 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Dynamic Scanpath Predictors Outperform Individually Trained Neural Models
Paper and Code
May 07, 2024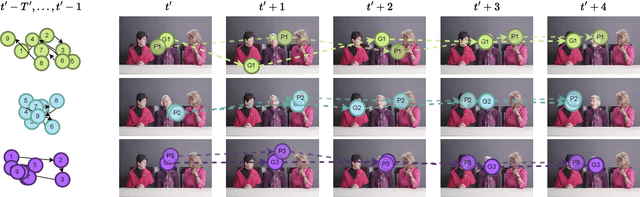
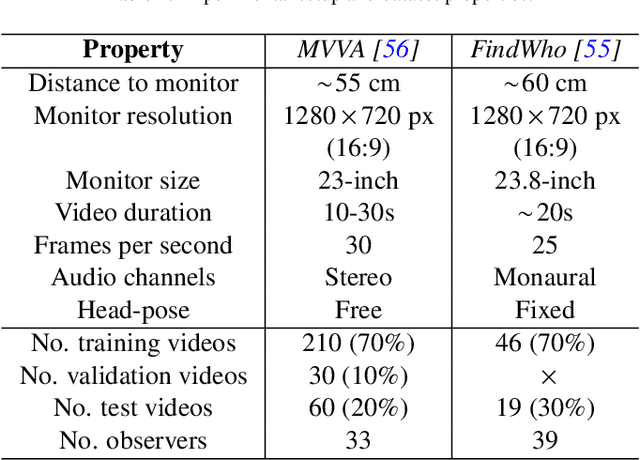
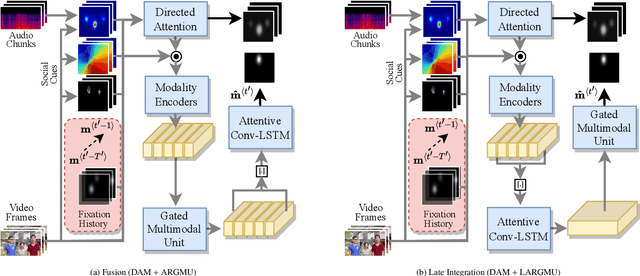
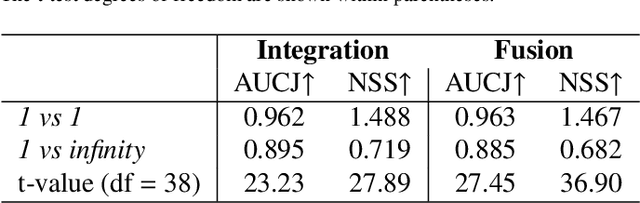
Previous research on scanpath prediction has mainly focused on group models, disregarding the fact that the scanpaths and attentional behaviors of individuals are diverse. The disregard of these differences is especially detrimental to social human-robot interaction, whereby robots commonly emulate human gaze based on heuristics or predefined patterns. However, human gaze patterns are heterogeneous and varying behaviors can significantly affect the outcomes of such human-robot interactions. To fill this gap, we developed a deep learning-based social cue integration model for saliency prediction to instead predict scanpaths in videos. Our model learned scanpaths by recursively integrating fixation history and social cues through a gating mechanism and sequential attention. We evaluated our approach on gaze datasets of dynamic social scenes, observed under the free-viewing condition. The introduction of fixation history into our models makes it possible to train a single unified model rather than the resource-intensive approach of training individual models for each set of scanpaths. We observed that the late neural integration approach surpasses early fusion when training models on a large dataset, in comparison to a smaller dataset with a similar distribution. Results also indicate that a single unified model, trained on all the observers' scanpaths, performs on par or better than individually trained models. We hypothesize that this outcome is a result of the group saliency representations instilling universal attention in the model, while the supervisory signal and fixation history guide it to learn personalized attentional behaviors, providing the unified model a benefit over individual models due to its implicit representation of universal attention.