 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCBench: A Sports Commentary Benchmark for Video LLMs
Dec 23, 2024Recently, significant advances have been made in Video Large Language Models (Video LLMs) in both academia and industry. However, methods to evaluate and benchmark the performance of different Video LLMs, especially their fine-grained, temporal visual capabilities, remain very limited. On one hand, current benchmarks use relatively simple videos (e.g., subtitled movie clips) where the model can understand the entire video by processing just a few frames. On the other hand, their datasets lack diversity in task format, comprising only QA or multi-choice QA, which overlooks the models' capacity for generating in-depth and precise texts. Sports videos, which feature intricate visual information, sequential events, and emotionally charged commentary, present a critical challenge for Video LLMs, making sports commentary an ideal benchmarking task. Inspired by these challenges, we propose a novel task: sports video commentary generation, developed $\textbf{SCBench}$ for Video LLMs. To construct such a benchmark, we introduce (1) $\textbf{SCORES}$, a six-dimensional metric specifically designed for our task, upon which we propose a GPT-based evaluation method, and (2) $\textbf{CommentarySet}$, a dataset consisting of 5,775 annotated video clips and ground-truth labels tailored to our metric. Based on SCBench, we conduct comprehensive evaluations on multiple Video LLMs (e.g. VILA, Video-LLaVA, etc.) and chain-of-thought baseline methods. Our results found that InternVL-Chat-2 achieves the best performance with 5.44, surpassing the second-best by 1.04. Our work provides a fresh perspective for future research, aiming to enhance models' overall capabilities in complex visual understanding tasks. Our dataset will be released soon.
Is Cognition and Action Consistent or Not: Investigating Large Language Model's Personality
Feb 22, 2024In this study, we investigate the reliability of Large Language Models (LLMs) in professing human-like personality traits through responses to personality questionnaires. Our goal is to evaluate the consistency between LLMs' professed personality inclinations and their actual "behavior", examining the extent to which these models can emulate human-like personality patterns. Through a comprehensive analysis of LLM outputs against established human benchmarks, we seek to understand the cognition-action divergence in LLMs and propose hypotheses for the observed results based on psychological theories and metrics.
A Supervised Learning Approach for Robust Health Monitoring using Face Videos
Jan 30, 2021
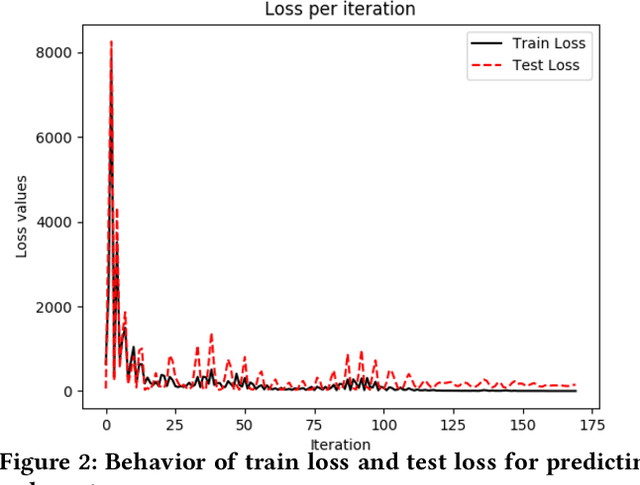

Monitoring of cardiovascular activity is highly desired and can enable novel applications in diagnosing potential cardiovascular diseases and maintaining an individual's well-being. Currently, such vital signs are measured using intrusive contact devices such as an electrocardiogram (ECG), chest straps, and pulse oximeters that require the patient or the health provider to manually implement. Non-contact, device-free human sensing methods can eliminate the need for specialized heart and blood pressure monitoring equipment. Non-contact methods can have additional advantages since they are scalable with any environment where video can be captured, can be used for continuous measurements, and can be used on patients with varying levels of dexterity and independence, from people with physical impairments to infants (e.g., baby camera). In this paper, we used a non-contact method that only requires face videos recorded using commercially-available webcams. These videos were exploited to predict the health attributes like pulse rate and variance in pulse rate. The proposed approach used facial recognition to detect the face in each frame of the video using facial landmarks, followed by supervised learning using deep neural networks to train the machine learning model. The videos captured subjects performing different physical activities that result in varying cardiovascular responses. The proposed method did not require training data from every individual and thus the prediction can be obtained for the new individuals for which there is no prior data; critical in approach generalization. The approach was also evaluated on a dataset of people with different ethnicity. The proposed approach had less than a 4.6\% error in predicting the pulse rate.
* The main part of the paper appeared in DFHS'20: Proceedings of the 2nd ACM Workshop on Device-Free Human Sensing; while the Supplementary did not appear in the proceedings