 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphPL: Leveraging GNN for Efficient and Robust Modalities Imputation in Patchwork Learning
Apr 28, 2026Current research on distributed multi-modal learning typically assumes that clients can access complete information across all modalities, which may not hold in practice. In this paper, we explore patchwork learning, in which the modalities available to different clients vary, and the objective is to impute the missing modalities for each client in an unsupervised manner. Existing methods are shown not to fully utilize the modality information as they tend to rely on only a subset of the observed modalities. To address this issue, we propose GraphPL, which combines graph neural networks with patchwork learning to flexibly integrate all observed modalities and remains robust with noisy inputs. Experimental results show that GraphPL achieves SOTA performance on benchmark datasets. Our results on real-world distributed electronic health record dataset show GraphPL learns strong downstream features and enables tasks like disease prediction via superior modality imputation.
Uni-MuMER: Unified Multi-Task Fine-Tuning of Vision-Language Model for Handwritten Mathematical Expression Recognition
May 29, 2025Handwritten Mathematical Expression Recognition (HMER) remains a persistent challenge in Optical Character Recognition (OCR) due to the inherent freedom of symbol layout and variability in handwriting styles. Prior methods have faced performance bottlenecks, proposing isolated architectural modifications that are difficult to integrate coherently into a unified framework. Meanwhile, recent advances in pretrained vision-language models (VLMs) have demonstrated strong cross-task generalization, offering a promising foundation for developing unified solutions. In this paper, we introduce Uni-MuMER, which fully fine-tunes a VLM for the HMER task without modifying its architecture, effectively injecting domain-specific knowledge into a generalist framework. Our method integrates three data-driven tasks: Tree-Aware Chain-of-Thought (Tree-CoT) for structured spatial reasoning, Error-Driven Learning (EDL) for reducing confusion among visually similar characters, and Symbol Counting (SC) for improving recognition consistency in long expressions. Experiments on the CROHME and HME100K datasets show that Uni-MuMER achieves new state-of-the-art performance, surpassing the best lightweight specialized model SSAN by 16.31% and the top-performing VLM Gemini2.5-flash by 24.42% in the zero-shot setting. Our datasets, models, and code are open-sourced at: https://github.com/BFlameSwift/Uni-MuMER
Do Large Language Models Excel in Complex Logical Reasoning with Formal Language?
May 22, 2025Large Language Models (LLMs) have been shown to achieve breakthrough performance on complex logical reasoning tasks. Nevertheless, most existing research focuses on employing formal language to guide LLMs to derive reliable reasoning paths, while systematic evaluations of these capabilities are still limited. In this paper, we aim to conduct a comprehensive evaluation of LLMs across various logical reasoning problems utilizing formal languages. From the perspective of three dimensions, i.e., spectrum of LLMs, taxonomy of tasks, and format of trajectories, our key findings are: 1) Thinking models significantly outperform Instruct models, especially when formal language is employed; 2) All LLMs exhibit limitations in inductive reasoning capability, irrespective of whether they use a formal language; 3) Data with PoT format achieves the best generalization performance across other languages. Additionally, we also curate the formal-relative training data to further enhance the small language models, and the experimental results indicate that a simple rejected fine-tuning method can better enable LLMs to generalize across formal languages and achieve the best overall performance. Our codes and reports are available at https://github.com/jiangjin1999/FormalEval.
DocVideoQA: Towards Comprehensive Understanding of Document-Centric Videos through Question Answering
Mar 20, 2025Remote work and online courses have become important methods of knowledge dissemination, leading to a large number of document-based instructional videos. Unlike traditional video datasets, these videos mainly feature rich-text images and audio that are densely packed with information closely tied to the visual content, requiring advanced multimodal understanding capabilities. However, this domain remains underexplored due to dataset availability and its inherent complexity. In this paper, we introduce the DocVideoQA task and dataset for the first time, comprising 1454 videos across 23 categories with a total duration of about 828 hours. The dataset is annotated with 154k question-answer pairs generated manually and via GPT, assessing models' comprehension, temporal awareness, and modality integration capabilities. Initially, we establish a baseline using open-source MLLMs. Recognizing the challenges in modality comprehension for document-centric videos, we present DV-LLaMA, a robust video MLLM baseline. Our method enhances unimodal feature extraction with diverse instruction-tuning data and employs contrastive learning to strengthen modality integration. Through fine-tuning, the LLM is equipped with audio-visual capabilities, leading to significant improvements in document-centric video understanding. Extensive testing on the DocVideoQA dataset shows that DV-LLaMA significantly outperforms existing models. We'll release the code and dataset to facilitate future research.
