 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing User-Voice Interaction: Exploring Emotion-Aware Voice Assistants Through a Role-Swapping Approach
Feb 21, 2025As voice assistants (VAs) become increasingly integrated into daily life, the need for emotion-aware systems that can recognize and respond appropriately to user emotions has grown. While significant progress has been made in speech emotion recognition (SER) and sentiment analysis, effectively addressing user emotions-particularly negative ones-remains a challenge. This study explores human emotional response strategies in VA interactions using a role-swapping approach, where participants regulate AI emotions rather than receiving pre-programmed responses. Through speech feature analysis and natural language processing (NLP), we examined acoustic and linguistic patterns across various emotional scenarios. Results show that participants favor neutral or positive emotional responses when engaging with negative emotional cues, highlighting a natural tendency toward emotional regulation and de-escalation. Key acoustic indicators such as root mean square (RMS), zero-crossing rate (ZCR), and jitter were identified as sensitive to emotional states, while sentiment polarity and lexical diversity (TTR) distinguished between positive and negative responses. These findings provide valuable insights for developing adaptive, context-aware VAs capable of delivering empathetic, culturally sensitive, and user-aligned responses. By understanding how humans naturally regulate emotions in AI interactions, this research contributes to the design of more intuitive and emotionally intelligent voice assistants, enhancing user trust and engagement in human-AI interactions.
The 1st InterAI Workshop: Interactive AI for Human-centered Robotics
Sep 17, 2024The workshop is affiliated with 33nd IEEE International Conference on Robot and Human Interactive Communication (RO-MAN 2024) August 26~30, 2023 / Pasadena, CA, USA. It is designed as a half-day event, extending over four hours from 9:00 to 12:30 PST time. It accommodates both in-person and virtual attendees (via Zoom), ensuring a flexible participation mode. The agenda is thoughtfully crafted to include a diverse range of sessions: two keynote speeches that promise to provide insightful perspectives, two dedicated paper presentation sessions, an interactive panel discussion to foster dialogue among experts which facilitates deeper dives into specific topics, and a 15-minute coffee break. The workshop website: https://sites.google.com/view/interaiworkshops/home.
Vote&Mix: Plug-and-Play Token Reduction for Efficient Vision Transformer
Aug 30, 2024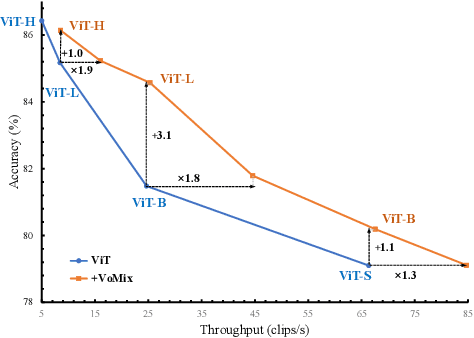
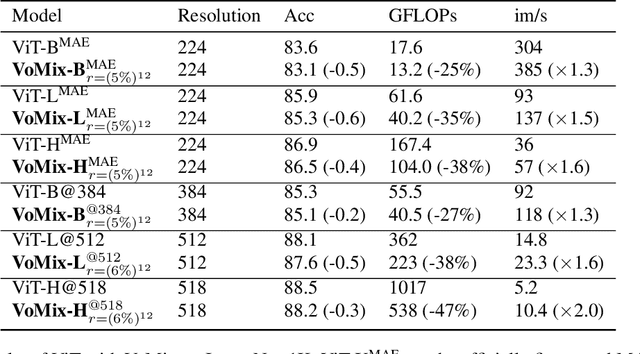
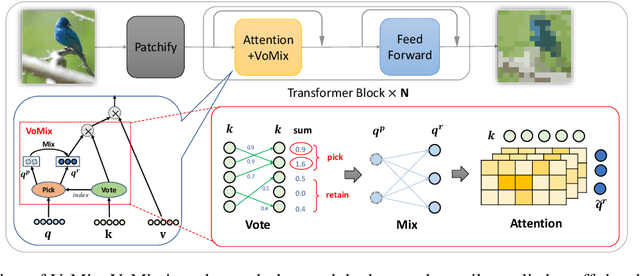
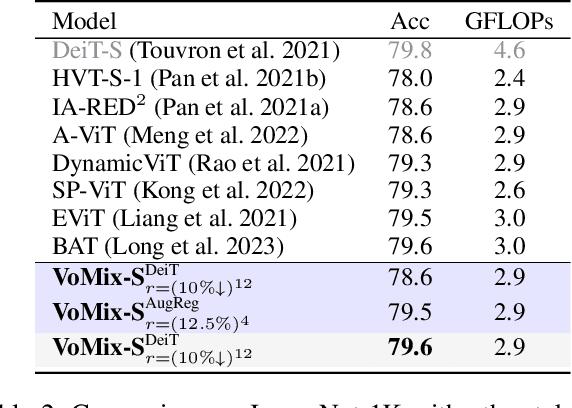
Despite the remarkable success of Vision Transformers (ViTs) in various visual tasks, they are often hindered by substantial computational cost. In this work, we introduce Vote\&Mix (\textbf{VoMix}), a plug-and-play and parameter-free token reduction method, which can be readily applied to off-the-shelf ViT models \textit{without any training}. VoMix tackles the computational redundancy of ViTs by identifying tokens with high homogeneity through a layer-wise token similarity voting mechanism. Subsequently, the selected tokens are mixed into the retained set, thereby preserving visual information. Experiments demonstrate VoMix significantly improves the speed-accuracy tradeoff of ViTs on both images and videos. Without any training, VoMix achieves a 2$\times$ increase in throughput of existing ViT-H on ImageNet-1K and a 2.4$\times$ increase in throughput of existing ViT-L on Kinetics-400 video dataset, with a mere 0.3\% drop in top-1 accuracy.
