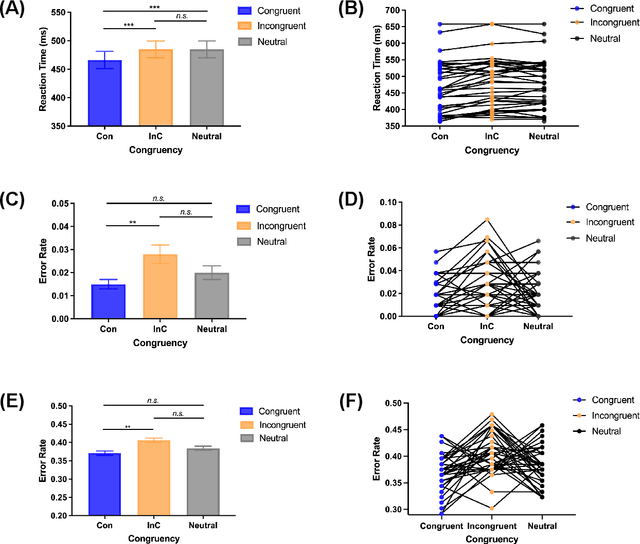
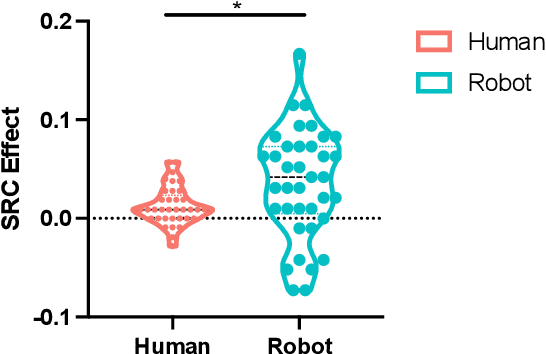

Due to the COVID-19 pandemic, robots could be seen as potential resources in tasks like helping people work remotely, sustaining social distancing, and improving mental or physical health. To enhance human-robot interaction, it is essential for robots to become more socialised, via processing multiple social cues in a complex real-world environment. Our study adopted a neurorobotic paradigm of gaze-triggered audio-visual crossmodal integration to make an iCub robot express human-like social attention responses. At first, a behavioural experiment was conducted on 37 human participants. To improve ecological validity, a round-table meeting scenario with three masked animated avatars was designed with the middle one capable of performing gaze shift, and the other two capable of generating sound. The gaze direction and the sound location are either congruent or incongruent. Masks were used to cover all facial visual cues other than the avatars' eyes. We observed that the avatar's gaze could trigger crossmodal social attention with better human performance in the audio-visual congruent condition than in the incongruent condition. Then, our computational model, GASP, was trained to implement social cue detection, audio-visual saliency prediction, and selective attention. After finishing the model training, the iCub robot was exposed to similar laboratory conditions as human participants, demonstrating that it can replicate similar attention responses as humans regarding the congruency and incongruency performance, while overall the human performance was still superior. Therefore, this interdisciplinary work provides new insights on mechanisms of crossmodal social attention and how it can be modelled in robots in a complex environment.
FaVoA: Face-Voice Association Favours Ambiguous Speaker Detection
Sep 01, 2021



The strong relation between face and voice can aid active speaker detection systems when faces are visible, even in difficult settings, when the face of a speaker is not clear or when there are several people in the same scene. By being capable of estimating the frontal facial representation of a person from his/her speech, it becomes easier to determine whether he/she is a potential candidate for being classified as an active speaker, even in challenging cases in which no mouth movement is detected from any person in that same scene. By incorporating a face-voice association neural network into an existing state-of-the-art active speaker detection model, we introduce FaVoA (Face-Voice Association Ambiguous Speaker Detector), a neural network model that can correctly classify particularly ambiguous scenarios. FaVoA not only finds positive associations, but helps to rule out non-matching face-voice associations, where a face does not match a voice. Its use of a gated-bimodal-unit architecture for the fusion of those models offers a way to quantitatively determine how much each modality contributes to the classification.