 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiMath: Bridging Visual and Mathematical Reasoning for Large Language Models
Aug 30, 2024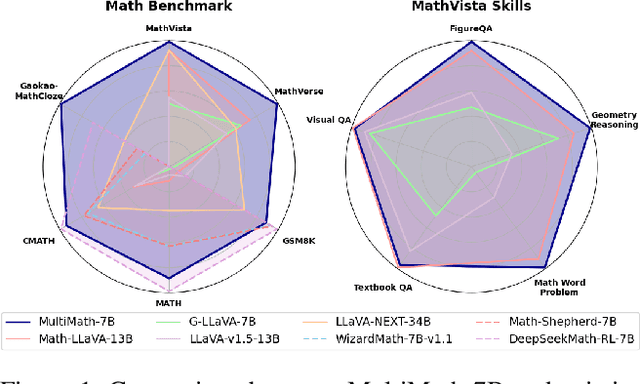
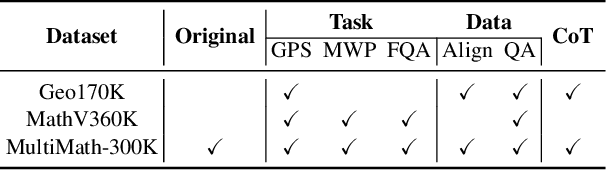
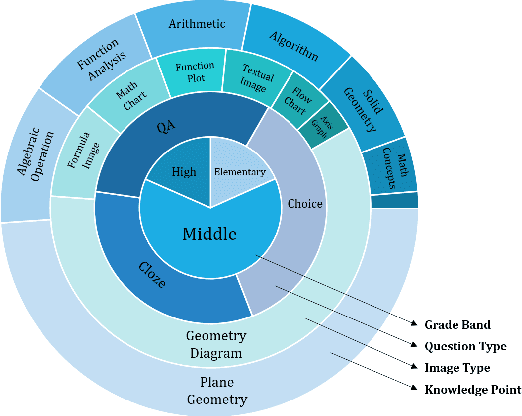
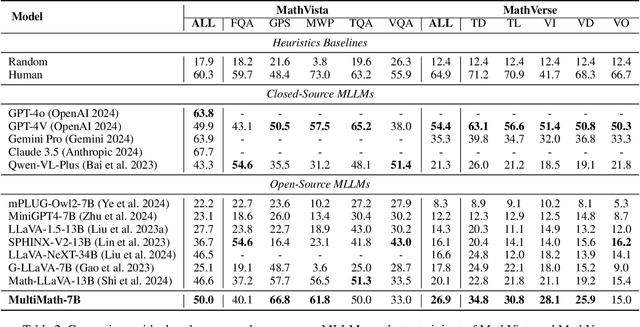
The rapid development of large language models (LLMs) has spurred extensive research into their domain-specific capabilities, particularly mathematical reasoning. However, most open-source LLMs focus solely on mathematical reasoning, neglecting the integration with visual injection, despite the fact that many mathematical tasks rely on visual inputs such as geometric diagrams, charts, and function plots. To fill this gap, we introduce \textbf{MultiMath-7B}, a multimodal large language model that bridges the gap between math and vision. \textbf{MultiMath-7B} is trained through a four-stage process, focusing on vision-language alignment, visual and math instruction-tuning, and process-supervised reinforcement learning. We also construct a novel, diverse and comprehensive multimodal mathematical dataset, \textbf{MultiMath-300K}, which spans K-12 levels with image captions and step-wise solutions. MultiMath-7B achieves state-of-the-art (SOTA) performance among open-source models on existing multimodal mathematical benchmarks and also excels on text-only mathematical benchmarks. Our model and dataset are available at {\textcolor{blue}{\url{https://github.com/pengshuai-rin/MultiMath}}}.
Incorporating Graph Attention Mechanism into Geometric Problem Solving Based on Deep Reinforcement Learning
Mar 14, 2024In the context of online education, designing an automatic solver for geometric problems has been considered a crucial step towards general math Artificial Intelligence (AI), empowered by natural language understanding and traditional logical inference. In most instances, problems are addressed by adding auxiliary components such as lines or points. However, adding auxiliary components automatically is challenging due to the complexity in selecting suitable auxiliary components especially when pivotal decisions have to be made. The state-of-the-art performance has been achieved by exhausting all possible strategies from the category library to identify the one with the maximum likelihood. However, an extensive strategy search have to be applied to trade accuracy for ef-ficiency. To add auxiliary components automatically and efficiently, we present deep reinforcement learning framework based on the language model, such as BERT. We firstly apply the graph attention mechanism to reduce the strategy searching space, called AttnStrategy, which only focus on the conclusion-related components. Meanwhile, a novel algorithm, named Automatically Adding Auxiliary Components using Reinforcement Learning framework (A3C-RL), is proposed by forcing an agent to select top strategies, which incorporates the AttnStrategy and BERT as the memory components. Results from extensive experiments show that the proposed A3C-RL algorithm can substantially enhance the average precision by 32.7% compared to the traditional MCTS. In addition, the A3C-RL algorithm outperforms humans on the geometric questions from the annual University Entrance Mathematical Examination of China.