CJEval: A Benchmark for Assessing Large Language Models Using Chinese Junior High School Exam Data
Sep 25, 2024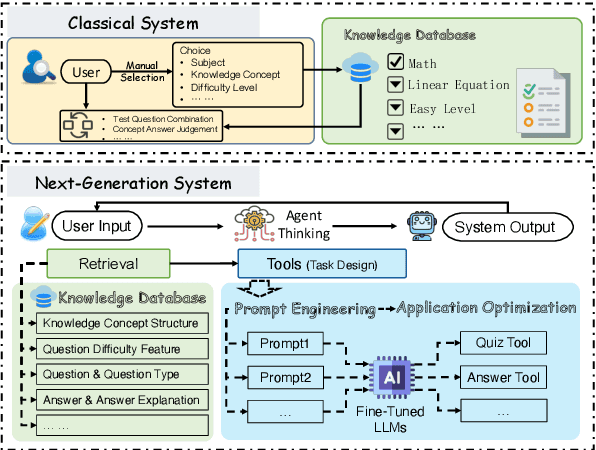
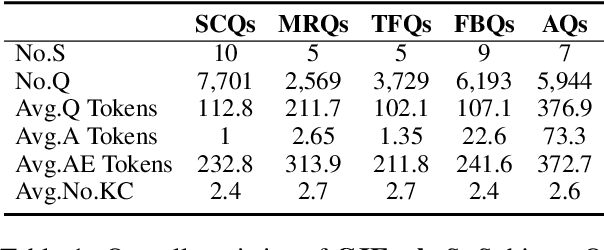

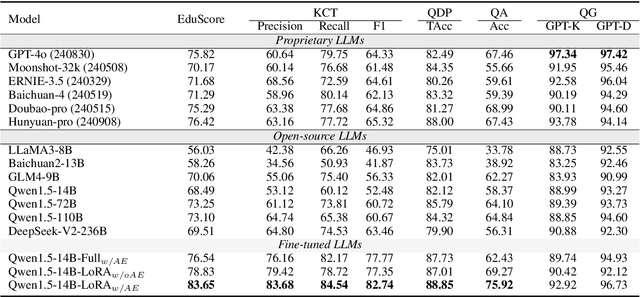
Online education platforms have significantly transformed the dissemination of educational resources by providing a dynamic and digital infrastructure. With the further enhancement of this transformation, the advent of Large Language Models (LLMs) has elevated the intelligence levels of these platforms. However, current academic benchmarks provide limited guidance for real-world industry scenarios. This limitation arises because educational applications require more than mere test question responses. To bridge this gap, we introduce CJEval, a benchmark based on Chinese Junior High School Exam Evaluations. CJEval consists of 26,136 samples across four application-level educational tasks covering ten subjects. These samples include not only questions and answers but also detailed annotations such as question types, difficulty levels, knowledge concepts, and answer explanations. By utilizing this benchmark, we assessed LLMs' potential applications and conducted a comprehensive analysis of their performance by fine-tuning on various educational tasks. Extensive experiments and discussions have highlighted the opportunities and challenges of applying LLMs in the field of education.
