 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Thinker: A General Reasoning Modular Core for Image Generation
Jan 06, 2026Despite impressive progress in high-fidelity image synthesis, generative models still struggle with logic-intensive instruction following, exposing a persistent reasoning--execution gap. Meanwhile, closed-source systems (e.g., Nano Banana) have demonstrated strong reasoning-driven image generation, highlighting a substantial gap to current open-source models. We argue that closing this gap requires not merely better visual generators, but executable reasoning: decomposing high-level intents into grounded, verifiable plans that directly steer the generative process. To this end, we propose Unified Thinker, a task-agnostic reasoning architecture for general image generation, designed as a unified planning core that can plug into diverse generators and workflows. Unified Thinker decouples a dedicated Thinker from the image Generator, enabling modular upgrades of reasoning without retraining the entire generative model. We further introduce a two-stage training paradigm: we first build a structured planning interface for the Thinker, then apply reinforcement learning to ground its policy in pixel-level feedback, encouraging plans that optimize visual correctness over textual plausibility. Extensive experiments on text-to-image generation and image editing show that Unified Thinker substantially improves image reasoning and generation quality.
AndroidLens: Long-latency Evaluation with Nested Sub-targets for Android GUI Agents
Dec 24, 2025Graphical user interface (GUI) agents can substantially improve productivity by automating frequently executed long-latency tasks on mobile devices. However, existing evaluation benchmarks are still constrained to limited applications, simple tasks, and coarse-grained metrics. To address this, we introduce AndroidLens, a challenging evaluation framework for mobile GUI agents, comprising 571 long-latency tasks in both Chinese and English environments, each requiring an average of more than 26 steps to complete. The framework features: (1) tasks derived from real-world user scenarios across 38 domains, covering complex types such as multi-constraint, multi-goal, and domain-specific tasks; (2) static evaluation that preserves real-world anomalies and allows multiple valid paths to reduce bias; and (3) dynamic evaluation that employs a milestone-based scheme for fine-grained progress measurement via Average Task Progress (ATP). Our evaluation indicates that even the best models reach only a 12.7% task success rate and 50.47% ATP. We also underscore key challenges in real-world environments, including environmental anomalies, adaptive exploration, and long-term memory retention.
IPCV: Information-Preserving Compression for MLLM Visual Encoders
Dec 21, 2025



Multimodal Large Language Models (MLLMs) deliver strong vision-language performance but at high computational cost, driven by numerous visual tokens processed by the Vision Transformer (ViT) encoder. Existing token pruning strategies are inadequate: LLM-stage token pruning overlooks the ViT's overhead, while conventional ViT token pruning, without language guidance, risks discarding textually critical visual cues and introduces feature distortions amplified by the ViT's bidirectional attention. To meet these challenges, we propose IPCV, a training-free, information-preserving compression framework for MLLM visual encoders. IPCV enables aggressive token pruning inside the ViT via Neighbor-Guided Reconstruction (NGR) that temporarily reconstructs pruned tokens to participate in attention with minimal overhead, then fully restores them before passing to the LLM. Besides, we introduce Attention Stabilization (AS) to further alleviate the negative influence from token pruning by approximating the K/V of pruned tokens. It can be directly applied to previous LLM-side token pruning methods to enhance their performance. Extensive experiments show that IPCV substantially reduces end-to-end computation and outperforms state-of-the-art training-free token compression methods across diverse image and video benchmarks. Our code is available at https://github.com/Perkzi/IPCV.
MMG-Vid: Maximizing Marginal Gains at Segment-level and Token-level for Efficient Video LLMs
Aug 28, 2025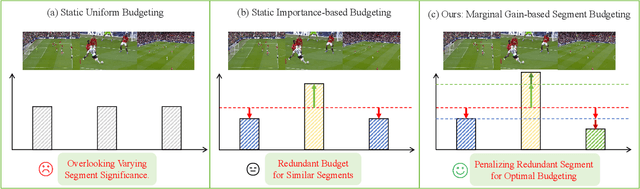
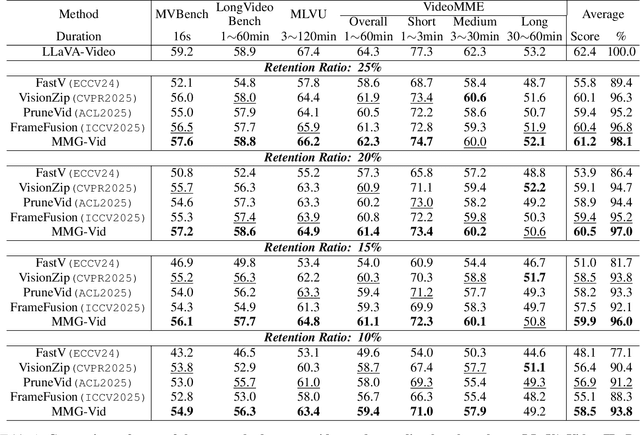
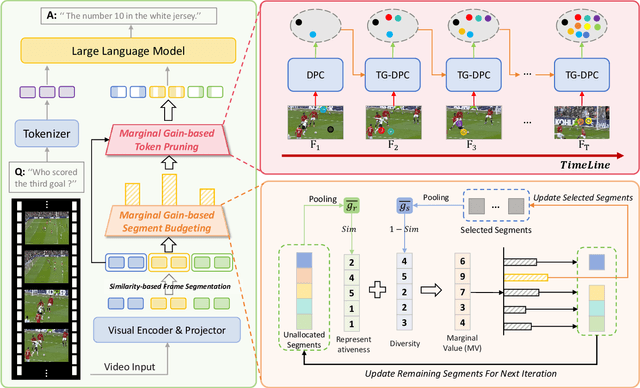
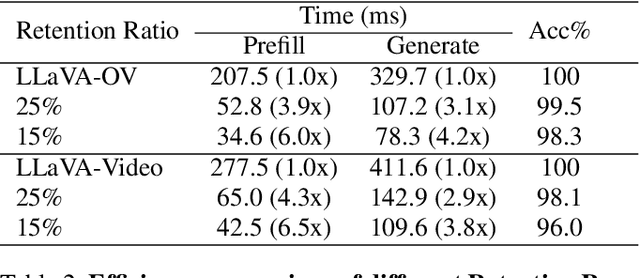
Video Large Language Models (VLLMs) excel in video understanding, but their excessive visual tokens pose a significant computational challenge for real-world applications. Current methods aim to enhance inference efficiency by visual token pruning. However, they do not consider the dynamic characteristics and temporal dependencies of video frames, as they perceive video understanding as a multi-frame task. To address these challenges, we propose MMG-Vid, a novel training-free visual token pruning framework that removes redundancy by Maximizing Marginal Gains at both segment-level and token-level. Specifically, we first divide the video into segments based on frame similarity, and then dynamically allocate the token budget for each segment to maximize the marginal gain of each segment. Subsequently, we propose a temporal-guided DPC algorithm that jointly models inter-frame uniqueness and intra-frame diversity, thereby maximizing the marginal gain of each token. By combining both stages, MMG-Vid can maximize the utilization of the limited token budget, significantly improving efficiency while maintaining strong performance. Extensive experiments demonstrate that MMG-Vid can maintain over 99.5% of the original performance, while effectively reducing 75% visual tokens and accelerating the prefilling stage by 3.9x on LLaVA-OneVision-7B. Code will be released soon.
Video Compression Commander: Plug-and-Play Inference Acceleration for Video Large Language Models
May 20, 2025Video large language models (VideoLLM) excel at video understanding, but face efficiency challenges due to the quadratic complexity of abundant visual tokens. Our systematic analysis of token compression methods for VideoLLMs reveals two critical issues: (i) overlooking distinctive visual signals across frames, leading to information loss; (ii) suffering from implementation constraints, causing incompatibility with modern architectures or efficient operators. To address these challenges, we distill three design principles for VideoLLM token compression and propose a plug-and-play inference acceleration framework "Video Compression Commander" (VidCom2). By quantifying each frame's uniqueness, VidCom2 adaptively adjusts compression intensity across frames, effectively preserving essential information while reducing redundancy in video sequences. Extensive experiments across various VideoLLMs and benchmarks demonstrate the superior performance and efficiency of our VidCom2. With only 25% visual tokens, VidCom2 achieves 99.6% of the original performance on LLaVA-OV while reducing 70.8% of the LLM generation latency. Notably, our Frame Compression Adjustment strategy is compatible with other token compression methods to further improve their performance. Our code is available at https://github.com/xuyang-liu16/VidCom2.
SparseVLM: Visual Token Sparsification for Efficient Vision-Language Model Inference
Oct 06, 2024