MultiMath: Bridging Visual and Mathematical Reasoning for Large Language Models
Aug 30, 2024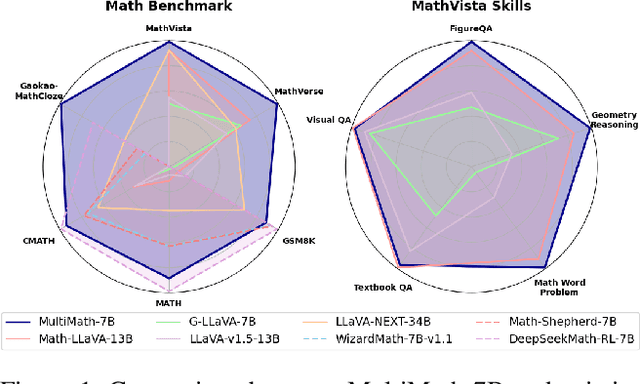
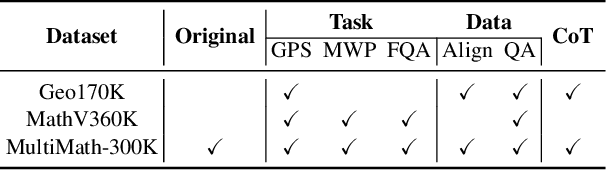
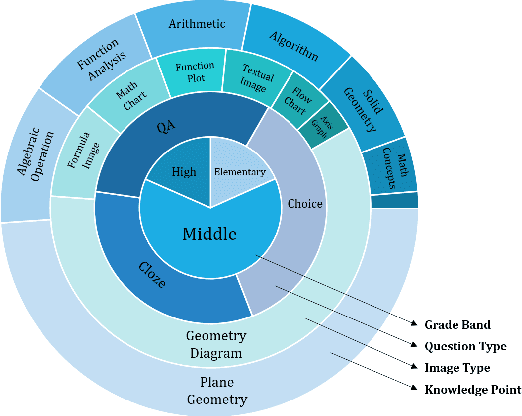
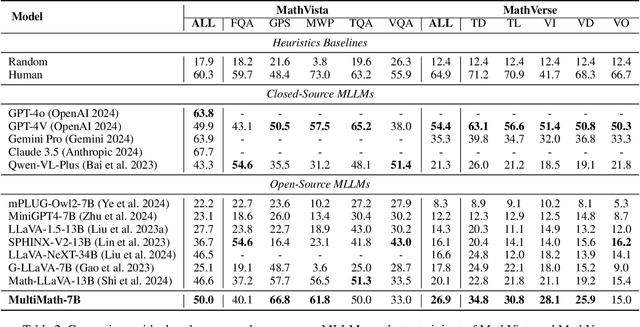
The rapid development of large language models (LLMs) has spurred extensive research into their domain-specific capabilities, particularly mathematical reasoning. However, most open-source LLMs focus solely on mathematical reasoning, neglecting the integration with visual injection, despite the fact that many mathematical tasks rely on visual inputs such as geometric diagrams, charts, and function plots. To fill this gap, we introduce \textbf{MultiMath-7B}, a multimodal large language model that bridges the gap between math and vision. \textbf{MultiMath-7B} is trained through a four-stage process, focusing on vision-language alignment, visual and math instruction-tuning, and process-supervised reinforcement learning. We also construct a novel, diverse and comprehensive multimodal mathematical dataset, \textbf{MultiMath-300K}, which spans K-12 levels with image captions and step-wise solutions. MultiMath-7B achieves state-of-the-art (SOTA) performance among open-source models on existing multimodal mathematical benchmarks and also excels on text-only mathematical benchmarks. Our model and dataset are available at {\textcolor{blue}{\url{https://github.com/pengshuai-rin/MultiMath}}}.
