 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeKD: Knowledge Distillation via Semantic Frequency Prompt
Paper and Code
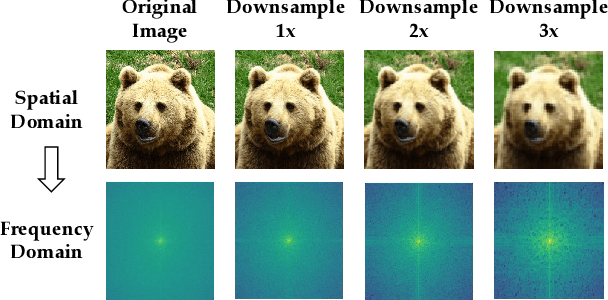
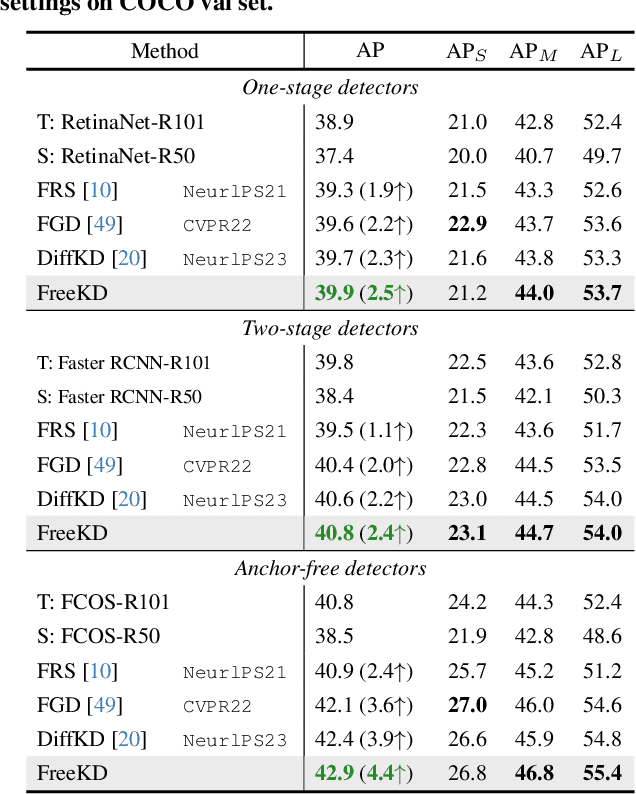
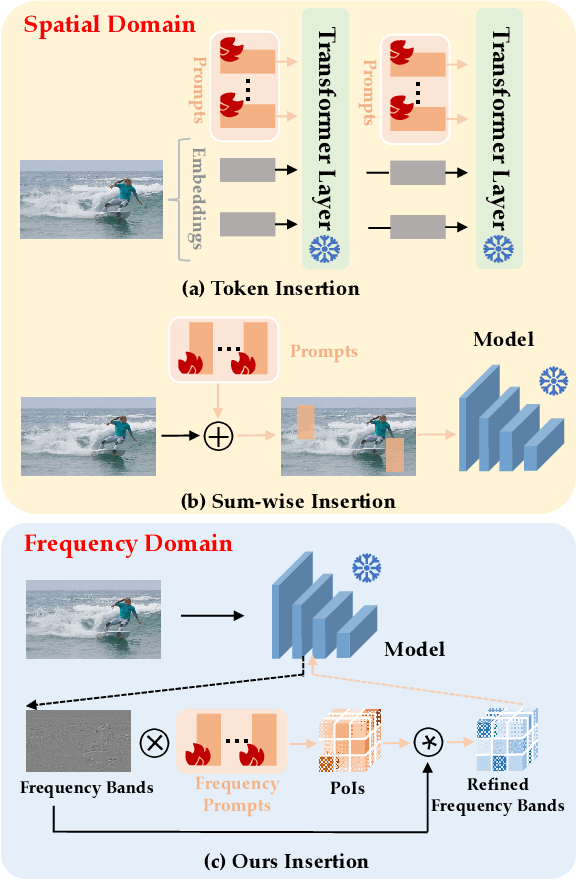
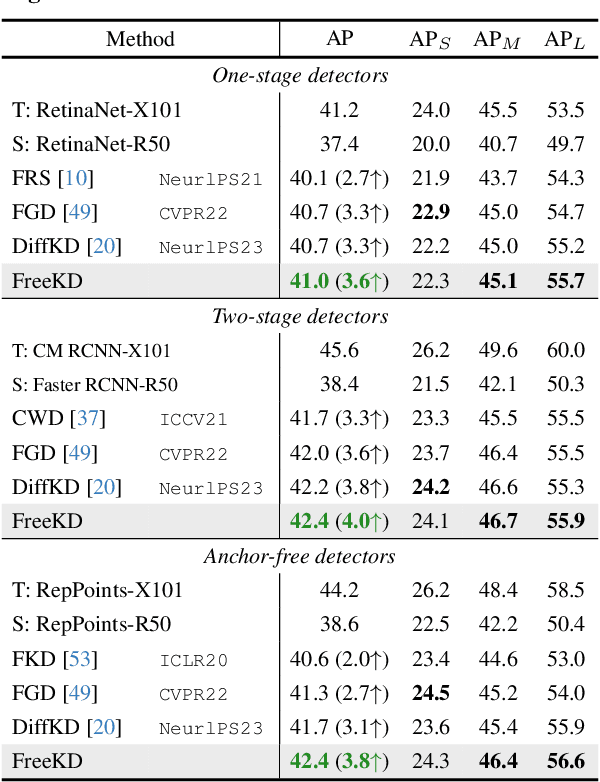
Knowledge distillation (KD) has been applied to various tasks successfully, and mainstream methods typically boost the student model via spatial imitation losses. However, the consecutive downsamplings induced in the spatial domain of teacher model is a type of corruption, hindering the student from analyzing what specific information needs to be imitated, which results in accuracy degradation. To better understand the underlying pattern of corrupted feature maps, we shift our attention to the frequency domain. During frequency distillation, we encounter a new challenge: the low-frequency bands convey general but minimal context, while the high are more informative but also introduce noise. Not each pixel within the frequency bands contributes equally to the performance. To address the above problem: (1) We propose the Frequency Prompt plugged into the teacher model, absorbing the semantic frequency context during finetuning. (2) During the distillation period, a pixel-wise frequency mask is generated via Frequency Prompt, to localize those pixel of interests (PoIs) in various frequency bands. Additionally, we employ a position-aware relational frequency loss for dense prediction tasks, delivering a high-order spatial enhancement to the student model. We dub our Frequency Knowledge Distillation method as FreeKD, which determines the optimal localization and extent for the frequency distillation. Extensive experiments demonstrate that FreeKD not only outperforms spatial-based distillation methods consistently on dense prediction tasks (e.g., FreeKD brings 3.8 AP gains for RepPoints-R50 on COCO2017 and 4.55 mIoU gains for PSPNet-R18 on Cityscapes), but also conveys more robustness to the student. Notably, we also validate the generalization of our approach on large-scale vision models (e.g., DINO and SAM).