Vote&Mix: Plug-and-Play Token Reduction for Efficient Vision Transformer
Aug 30, 2024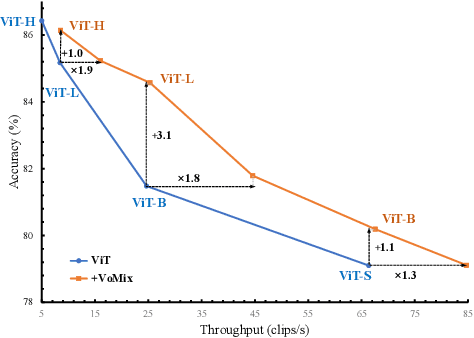
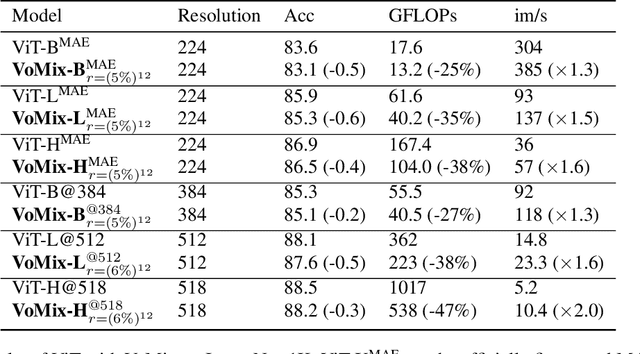
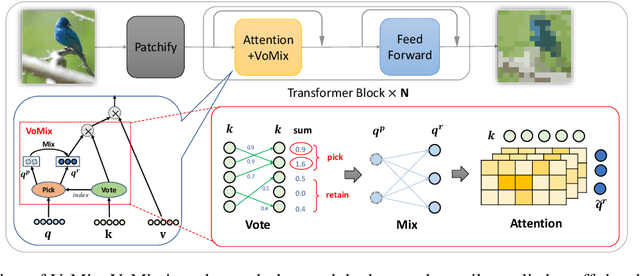
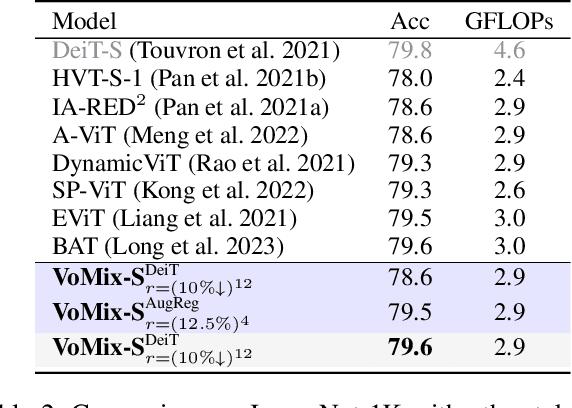
Despite the remarkable success of Vision Transformers (ViTs) in various visual tasks, they are often hindered by substantial computational cost. In this work, we introduce Vote\&Mix (\textbf{VoMix}), a plug-and-play and parameter-free token reduction method, which can be readily applied to off-the-shelf ViT models \textit{without any training}. VoMix tackles the computational redundancy of ViTs by identifying tokens with high homogeneity through a layer-wise token similarity voting mechanism. Subsequently, the selected tokens are mixed into the retained set, thereby preserving visual information. Experiments demonstrate VoMix significantly improves the speed-accuracy tradeoff of ViTs on both images and videos. Without any training, VoMix achieves a 2$\times$ increase in throughput of existing ViT-H on ImageNet-1K and a 2.4$\times$ increase in throughput of existing ViT-L on Kinetics-400 video dataset, with a mere 0.3\% drop in top-1 accuracy.
