 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboMIND 2.0: A Multimodal, Bimanual Mobile Manipulation Dataset for Generalizable Embodied Intelligence
Dec 31, 2025While data-driven imitation learning has revolutionized robotic manipulation, current approaches remain constrained by the scarcity of large-scale, diverse real-world demonstrations. Consequently, the ability of existing models to generalize across long-horizon bimanual tasks and mobile manipulation in unstructured environments remains limited. To bridge this gap, we present RoboMIND 2.0, a comprehensive real-world dataset comprising over 310K dual-arm manipulation trajectories collected across six distinct robot embodiments and 739 complex tasks. Crucially, to support research in contact-rich and spatially extended tasks, the dataset incorporates 12K tactile-enhanced episodes and 20K mobile manipulation trajectories. Complementing this physical data, we construct high-fidelity digital twins of our real-world environments, releasing an additional 20K-trajectory simulated dataset to facilitate robust sim-to-real transfer. To fully exploit the potential of RoboMIND 2.0, we propose MIND-2 system, a hierarchical dual-system frame-work optimized via offline reinforcement learning. MIND-2 integrates a high-level semantic planner (MIND-2-VLM) to decompose abstract natural language instructions into grounded subgoals, coupled with a low-level Vision-Language-Action executor (MIND-2-VLA), which generates precise, proprioception-aware motor actions.
SparseVLM: Visual Token Sparsification for Efficient Vision-Language Model Inference
Oct 06, 2024



In vision-language models (VLMs), visual tokens usually consume a significant amount of computational overhead, despite their sparser information density compared to text tokens. To address this, most existing methods learn a network to prune redundant visual tokens and require additional training data. Differently, we propose an efficient training-free token optimization mechanism dubbed SparseVLM without extra parameters or fine-tuning costs. Concretely, given that visual tokens complement text tokens in VLMs for linguistic reasoning, we select visual-relevant text tokens to rate the significance of vision tokens within the self-attention matrix extracted from the VLMs. Then we progressively prune irrelevant tokens. To maximize sparsity while retaining essential information, we introduce a rank-based strategy to adaptively determine the sparsification ratio for each layer, alongside a token recycling method that compresses pruned tokens into more compact representations. Experimental results show that our SparseVLM improves the efficiency of various VLMs across a range of image and video understanding tasks. In particular, LLaVA equipped with SparseVLM reduces 61% to 67% FLOPs with a compression ratio of 78% while maintaining 93% of the accuracy. Our code is available at https://github.com/Gumpest/SparseVLMs.
Unveiling the Tapestry of Consistency in Large Vision-Language Models
May 23, 2024Large vision-language models (LVLMs) have recently achieved rapid progress, exhibiting great perception and reasoning abilities concerning visual information. However, when faced with prompts in different sizes of solution spaces, LVLMs fail to always give consistent answers regarding the same knowledge point. This inconsistency of answers between different solution spaces is prevalent in LVLMs and erodes trust. To this end, we provide a multi-modal benchmark ConBench, to intuitively analyze how LVLMs perform when the solution space of a prompt revolves around a knowledge point. Based on the ConBench tool, we are the first to reveal the tapestry and get the following findings: (1) In the discriminate realm, the larger the solution space of the prompt, the lower the accuracy of the answers. (2) Establish the relationship between the discriminative and generative realms: the accuracy of the discriminative question type exhibits a strong positive correlation with its Consistency with the caption. (3) Compared to open-source models, closed-source models exhibit a pronounced bias advantage in terms of Consistency. Eventually, we ameliorate the consistency of LVLMs by trigger-based diagnostic refinement, indirectly improving the performance of their caption. We hope this paper will accelerate the research community in better evaluating their models and encourage future advancements in the consistency domain.
