 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSource-Grounded Semantic Reinforcement Learning for Low-Resource Target-Language Generation
May 28, 2026Low-resource target-language generation is often limited by scarce parallel data, while high-resource source-language monolingual data is abundant but difficult to use with standard supervised fine-tuning. We propose Source-Grounded Semantic Reinforcement Learning (SG-SRL), a resource-utilization framework that converts source-language monolingual data into cross-lingual semantic supervision for target-language generation. SG-SRL performs reference-free reinforcement learning (RL) on source-language data using a cross-lingual semantic reward model, instantiated by a cross-lingual reranker that scores the semantic relevance between the source input and the target-language generation. While this induces severe verbosity-based reward hacking, a lightweight recovery stage using a small parallel corpus restores fluency, conciseness, and task format while preserving the semantic gains. Experiments on Chinese-to-Thai generation show that SG-SRL improves semantic grounding and factual coverage over cold-start SFT. Additional analyses on long-form transfer and Tibetan embedding-based rewards clarify the generalization behavior of SG-SRL and show that an encoder-based semantic reward can substitute for an LLM-based reranker in a realistic low-resource language setting.
FTibSuite: A Comprehensive Resource Suite for Tibetan Vision-Language Modeling
May 26, 2026Vision-language models have progressed rapidly, but Tibetan remains a severely underserved low-resource language due to the lack of reproducible training and evaluation infrastructure. To fill this gap, we introduce FTibSuite, a comprehensive resource suite for Tibetan vision-language research, consisting of FTibData (human-verified multimodal training corpora spanning continual pretraining, image-text alignment, and instruction tuning data), FTibBench (Tibetan adaptations of five mainstream multimodal benchmarks with a hierarchical quality-control workflow to reduce translation noise), and FTibVLM, a reproducible baseline built on Qwen3-VL-8B-Instruct via a three-stage adaptation pipeline. Experiments on FTibBench show FTibVLM delivers consistent performance gains across all tasks, such as improving MMBench accuracy from 42.97 to 67.78 and POPE-random accuracy from 47.53 to 80.56, while retaining the backbone's original Chinese capabilities with minimal degradation, providing the first standardized foundation for Tibetan multimodal research.
Reinforcement Learning with Semantic Rewards Enables Low-Resource Language Expansion without Alignment Tax
May 14, 2026Extending large language models (LLMs) to low-resource languages often incurs an "alignment tax": improvements in the target language come at the cost of catastrophic forgetting in general capabilities. We argue that this trade-off arises from the rigidity of supervised fine-tuning (SFT), which enforces token-level surface imitation on narrow and biased data distributions. To address this limitation, we propose a semantic-space alignment paradigm powered by Group Relative Policy Optimization (GRPO), where the model is optimized using embedding-level semantic rewards rather than likelihood maximization. This objective encourages meaning preservation through flexible realizations, enabling controlled updates that reduce destructive interference with pretrained knowledge. We evaluate our approach on Tibetan-Chinese machine translation and Tibetan headline generation. Experiments show that our method acquires low-resource capabilities while markedly mitigating alignment tax, preserving general competence more effectively than SFT. Despite producing less rigid surface overlap, semantic RL yields higher semantic quality and preference in open-ended generation, and few-shot transfer results indicate that it learns more transferable and robust representations under limited supervision. Overall, our study demonstrates that reinforcement learning with semantic rewards provides a safer and more reliable pathway for inclusive low-resource language expansion.
ML-Embed: Inclusive and Efficient Embeddings for a Multilingual World
May 14, 2026The development of high-quality text embeddings is increasingly drifting toward an exclusionary future, defined by three critical barriers: prohibitive computational costs, a narrow linguistic focus that neglects most of the world's languages, and a lack of transparency from closed-source or open-weight models that stifles research. To dismantle these barriers, we introduce ML-Embed, a suite of inclusive and efficient models built upon a new framework: 3-Dimensional Matryoshka Learning (3D-ML). Our framework addresses the computational challenge with comprehensive efficiency across the entire model lifecycle. Beyond the storage benefits of Matryoshka Representation Learning (MRL) and flexible inference-time depth provided by Matryoshka Layer Learning (MLL), we introduce Matryoshka Embedding Learning (MEL) for enhanced parameter efficiency. To address the linguistic challenge, we curate a massively multilingual dataset and train a suite of models ranging from 140M to 8B parameters. In a direct commitment to transparency, we release all models, data, and code. Extensive evaluation on 430 tasks demonstrates that our models set new records on 9 of 17 evaluated MTEB benchmarks, with particularly strong results in low-resource languages, providing a reproducible blueprint for building globally equitable and computationally efficient AI systems.