Shot Segmentation Based on Von Neumann Entropy for Key Frame Extraction
Aug 29, 2024


Video key frame extraction is important in various fields, such as video summary, retrieval, and compression. Therefore, we suggest a video key frame extraction algorithm based on shot segmentation using Von Neumann entropy. The segmentation of shots is achieved through the computation of Von Neumann entropy of the similarity matrix among frames within the video sequence. The initial frame of each shot is selected as key frames, which combines the temporal sequence information of frames. The experimental results show the extracted key frames can fully and accurately represent the original video content while minimizing the number of repeated frames.
Decoupled Prompt-Adapter Tuning for Continual Activity Recognition
Jul 20, 2024



Action recognition technology plays a vital role in enhancing security through surveillance systems, enabling better patient monitoring in healthcare, providing in-depth performance analysis in sports, and facilitating seamless human-AI collaboration in domains such as manufacturing and assistive technologies. The dynamic nature of data in these areas underscores the need for models that can continuously adapt to new video data without losing previously acquired knowledge, highlighting the critical role of advanced continual action recognition. To address these challenges, we propose Decoupled Prompt-Adapter Tuning (DPAT), a novel framework that integrates adapters for capturing spatial-temporal information and learnable prompts for mitigating catastrophic forgetting through a decoupled training strategy. DPAT uniquely balances the generalization benefits of prompt tuning with the plasticity provided by adapters in pretrained vision models, effectively addressing the challenge of maintaining model performance amidst continuous data evolution without necessitating extensive finetuning. DPAT consistently achieves state-of-the-art performance across several challenging action recognition benchmarks, thus demonstrating the effectiveness of our model in the domain of continual action recognition.
Unified Dynamic Scanpath Predictors Outperform Individually Trained Neural Models
May 07, 2024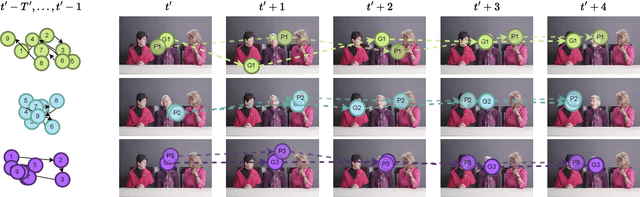
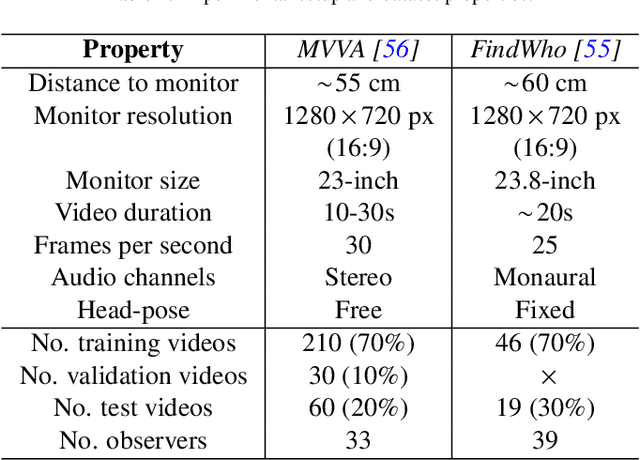
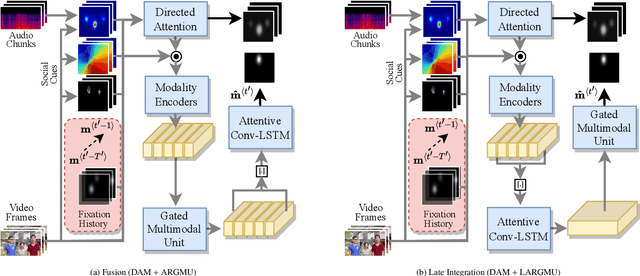
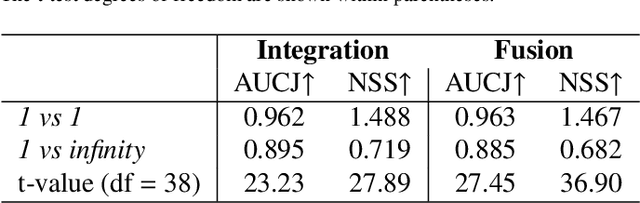
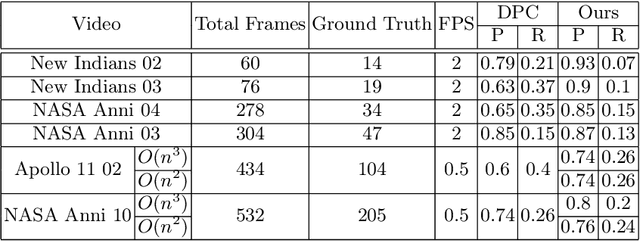
Previous research on scanpath prediction has mainly focused on group models, disregarding the fact that the scanpaths and attentional behaviors of individuals are diverse. The disregard of these differences is especially detrimental to social human-robot interaction, whereby robots commonly emulate human gaze based on heuristics or predefined patterns. However, human gaze patterns are heterogeneous and varying behaviors can significantly affect the outcomes of such human-robot interactions. To fill this gap, we developed a deep learning-based social cue integration model for saliency prediction to instead predict scanpaths in videos. Our model learned scanpaths by recursively integrating fixation history and social cues through a gating mechanism and sequential attention. We evaluated our approach on gaze datasets of dynamic social scenes, observed under the free-viewing condition. The introduction of fixation history into our models makes it possible to train a single unified model rather than the resource-intensive approach of training individual models for each set of scanpaths. We observed that the late neural integration approach surpasses early fusion when training models on a large dataset, in comparison to a smaller dataset with a similar distribution. Results also indicate that a single unified model, trained on all the observers' scanpaths, performs on par or better than individually trained models. We hypothesize that this outcome is a result of the group saliency representations instilling universal attention in the model, while the supervisory signal and fixation history guide it to learn personalized attentional behaviors, providing the unified model a benefit over individual models due to its implicit representation of universal attention.
