 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Airy Beam Training for Quasi-LoS Terahertz Near-Field Communications
May 11, 2026With the enlargement of antenna apertures in 6G Terahertz (THz) communications, the Rayleigh distance expands significantly, rendering near-field propagation a dominant scenario in THz links. Beyond conventional Line-of-Sight (LoS) and Non-Line-of-Sight (NLoS) conditions, quasi-LoS scenarios with partial obstructions have emerged as a critical challenge. Airy beams offer a promising solution to circumvent obstacles due to their unique curving trajectory. However, existing Airy beam training methods typically rely on parameter-based sampling or exhaustive search, leading to significant pilot overhead and low training efficiency. In this paper, an efficient Airy beam training framework is proposed to address this research gap. First, the theoretical bounds of Airy beam generation under finite apertures to prune physically invalid codewords are derived. Based on this, a two-stage Non-Uniform Polar Codebook (NUPC) design is presented, utilizing a probing mechanism to resolve the bending direction and a polar-domain spatial sampling strategy to generate Airy beams. To address ultra-low latency requirements, a Fast-Scanning 1D Codebook (FS1C) is further developed that sweeps the entire LoS region with minimal codewords. Simulation results demonstrate that NUPC achieves a higher average spectral efficiency (SE) by 13.4 bit/s/Hz while reducing training overhead by 54.2% compared to the state-of-the-art hierarchical focusing-Airy codebook (HFAC). Furthermore, FS1C reduces overhead by 92.9% with only a marginal 0.3 bit/s/Hz reduction compared with HFAC.
Airy Beam Engineering in Near-field Communications: A Tractable Closed-Form Analysis in the Terahertz Band
Mar 14, 2026Terahertz (THz) communication can offer terabit-per-second rates in future wireless systems, thanks to the ultra-wide bandwidths, but require large antenna arrays. As antenna apertures expand and we enter the near-field scenarios, the conventional binary classification of communication links as either Line-of-Sight (LoS) or Non-Line-of-Sight (NLoS) becomes insufficient. Instead, quasi-LoS scenarios, where the LoS path is partially obstructed, are increasingly prevalent, posing significant challenges for traditional LoS focusing and steering beams. The Airy beam serves as a promising alternative, utilizing its non-diffracting and curved trajectory properties to mitigate such blockages. However, while existing electromagnetics literature primarily explores their physical patterns without practical generation schemes, recent communication-oriented designs predominantly rely on learning-based frameworks lacking interpretable closed-form solutions. To address this issue, this paper investigates a closed-form Airy beam design to efficiently synthesize Airy beam phase profiles based on the positions of the transceivers and obstacles. Specifically, rigorous analytical derivations of the electric field and trajectory are presented to establish a deterministic closed-form design for ULA Airy beamforming. Leveraging 3D wavefront separability, this framework is extended to uniform planar arrays (UPAs) with two operation modes: the hybrid focusing-Airy mode and the dual Airy mode. Simulation results verify the effectiveness of our derived trajectory equations and demonstrate that the proposed closed-form design significantly outperforms conventional beamforming schemes in quasi-LoS scenarios. Furthermore, the proposed method achieves performance comparable to exhaustive numerical searches with low computational complexity and enhanced physical interpretability.
Terahertz Wireless Data Center: Gaussian Beam or Airy Beam?
