 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Training-Free Guess What Vision Language Model from Snippets to Open-Vocabulary Object Detection
Jan 21, 2026Open-Vocabulary Object Detection (OVOD) aims to develop the capability to detect anything. Although myriads of large-scale pre-training efforts have built versatile foundation models that exhibit impressive zero-shot capabilities to facilitate OVOD, the necessity of creating a universal understanding for any object cognition according to already pretrained foundation models is usually overlooked. Therefore, in this paper, a training-free Guess What Vision Language Model, called GW-VLM, is proposed to form a universal understanding paradigm based on our carefully designed Multi-Scale Visual Language Searching (MS-VLS) coupled with Contextual Concept Prompt (CCP) for OVOD. This approach can engage a pre-trained Vision Language Model (VLM) and a Large Language Model (LLM) in the game of "guess what". Wherein, MS-VLS leverages multi-scale visual-language soft-alignment for VLM to generate snippets from the results of class-agnostic object detection, while CCP can form the concept of flow referring to MS-VLS and then make LLM understand snippets for OVOD. Finally, the extensive experiments are carried out on natural and remote sensing datasets, including COCO val, Pascal VOC, DIOR, and NWPU-10, and the results indicate that our proposed GW-VLM can achieve superior OVOD performance compared to the-state-of-the-art methods without any training step.
SCBench: A Sports Commentary Benchmark for Video LLMs
Dec 23, 2024Recently, significant advances have been made in Video Large Language Models (Video LLMs) in both academia and industry. However, methods to evaluate and benchmark the performance of different Video LLMs, especially their fine-grained, temporal visual capabilities, remain very limited. On one hand, current benchmarks use relatively simple videos (e.g., subtitled movie clips) where the model can understand the entire video by processing just a few frames. On the other hand, their datasets lack diversity in task format, comprising only QA or multi-choice QA, which overlooks the models' capacity for generating in-depth and precise texts. Sports videos, which feature intricate visual information, sequential events, and emotionally charged commentary, present a critical challenge for Video LLMs, making sports commentary an ideal benchmarking task. Inspired by these challenges, we propose a novel task: sports video commentary generation, developed $\textbf{SCBench}$ for Video LLMs. To construct such a benchmark, we introduce (1) $\textbf{SCORES}$, a six-dimensional metric specifically designed for our task, upon which we propose a GPT-based evaluation method, and (2) $\textbf{CommentarySet}$, a dataset consisting of 5,775 annotated video clips and ground-truth labels tailored to our metric. Based on SCBench, we conduct comprehensive evaluations on multiple Video LLMs (e.g. VILA, Video-LLaVA, etc.) and chain-of-thought baseline methods. Our results found that InternVL-Chat-2 achieves the best performance with 5.44, surpassing the second-best by 1.04. Our work provides a fresh perspective for future research, aiming to enhance models' overall capabilities in complex visual understanding tasks. Our dataset will be released soon.
MR-MLLM: Mutual Reinforcement of Multimodal Comprehension and Vision Perception
Jun 22, 2024



In recent years, multimodal large language models (MLLMs) have shown remarkable capabilities in tasks like visual question answering and common sense reasoning, while visual perception models have made significant strides in perception tasks, such as detection and segmentation. However, MLLMs mainly focus on high-level image-text interpretations and struggle with fine-grained visual understanding, and vision perception models usually suffer from open-world distribution shifts due to their limited model capacity. To overcome these challenges, we propose the Mutually Reinforced Multimodal Large Language Model (MR-MLLM), a novel framework that synergistically enhances visual perception and multimodal comprehension. First, a shared query fusion mechanism is proposed to harmonize detailed visual inputs from vision models with the linguistic depth of language models, enhancing multimodal comprehension and vision perception synergistically. Second, we propose the perception-enhanced cross-modal integration method, incorporating novel modalities from vision perception outputs, like object detection bounding boxes, to capture subtle visual elements, thus enriching the understanding of both visual and textual data. In addition, an innovative perception-embedded prompt generation mechanism is proposed to embed perceptual information into the language model's prompts, aligning the responses contextually and perceptually for a more accurate multimodal interpretation. Extensive experiments demonstrate MR-MLLM's superior performance in various multimodal comprehension and vision perception tasks, particularly those requiring corner case vision perception and fine-grained language comprehension.
Self-Corrected Multimodal Large Language Model for End-to-End Robot Manipulation
May 27, 2024