MultiMath: Bridging Visual and Mathematical Reasoning for Large Language Models
Aug 30, 2024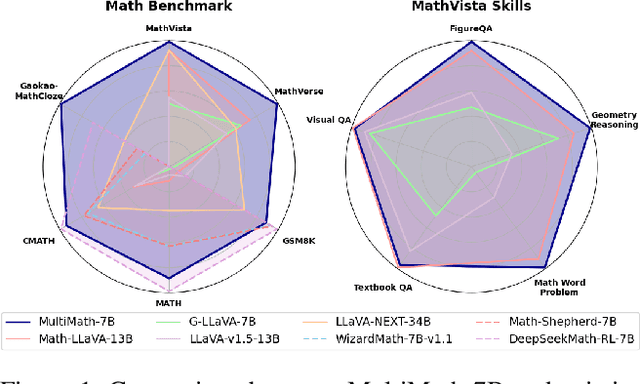
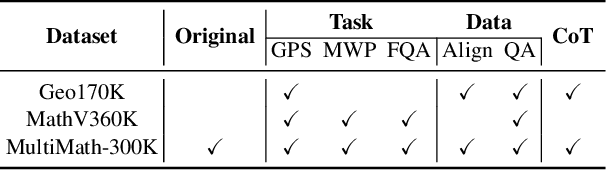
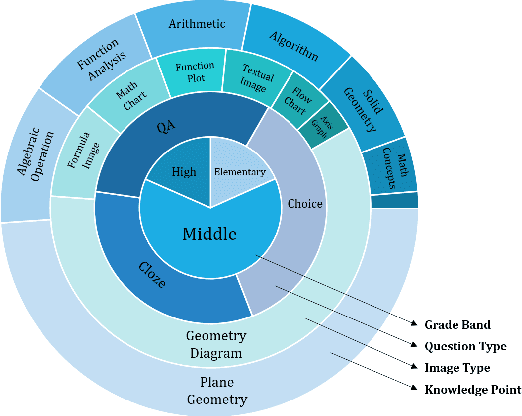
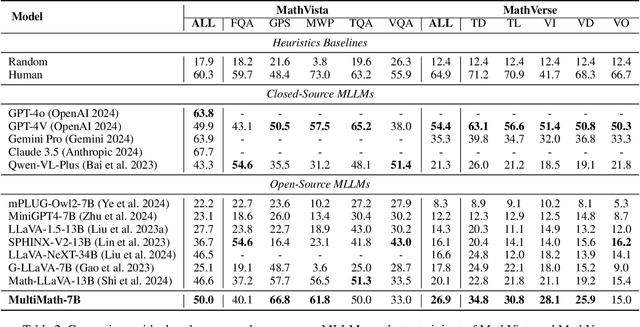
The rapid development of large language models (LLMs) has spurred extensive research into their domain-specific capabilities, particularly mathematical reasoning. However, most open-source LLMs focus solely on mathematical reasoning, neglecting the integration with visual injection, despite the fact that many mathematical tasks rely on visual inputs such as geometric diagrams, charts, and function plots. To fill this gap, we introduce \textbf{MultiMath-7B}, a multimodal large language model that bridges the gap between math and vision. \textbf{MultiMath-7B} is trained through a four-stage process, focusing on vision-language alignment, visual and math instruction-tuning, and process-supervised reinforcement learning. We also construct a novel, diverse and comprehensive multimodal mathematical dataset, \textbf{MultiMath-300K}, which spans K-12 levels with image captions and step-wise solutions. MultiMath-7B achieves state-of-the-art (SOTA) performance among open-source models on existing multimodal mathematical benchmarks and also excels on text-only mathematical benchmarks. Our model and dataset are available at {\textcolor{blue}{\url{https://github.com/pengshuai-rin/MultiMath}}}.
DocTabQA: Answering Questions from Long Documents Using Tables
Aug 21, 2024We study a new problem setting of question answering (QA), referred to as DocTabQA. Within this setting, given a long document, the goal is to respond to questions by organizing the answers into structured tables derived directly from the document's content. Unlike traditional QA approaches which predominantly rely on unstructured text to formulate responses, DocTabQA aims to leverage structured tables as answers to convey information clearly and systematically, thereby enhancing user comprehension and highlighting relationships between data points. To the best of our knowledge, this problem has not been previously explored. In this paper, we introduce the QTabA dataset, encompassing 300 financial documents, accompanied by manually annotated 1.5k question-table pairs. Initially, we leverage Large Language Models (LLMs) such as GPT-4 to establish a baseline. However, it is widely acknowledged that LLMs encounter difficulties when tasked with generating intricate, structured outputs from long input sequences. To overcome these challenges, we present a two-stage framework, called DocTabTalk, which initially retrieves relevant sentences from extensive documents and subsequently generates hierarchical tables based on these identified sentences. DocTabTalk incorporates two key technological innovations: AlignLLaMA and TabTalk, which are specifically tailored to assist GPT-4 in tackling DocTabQA, enabling it to generate well-structured, hierarchical tables with improved organization and clarity. Comprehensive experimental evaluations conducted on both QTabA and RotoWire datasets demonstrate that our DocTabTalk significantly enhances the performances of the GPT-4 in our proposed DocTabQA task and the table generation task. The code and dataset are available at https://github.com/SmileWHC/DocTabQA for further research.