Apr 29, 2025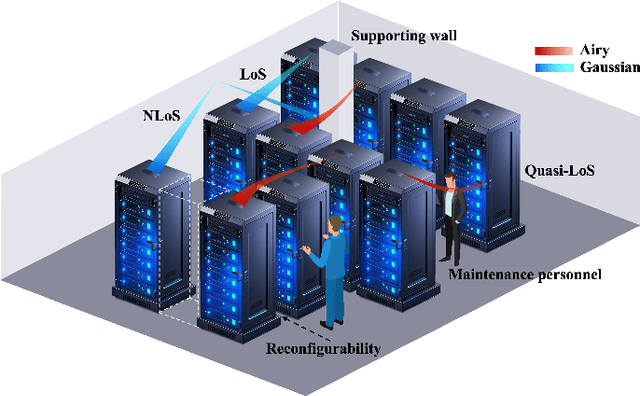
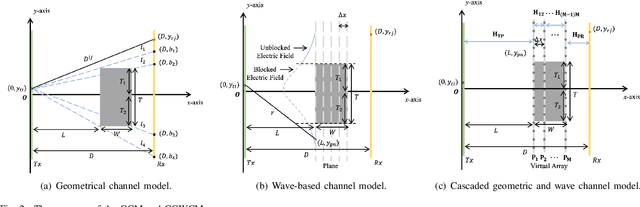
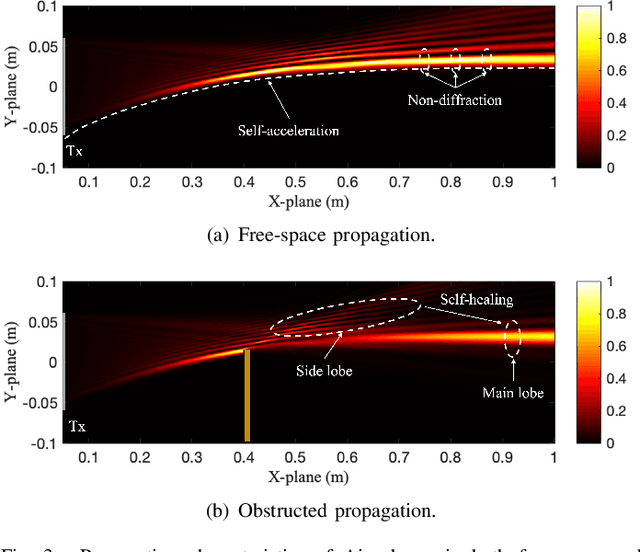
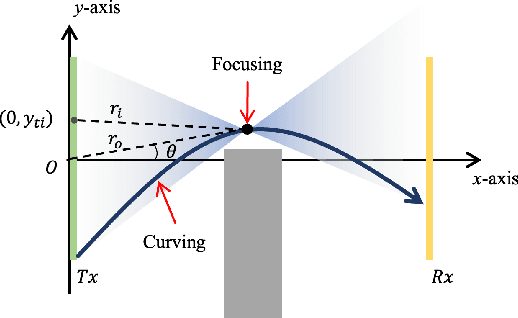
Terahertz (THz) communication is emerging as a pivotal enabler for 6G and beyond wireless systems owing to its multi-GHz bandwidth. One of its novel applications is in wireless data centers, where it enables ultra-high data rates while enhancing network reconfigurability and scalability. However, due to numerous racks, supporting walls, and densely deployed antennas, the line-of-sight (LoS) path in data centers is often instead of fully obstructed, resulting in quasi-LoS propagation and degradation of spectral efficiency. To address this issue, Airy beam-based hybrid beamforming is investigated in this paper as a promising technique to mitigate quasi-LoS propagation and enhance spectral efficiency in THz wireless data centers. Specifically, a cascaded geometrical and wave-based channel model (CGWCM) is proposed for quasi-LoS scenarios, which accounts for diffraction effects while being more simplified than conventional wave-based model. Then, the characteristics and generation of the Airy beam are analyzed, and beam search methods for quasi-LoS scenarios are proposed, including hierarchical focusing-Airy beam search, and low-complexity beam search. Simulation results validate the effectiveness of the CGWCM and demonstrate the superiority of the Airy beam over Gaussian beams in mitigating blockages, verifying its potential for practical THz wireless communication in data centers.