In vision-language models (VLMs), visual tokens usually consume a significant amount of computational overhead, despite their sparser information density compared to text tokens. To address this, most existing methods learn a network to prune redundant visual tokens and require additional training data. Differently, we propose an efficient training-free token optimization mechanism dubbed SparseVLM without extra parameters or fine-tuning costs. Concretely, given that visual tokens complement text tokens in VLMs for linguistic reasoning, we select visual-relevant text tokens to rate the significance of vision tokens within the self-attention matrix extracted from the VLMs. Then we progressively prune irrelevant tokens. To maximize sparsity while retaining essential information, we introduce a rank-based strategy to adaptively determine the sparsification ratio for each layer, alongside a token recycling method that compresses pruned tokens into more compact representations. Experimental results show that our SparseVLM improves the efficiency of various VLMs across a range of image and video understanding tasks. In particular, LLaVA equipped with SparseVLM reduces 61% to 67% FLOPs with a compression ratio of 78% while maintaining 93% of the accuracy. Our code is available at https://github.com/Gumpest/SparseVLMs.
Cloud-Device Collaborative Learning for Multimodal Large Language Models
Dec 26, 2023



The burgeoning field of Multimodal Large Language Models (MLLMs) has exhibited remarkable performance in diverse tasks such as captioning, commonsense reasoning, and visual scene understanding. However, the deployment of these large-scale MLLMs on client devices is hindered by their extensive model parameters, leading to a notable decline in generalization capabilities when these models are compressed for device deployment. Addressing this challenge, we introduce a Cloud-Device Collaborative Continual Adaptation framework, designed to enhance the performance of compressed, device-deployed MLLMs by leveraging the robust capabilities of cloud-based, larger-scale MLLMs. Our framework is structured into three key components: a device-to-cloud uplink for efficient data transmission, cloud-based knowledge adaptation, and an optimized cloud-to-device downlink for model deployment. In the uplink phase, we employ an Uncertainty-guided Token Sampling (UTS) strategy to effectively filter out-of-distribution tokens, thereby reducing transmission costs and improving training efficiency. On the cloud side, we propose Adapter-based Knowledge Distillation (AKD) method to transfer refined knowledge from large-scale to compressed, pocket-size MLLMs. Furthermore, we propose a Dynamic Weight update Compression (DWC) strategy for the downlink, which adaptively selects and quantizes updated weight parameters, enhancing transmission efficiency and reducing the representational disparity between cloud and device models. Extensive experiments on several multimodal benchmarks demonstrate the superiority of our proposed framework over prior Knowledge Distillation and device-cloud collaboration methods. Notably, we also validate the feasibility of our approach to real-world experiments.