FreeKD: Knowledge Distillation via Semantic Frequency Prompt
Nov 20, 2023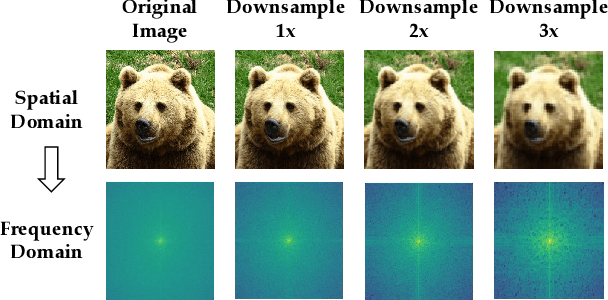
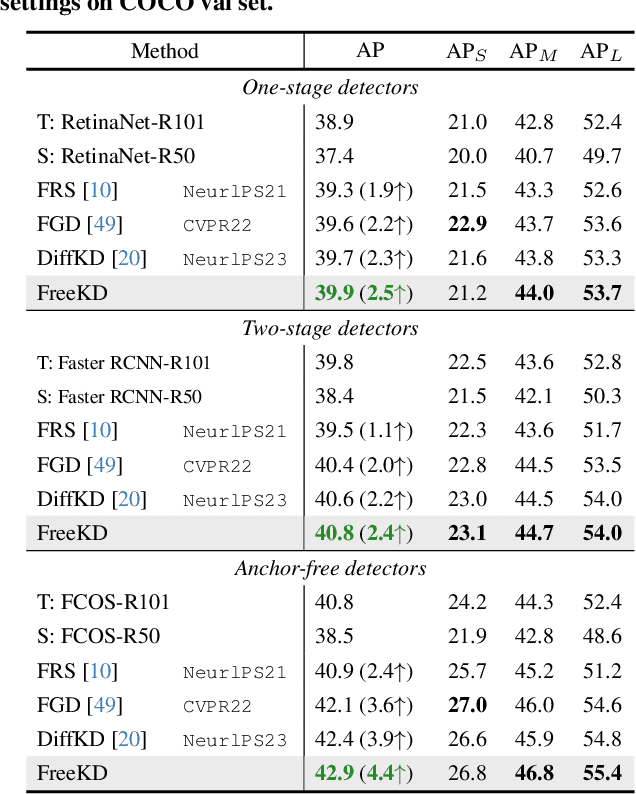
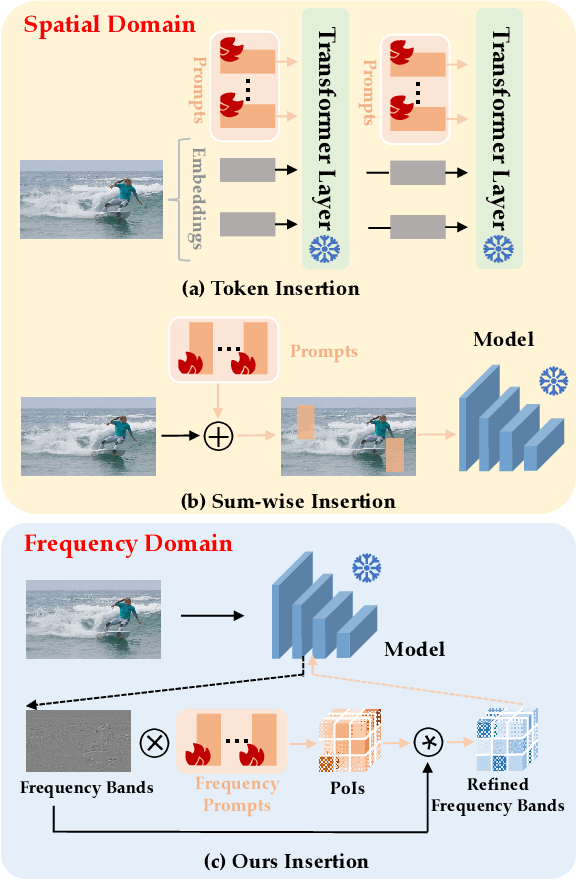
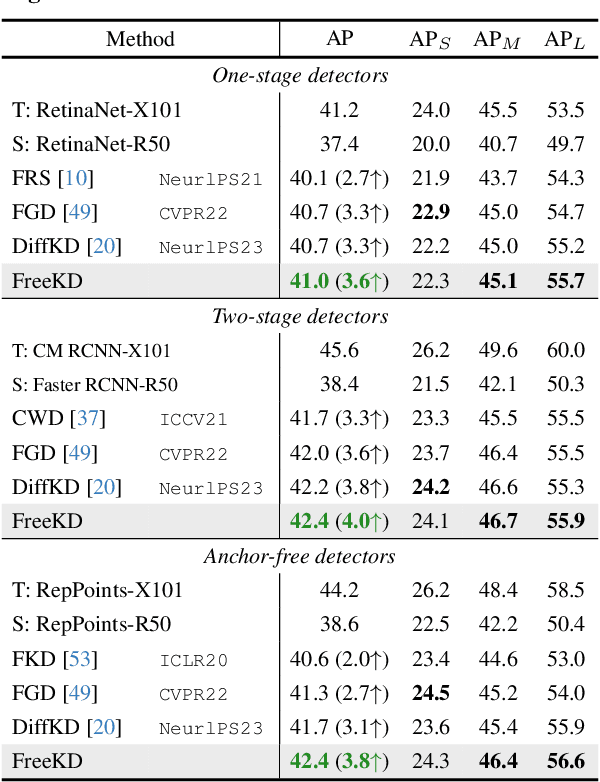
Knowledge distillation (KD) has been applied to various tasks successfully, and mainstream methods typically boost the student model via spatial imitation losses. However, the consecutive downsamplings induced in the spatial domain of teacher model is a type of corruption, hindering the student from analyzing what specific information needs to be imitated, which results in accuracy degradation. To better understand the underlying pattern of corrupted feature maps, we shift our attention to the frequency domain. During frequency distillation, we encounter a new challenge: the low-frequency bands convey general but minimal context, while the high are more informative but also introduce noise. Not each pixel within the frequency bands contributes equally to the performance. To address the above problem: (1) We propose the Frequency Prompt plugged into the teacher model, absorbing the semantic frequency context during finetuning. (2) During the distillation period, a pixel-wise frequency mask is generated via Frequency Prompt, to localize those pixel of interests (PoIs) in various frequency bands. Additionally, we employ a position-aware relational frequency loss for dense prediction tasks, delivering a high-order spatial enhancement to the student model. We dub our Frequency Knowledge Distillation method as FreeKD, which determines the optimal localization and extent for the frequency distillation. Extensive experiments demonstrate that FreeKD not only outperforms spatial-based distillation methods consistently on dense prediction tasks (e.g., FreeKD brings 3.8 AP gains for RepPoints-R50 on COCO2017 and 4.55 mIoU gains for PSPNet-R18 on Cityscapes), but also conveys more robustness to the student. Notably, we also validate the generalization of our approach on large-scale vision models (e.g., DINO and SAM).
On The Relative Error of Random Fourier Features for Preserving Kernel Distance
Oct 01, 2022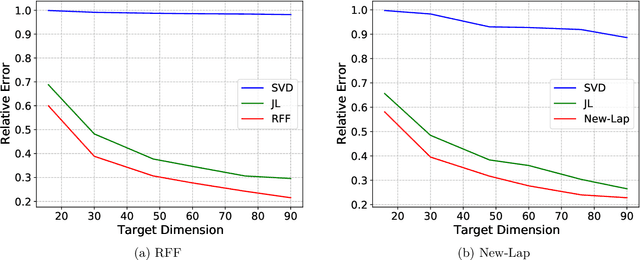
The method of random Fourier features (RFF), proposed in a seminal paper by Rahimi and Recht (NIPS'07), is a powerful technique to find approximate low-dimensional representations of points in (high-dimensional) kernel space, for shift-invariant kernels. While RFF has been analyzed under various notions of error guarantee, the ability to preserve the kernel distance with \emph{relative} error is less understood. We show that for a significant range of kernels, including the well-known Laplacian kernels, RFF cannot approximate the kernel distance with small relative error using low dimensions. We complement this by showing as long as the shift-invariant kernel is analytic, RFF with $\mathrm{poly}(\epsilon^{-1} \log n)$ dimensions achieves $\epsilon$-relative error for pairwise kernel distance of $n$ points, and the dimension bound is improved to $\mathrm{poly}(\epsilon^{-1}\log k)$ for the specific application of kernel $k$-means. Finally, going beyond RFF, we make the first step towards data-oblivious dimension-reduction for general shift-invariant kernels, and we obtain a similar $\mathrm{poly}(\epsilon^{-1} \log n)$ dimension bound for Laplacian kernels. We also validate the dimension-error tradeoff of our methods on simulated datasets, and they demonstrate superior performance compared with other popular methods including random-projection and Nystr\"{o}m methods.