SketchRef: A Benchmark Dataset and Evaluation Metrics for Automated Sketch Synthesis
Aug 16, 2024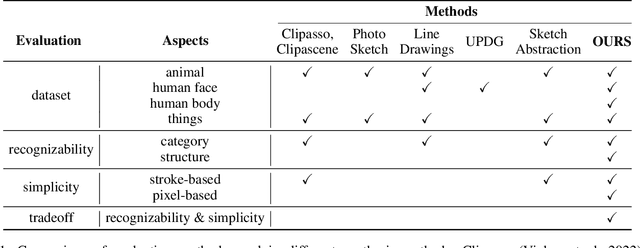
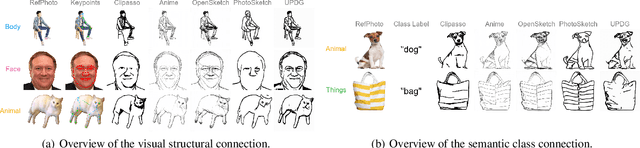
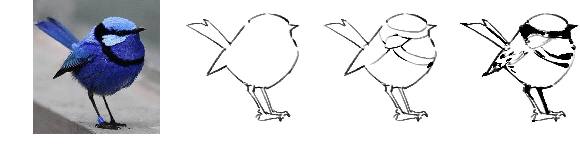

Sketch, a powerful artistic technique to capture essential visual information about real-world objects, is increasingly gaining attention in the image synthesis field. However, evaluating the quality of synthesized sketches presents unique unsolved challenges. Current evaluation methods for sketch synthesis are inadequate due to the lack of a unified benchmark dataset, over-reliance on classification accuracy for recognizability, and unfair evaluation of sketches with different levels of simplification. To address these issues, we introduce SketchRef, a benchmark dataset comprising 4 categories of reference photos--animals, human faces, human bodies, and common objects--alongside novel evaluation metrics. Considering that classification accuracy is insufficient to measure the structural consistency between a sketch and its reference photo, we propose the mean Object Keypoint Similarity (mOKS) metric, utilizing pose estimation to assess structure-level recognizability. To ensure fair evaluation sketches with different simplification levels, we propose a recognizability calculation method constrained by simplicity. We also collect 8K responses from art enthusiasts, validating the effectiveness of our proposed evaluation methods. We hope this work can provide a comprehensive evaluation of sketch synthesis algorithms, thereby aligning their performance more closely with human understanding.
TAMER: Tree-Aware Transformer for Handwritten Mathematical Expression Recognition
Aug 16, 2024



Handwritten Mathematical Expression Recognition (HMER) has extensive applications in automated grading and office automation. However, existing sequence-based decoding methods, which directly predict $\LaTeX$ sequences, struggle to understand and model the inherent tree structure of $\LaTeX$ and often fail to ensure syntactic correctness in the decoded results. To address these challenges, we propose a novel model named TAMER (Tree-Aware Transformer) for handwritten mathematical expression recognition. TAMER introduces an innovative Tree-aware Module while maintaining the flexibility and efficient training of Transformer. TAMER combines the advantages of both sequence decoding and tree decoding models by jointly optimizing sequence prediction and tree structure prediction tasks, which enhances the model's understanding and generalization of complex mathematical expression structures. During inference, TAMER employs a Tree Structure Prediction Scoring Mechanism to improve the structural validity of the generated $\LaTeX$ sequences. Experimental results on CROHME datasets demonstrate that TAMER outperforms traditional sequence decoding and tree decoding models, especially in handling complex mathematical structures, achieving state-of-the-art (SOTA) performance.