Beyond Retrieval: A Multitask Benchmark and Model for Code Search
May 06, 2026Code search has usually been evaluated as first-stage retrieval, even though production systems rely on broader pipelines with reranking and developer-style queries. Existing benchmarks also suffer from data contamination, label noise, and degenerate binary relevance. In this paper, we introduce \textsc{CoREB}, a contamination-limited, multitask \underline{co}de \underline{r}etrieval and r\underline{e}ranking \underline{b}enchmark, together with a fine-tuned code reranker, that goes beyond retrieval to cover the full code search pipeline. \textsc{CoREB} is built from counterfactually rewritten LiveCodeBench problems in five programming languages and delivered as timed releases with graded relevance judgments. We benchmark eleven embedding models and five rerankers across three tasks: text-to-code, code-to-text, and code-to-code. Our experiments reveal that: \circone code-specialised embeddings dominate code-to-code retrieval (${\sim}2{\times}$ over general encoders), yet no single model wins all three tasks; \circtwo short keyword queries, the format closest to real developer search, collapse every model to near-zero nDCG@10; \circthree off-the-shelf rerankers are task-asymmetric, with a 12-point swing on code-to-code and no baseline net-positive across all tasks; \circfour our fine-tuned \textsc{CoREB-Reranker} is the first to achieve consistent gains across all three tasks. The data and model are released.
TingIS: Real-time Risk Event Discovery from Noisy Customer Incidents at Enterprise Scale
Apr 23, 2026Real-time detection and mitigation of technical anomalies are critical for large-scale cloud-native services, where even minutes of downtime can result in massive financial losses and diminished user trust. While customer incidents serve as a vital signal for discovering risks missed by monitoring, extracting actionable intelligence from this data remains challenging due to extreme noise, high throughput, and semantic complexity of diverse business lines. In this paper, we present TingIS, an end-to-end system designed for enterprise-grade incident discovery. At the core of TingIS is a multi-stage event linking engine that synergizes efficient indexing techniques with Large Language Models (LLMs) to make informed decisions on event merging, enabling the stable extraction of actionable incidents from just a handful of diverse user descriptions. This engine is complemented by a cascaded routing mechanism for precise business attribution and a multi-dimensional noise reduction pipeline that integrates domain knowledge, statistical patterns, and behavioral filtering. Deployed in a production environment handling a peak throughput of over 2,000 messages per minute and 300,000 messages per day, TingIS achieves a P90 alert latency of 3.5 minutes and a 95\% discovery rate for high-priority incidents. Benchmarks constructed from real-world data demonstrate that TingIS significantly outperforms baseline methods in routing accuracy, clustering quality, and Signal-to-Noise Ratio.
F2LLM-v2: Inclusive, Performant, and Efficient Embeddings for a Multilingual World
Mar 19, 2026We present F2LLM-v2, a new family of general-purpose, multilingual embedding models in 8 distinct sizes ranging from 80M to 14B. Trained on a newly curated composite of 60 million publicly available high-quality data samples, F2LLM-v2 supports more than 200 languages, with a particular emphasis on previously underserved mid- and low-resource languages. By integrating a two-stage LLM-based embedding training pipeline with matryoshka learning, model pruning, and knowledge distillation techniques, we present models that are far more efficient than previous LLM-based embedding models while retaining competitive performances. Extensive evaluations confirm that F2LLM-v2-14B ranks first on 11 MTEB benchmarks, while the smaller models in the family also set a new state of the art for resource-constrained applications. To facilitate open-source embedding model research, we release all models, data, code, and intermediate checkpoints.
C2LLM Technical Report: A New Frontier in Code Retrieval via Adaptive Cross-Attention Pooling
Dec 24, 2025We present C2LLM - Contrastive Code Large Language Models, a family of code embedding models in both 0.5B and 7B sizes. Building upon Qwen-2.5-Coder backbones, C2LLM adopts a Pooling by Multihead Attention (PMA) module for generating sequence embedding from token embeddings, effectively 1) utilizing the LLM's causal representations acquired during pretraining, while also 2) being able to aggregate information from all tokens in the sequence, breaking the information bottleneck in EOS-based sequence embeddings, and 3) supporting flexible adaptation of embedding dimension, serving as an alternative to MRL. Trained on three million publicly available data, C2LLM models set new records on MTEB-Code among models of similar sizes, with C2LLM-7B ranking 1st on the overall leaderboard.