DNN based Two-stage Compensation Algorithm for THz Hybrid Beamforming with imperfect Hardware
Nov 22, 2024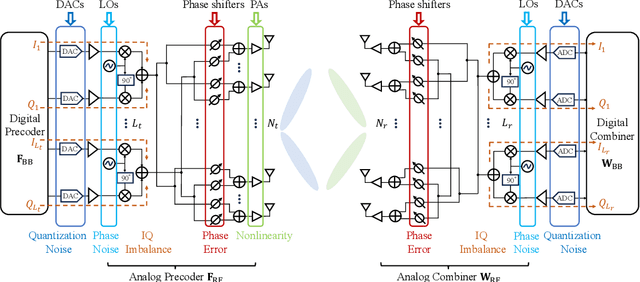
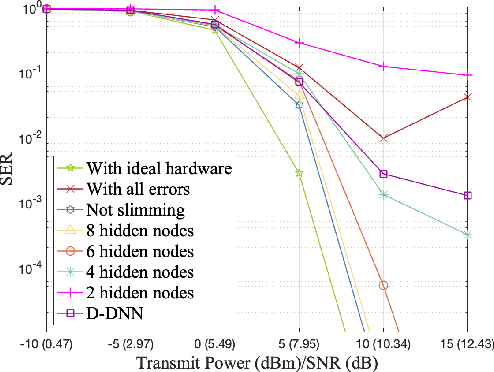
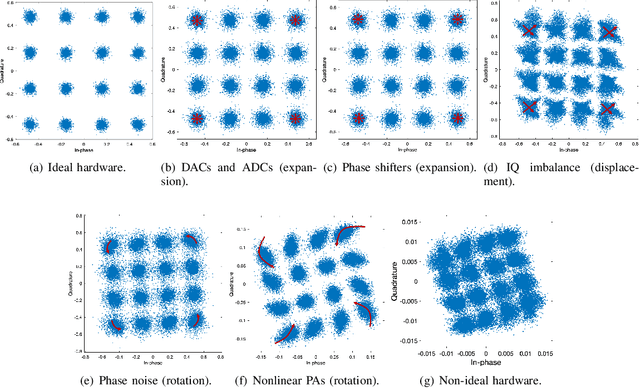

Terahertz (THz) communication is envisioned as a key technology for 6G and beyond wireless systems owing to its multi-GHz bandwidth. To maintain the same aperture area and the same link budget as the lower frequencies, ultra-massive multi-input and multi-output (UM-MIMO) with hybrid beamforming is promising. Nevertheless, the hardware imperfections particularly at THz frequencies, can degrade spectral efficiency and lead to a high symbol error rate (SER), which is often overlooked yet imperative to address in practical THz communication systems. In this paper, the hybrid beamforming is investigated for THz UM-MIMO systems accounting for comprehensive hardware imperfections, including DAC and ADC quantization errors, in-phase and quadrature imbalance (IQ imbalance), phase noise, amplitude and phase error of imperfect phase shifters and power amplifier (PA) nonlinearity. Then, a two-stage hardware imperfection compensation algorithm is proposed. A deep neural network (DNN) is developed in the first stage to represent the combined hardware imperfections, while in the second stage, the digital precoder in the transmitter (Tx) or the combiner in the receiver (Rx) is designed using NN to effectively compensate for these imperfections. Furthermore, to balance the performance and network complexity, three slimming methods including pruning, parameter sharing, and removing parts of the network are proposed and combined to slim the DNN in the first stage. Numerical results show that the Tx compensation can perform better than the Rx compensation. Additionally, using the combined slimming methods can reduce parameters by 97.2% and running time by 39.2% while maintaining nearly the same performance in both uncoded and coded systems.
TAMER: Tree-Aware Transformer for Handwritten Mathematical Expression Recognition
Aug 16, 2024



Handwritten Mathematical Expression Recognition (HMER) has extensive applications in automated grading and office automation. However, existing sequence-based decoding methods, which directly predict $\LaTeX$ sequences, struggle to understand and model the inherent tree structure of $\LaTeX$ and often fail to ensure syntactic correctness in the decoded results. To address these challenges, we propose a novel model named TAMER (Tree-Aware Transformer) for handwritten mathematical expression recognition. TAMER introduces an innovative Tree-aware Module while maintaining the flexibility and efficient training of Transformer. TAMER combines the advantages of both sequence decoding and tree decoding models by jointly optimizing sequence prediction and tree structure prediction tasks, which enhances the model's understanding and generalization of complex mathematical expression structures. During inference, TAMER employs a Tree Structure Prediction Scoring Mechanism to improve the structural validity of the generated $\LaTeX$ sequences. Experimental results on CROHME datasets demonstrate that TAMER outperforms traditional sequence decoding and tree decoding models, especially in handling complex mathematical structures, achieving state-of-the-art (SOTA) performance.