Robot manipulation policies have shown unsatisfactory action performance when confronted with novel task or object instances. Hence, the capability to automatically detect and self-correct failure action is essential for a practical robotic system. Recently, Multimodal Large Language Models (MLLMs) have shown promise in visual instruction following and demonstrated strong reasoning abilities in various tasks. To unleash general MLLMs as an end-to-end robotic agent, we introduce a Self-Corrected (SC)-MLLM, equipping our model not only to predict end-effector poses but also to autonomously recognize and correct failure actions. Specifically, we first conduct parameter-efficient fine-tuning to empower MLLM with pose prediction ability, which is reframed as a language modeling problem. When facing execution failures, our model learns to identify low-level action error causes (i.e., position and rotation errors) and adaptively seeks prompt feedback from experts. Based on the feedback, SC-MLLM rethinks the current failure scene and generates the corrected actions. Furthermore, we design a continuous policy learning method for successfully corrected samples, enhancing the model's adaptability to the current scene configuration and reducing the frequency of expert intervention. To evaluate our SC-MLLM, we conduct extensive experiments in both simulation and real-world settings. SC-MLLM agent significantly improve manipulation accuracy compared to previous state-of-the-art robotic MLLM (ManipLLM), increasing from 57\% to 79\% on seen object categories and from 47\% to 69\% on unseen novel categories.
Cloud-Device Collaborative Learning for Multimodal Large Language Models
Dec 26, 2023



The burgeoning field of Multimodal Large Language Models (MLLMs) has exhibited remarkable performance in diverse tasks such as captioning, commonsense reasoning, and visual scene understanding. However, the deployment of these large-scale MLLMs on client devices is hindered by their extensive model parameters, leading to a notable decline in generalization capabilities when these models are compressed for device deployment. Addressing this challenge, we introduce a Cloud-Device Collaborative Continual Adaptation framework, designed to enhance the performance of compressed, device-deployed MLLMs by leveraging the robust capabilities of cloud-based, larger-scale MLLMs. Our framework is structured into three key components: a device-to-cloud uplink for efficient data transmission, cloud-based knowledge adaptation, and an optimized cloud-to-device downlink for model deployment. In the uplink phase, we employ an Uncertainty-guided Token Sampling (UTS) strategy to effectively filter out-of-distribution tokens, thereby reducing transmission costs and improving training efficiency. On the cloud side, we propose Adapter-based Knowledge Distillation (AKD) method to transfer refined knowledge from large-scale to compressed, pocket-size MLLMs. Furthermore, we propose a Dynamic Weight update Compression (DWC) strategy for the downlink, which adaptively selects and quantizes updated weight parameters, enhancing transmission efficiency and reducing the representational disparity between cloud and device models. Extensive experiments on several multimodal benchmarks demonstrate the superiority of our proposed framework over prior Knowledge Distillation and device-cloud collaboration methods. Notably, we also validate the feasibility of our approach to real-world experiments.
Consecutive Pretraining: A Knowledge Transfer Learning Strategy with Relevant Unlabeled Data for Remote Sensing Domain
Jul 08, 2022


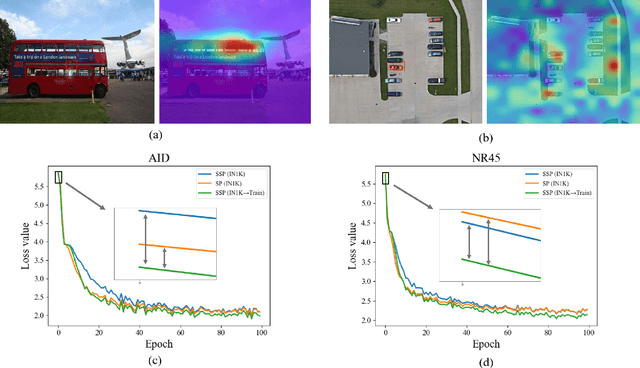
Currently, under supervised learning, a model pretrained by a large-scale nature scene dataset and then fine-tuned on a few specific task labeling data is the paradigm that has dominated the knowledge transfer learning. It has reached the status of consensus solution for task-aware model training in remote sensing domain (RSD). Unfortunately, due to different categories of imaging data and stiff challenges of data annotation, there is not a large enough and uniform remote sensing dataset to support large-scale pretraining in RSD. Moreover, pretraining models on large-scale nature scene datasets by supervised learning and then directly fine-tuning on diverse downstream tasks seems to be a crude method, which is easily affected by inevitable labeling noise, severe domain gaps and task-aware discrepancies. Thus, in this paper, considering the self-supervised pretraining and powerful vision transformer (ViT) architecture, a concise and effective knowledge transfer learning strategy called ConSecutive PreTraining (CSPT) is proposed based on the idea of not stopping pretraining in natural language processing (NLP), which can gradually bridge the domain gap and transfer knowledge from the nature scene domain to the RSD. The proposed CSPT also can release the huge potential of unlabeled data for task-aware model training. Finally, extensive experiments are carried out on twelve datasets in RSD involving three types of downstream tasks (e.g., scene classification, object detection and land cover classification) and two types of imaging data (e.g., optical and SAR). The results show that by utilizing the proposed CSPT for task-aware model training, almost all downstream tasks in RSD can outperform the previous method of supervised pretraining-then-fine-tuning and even surpass the state-of-the-art (SOTA) performance without any expensive labeling consumption and careful model design.