Direct Preference Optimization of Video Large Multimodal Models from Language Model Reward
Apr 02, 2024



Preference modeling techniques, such as direct preference optimization (DPO), has shown effective in enhancing the generalization abilities of large language model (LLM). However, in tasks involving video instruction-following, providing informative feedback, especially for detecting hallucinations in generated responses, remains a significant challenge. Previous studies have explored using large large multimodal models (LMMs) as reward models to guide preference modeling, but their ability to accurately assess the factuality of generated responses compared to corresponding videos has not been conclusively established. This paper introduces a novel framework that utilizes detailed video captions as a proxy of video content, enabling language models to incorporate this information as supporting evidence for scoring video Question Answering (QA) predictions. Our approach demonstrates robust alignment with OpenAI GPT-4V model's reward mechanism, which directly takes video frames as input. Furthermore, we show that applying this tailored reward through DPO significantly improves the performance of video LMMs on video QA tasks.
Human Impression of Humanoid Robots Mirroring Social Cues
Jan 22, 2024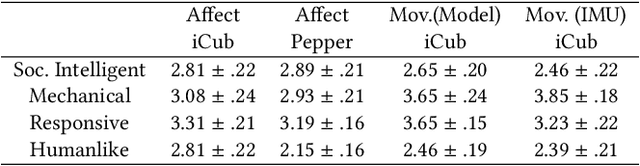

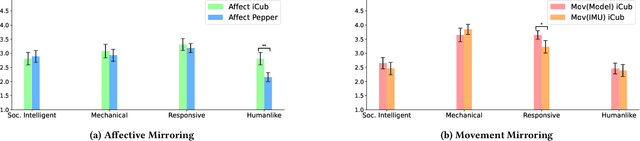
Mirroring non-verbal social cues such as affect or movement can enhance human-human and human-robot interactions in the real world. The robotic platforms and control methods also impact people's perception of human-robot interaction. However, limited studies have compared robot imitation across different platforms and control methods. Our research addresses this gap by conducting two experiments comparing people's perception of affective mirroring between the iCub and Pepper robots and movement mirroring between vision-based iCub control and Inertial Measurement Unit (IMU)-based iCub control. We discovered that the iCub robot was perceived as more humanlike than the Pepper robot when mirroring affect. A vision-based controlled iCub outperformed the IMU-based controlled one in the movement mirroring task. Our findings suggest that different robotic platforms impact people's perception of robots' mirroring during HRI. The control method also contributes to the robot's mirroring performance. Our work sheds light on the design and application of different humanoid robots in the real world.
The Emotional Dilemma: Influence of a Human-like Robot on Trust and Cooperation
Jul 06, 2023Increasing anthropomorphic robot behavioral design could affect trust and cooperation positively. However, studies have shown contradicting results and suggest a task-dependent relationship between robots that display emotions and trust. Therefore, this study analyzes the effect of robots that display human-like emotions on trust, cooperation, and participants' emotions. In the between-group study, participants play the coin entrustment game with an emotional and a non-emotional robot. The results show that the robot that displays emotions induces more anxiety than the neutral robot. Accordingly, the participants trust the emotional robot less and are less likely to cooperate. Furthermore, the perceived intelligence of a robot increases trust, while a desire to outcompete the robot can reduce trust and cooperation. Thus, the design of robots expressing emotions should be task dependent to avoid adverse effects that reduce trust and cooperation.