ICAL: Implicit Character-Aided Learning for Enhanced Handwritten Mathematical Expression Recognition
May 15, 2024Significant progress has been made in the field of handwritten mathematical expression recognition, while existing encoder-decoder methods are usually difficult to model global information in \LaTeX. Therefore, this paper introduces a novel approach, Implicit Character-Aided Learning (ICAL), to mine the global expression information and enhance handwritten mathematical expression recognition. Specifically, we propose the Implicit Character Construction Module (ICCM) to predict implicit character sequences and use a Fusion Module to merge the outputs of the ICCM and the decoder, thereby producing corrected predictions. By modeling and utilizing implicit character information, ICAL achieves a more accurate and context-aware interpretation of handwritten mathematical expressions. Experimental results demonstrate that ICAL notably surpasses the state-of-the-art(SOTA) models, improving the expression recognition rate (ExpRate) by 2.21\%/1.75\%/1.28\% on the CROHME 2014/2016/2019 datasets respectively, and achieves a remarkable 69.25\% on the challenging HME100k test set. We make our code available on the GitHub: https://github.com/qingzhenduyu/ICAL
Robust image segmentation model based on binary level set
Mar 20, 2024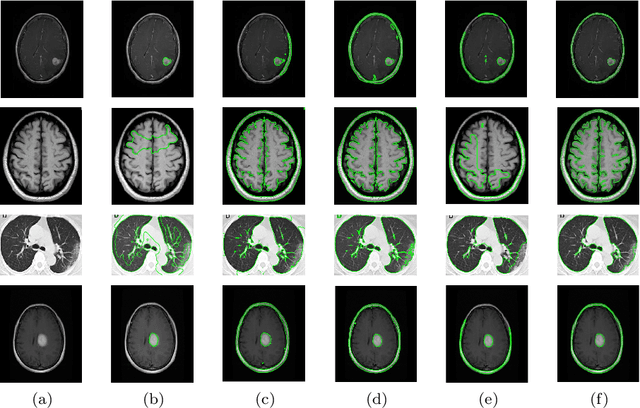

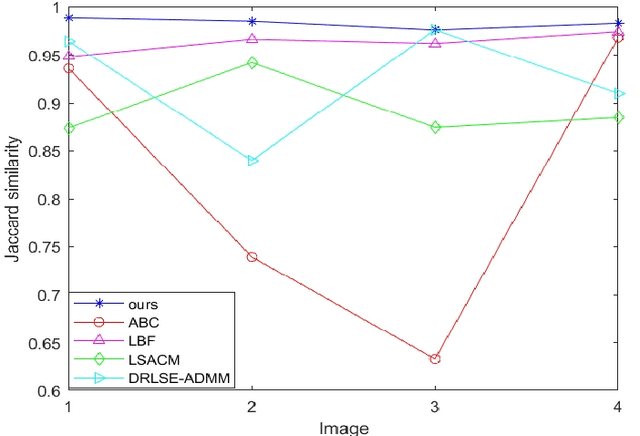
In order to improve the robustness of traditional image segmentation models to noise, this paper models the illumination term in intensity inhomogeneity images. Additionally, to enhance the model's robustness to noisy images, we incorporate the binary level set model into the proposed model. Compared to the traditional level set, the binary level set eliminates the need for continuous reinitialization. Moreover, by introducing the variational operator GL, our model demonstrates better capability in segmenting noisy images. Finally, we employ the three-step splitting operator method for solving, and the effectiveness of the proposed model is demonstrated on various images.