F2LLM Technical Report: Matching SOTA Embedding Performance with 6 Million Open-Source Data
Oct 02, 2025

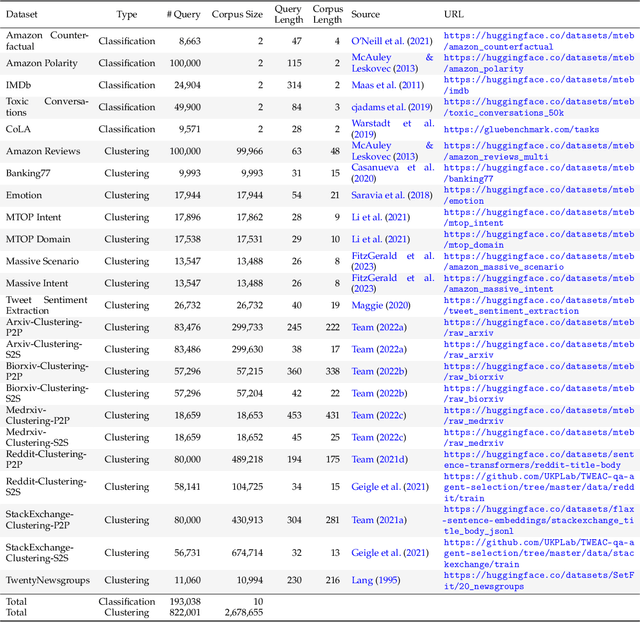
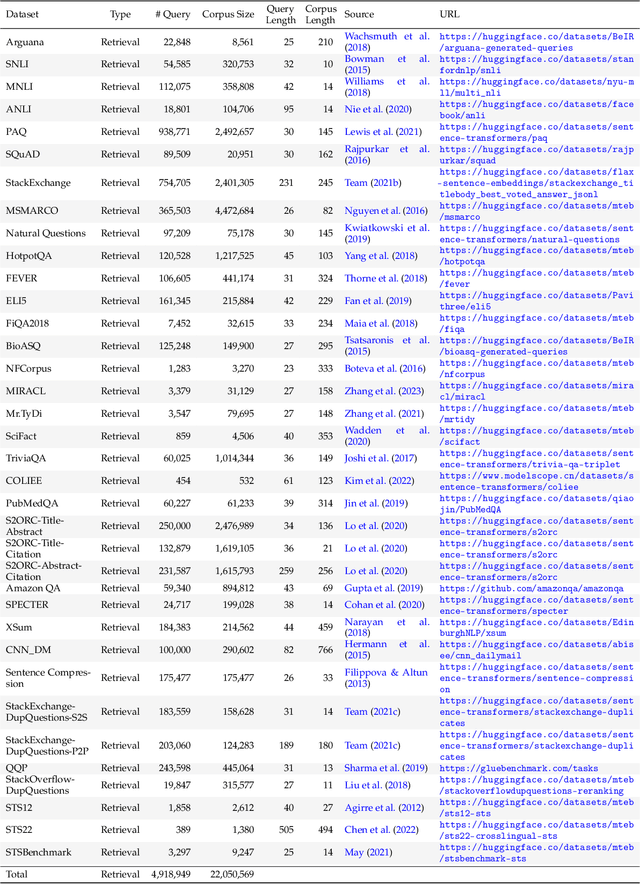
We introduce F2LLM - Foundation to Feature Large Language Models, a suite of state-of-the-art embedding models in three sizes: 0.6B, 1.7B, and 4B. Unlike previous top-ranking embedding models that require massive contrastive pretraining, sophisticated training pipelines, and costly synthetic training data, F2LLM is directly finetuned from foundation models on 6 million query-document-negative tuples curated from open-source, non-synthetic datasets, striking a strong balance between training cost, model size, and embedding performance. On the MTEB English leaderboard, F2LLM-4B ranks 2nd among models with approximately 4B parameters and 7th overall, while F2LLM-1.7B ranks 1st among models in the 1B-2B size range. To facilitate future research in the field, we release the models, training dataset, and code, positioning F2LLM as a strong, reproducible, and budget-friendly baseline for future works.
DeepTheorem: Advancing LLM Reasoning for Theorem Proving Through Natural Language and Reinforcement Learning
May 29, 2025


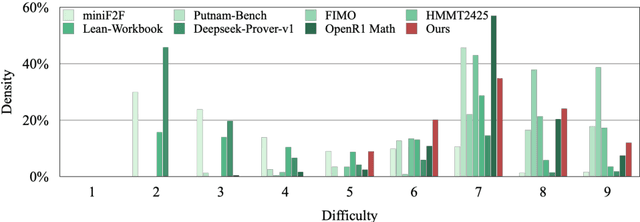
Theorem proving serves as a major testbed for evaluating complex reasoning abilities in large language models (LLMs). However, traditional automated theorem proving (ATP) approaches rely heavily on formal proof systems that poorly align with LLMs' strength derived from informal, natural language knowledge acquired during pre-training. In this work, we propose DeepTheorem, a comprehensive informal theorem-proving framework exploiting natural language to enhance LLM mathematical reasoning. DeepTheorem includes a large-scale benchmark dataset consisting of 121K high-quality IMO-level informal theorems and proofs spanning diverse mathematical domains, rigorously annotated for correctness, difficulty, and topic categories, accompanied by systematically constructed verifiable theorem variants. We devise a novel reinforcement learning strategy (RL-Zero) explicitly tailored to informal theorem proving, leveraging the verified theorem variants to incentivize robust mathematical inference. Additionally, we propose comprehensive outcome and process evaluation metrics examining proof correctness and the quality of reasoning steps. Extensive experimental analyses demonstrate DeepTheorem significantly improves LLM theorem-proving performance compared to existing datasets and supervised fine-tuning protocols, achieving state-of-the-art accuracy and reasoning quality. Our findings highlight DeepTheorem's potential to fundamentally advance automated informal theorem proving and mathematical exploration.