CoMER: Modeling Coverage for Transformer-based Handwritten Mathematical Expression Recognition
Jul 18, 2022
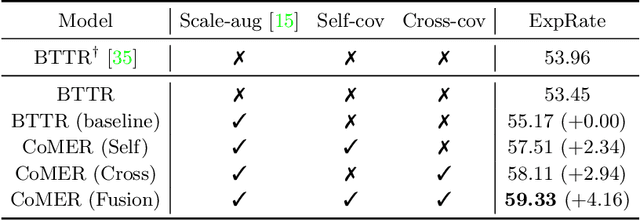
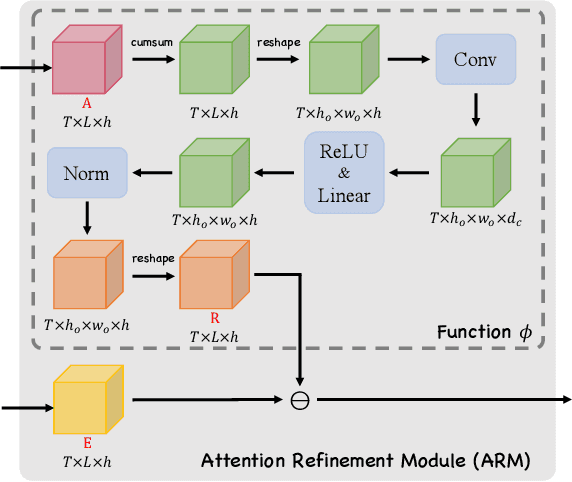
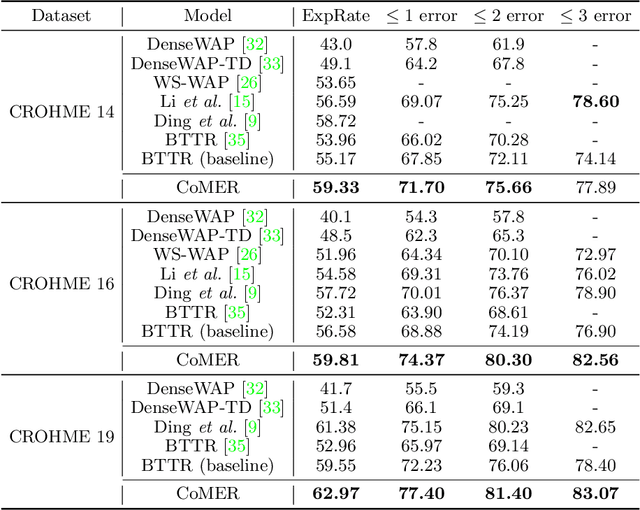
The Transformer-based encoder-decoder architecture has recently made significant advances in recognizing handwritten mathematical expressions. However, the transformer model still suffers from the lack of coverage problem, making its expression recognition rate (ExpRate) inferior to its RNN counterpart. Coverage information, which records the alignment information of the past steps, has proven effective in the RNN models. In this paper, we propose CoMER, a model that adopts the coverage information in the transformer decoder. Specifically, we propose a novel Attention Refinement Module (ARM) to refine the attention weights with past alignment information without hurting its parallelism. Furthermore, we take coverage information to the extreme by proposing self-coverage and cross-coverage, which utilize the past alignment information from the current and previous layers. Experiments show that CoMER improves the ExpRate by 0.61%/2.09%/1.59% compared to the current state-of-the-art model, and reaches 59.33%/59.81%/62.97% on the CROHME 2014/2016/2019 test sets.
Handwritten Mathematical Expression Recognition with Bidirectionally Trained Transformer
May 16, 2021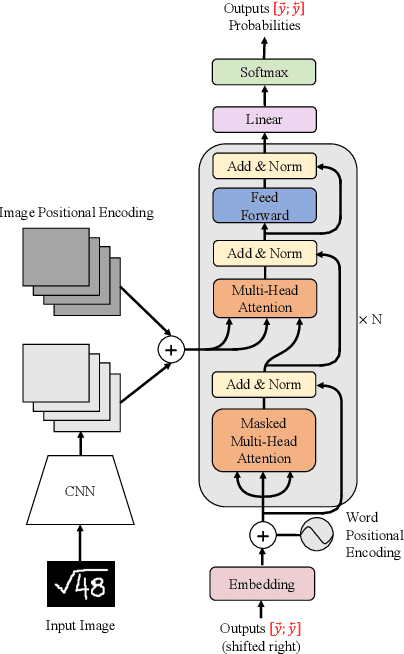



Encoder-decoder models have made great progress on handwritten mathematical expression recognition recently. However, it is still a challenge for existing methods to assign attention to image features accurately. Moreover, those encoder-decoder models usually adopt RNN-based models in their decoder part, which makes them inefficient in processing long $\LaTeX{}$ sequences. In this paper, a transformer-based decoder is employed to replace RNN-based ones, which makes the whole model architecture very concise. Furthermore, a novel training strategy is introduced to fully exploit the potential of the transformer in bidirectional language modeling. Compared to several methods that do not use data augmentation, experiments demonstrate that our model improves the ExpRate of current state-of-the-art methods on CROHME 2014 by 2.23%. Similarly, on CROHME 2016 and CROHME 2019, we improve the ExpRate by 1.92% and 2.28% respectively.