 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Jun 10, 2025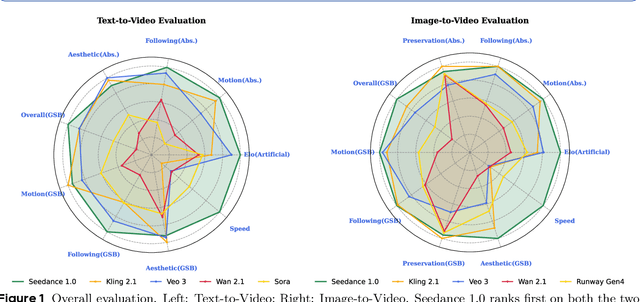
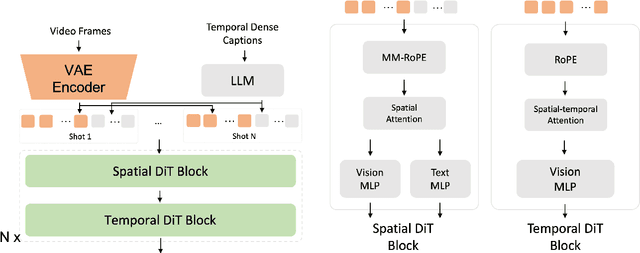
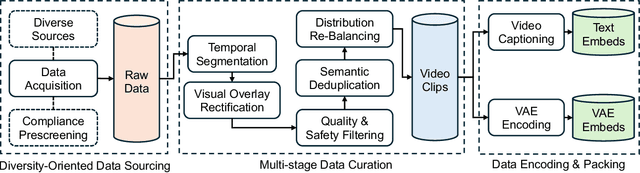
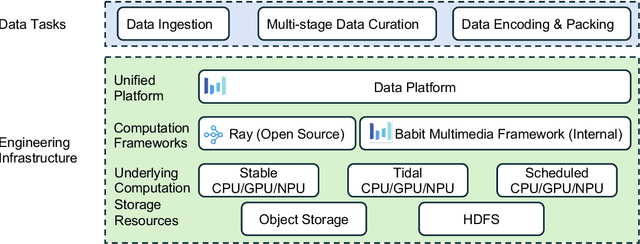
Notable breakthroughs in diffusion modeling have propelled rapid improvements in video generation, yet current foundational model still face critical challenges in simultaneously balancing prompt following, motion plausibility, and visual quality. In this report, we introduce Seedance 1.0, a high-performance and inference-efficient video foundation generation model that integrates several core technical improvements: (i) multi-source data curation augmented with precision and meaningful video captioning, enabling comprehensive learning across diverse scenarios; (ii) an efficient architecture design with proposed training paradigm, which allows for natively supporting multi-shot generation and jointly learning of both text-to-video and image-to-video tasks. (iii) carefully-optimized post-training approaches leveraging fine-grained supervised fine-tuning, and video-specific RLHF with multi-dimensional reward mechanisms for comprehensive performance improvements; (iv) excellent model acceleration achieving ~10x inference speedup through multi-stage distillation strategies and system-level optimizations. Seedance 1.0 can generate a 5-second video at 1080p resolution only with 41.4 seconds (NVIDIA-L20). Compared to state-of-the-art video generation models, Seedance 1.0 stands out with high-quality and fast video generation having superior spatiotemporal fluidity with structural stability, precise instruction adherence in complex multi-subject contexts, native multi-shot narrative coherence with consistent subject representation.
Seaweed-7B: Cost-Effective Training of Video Generation Foundation Model
Apr 11, 2025
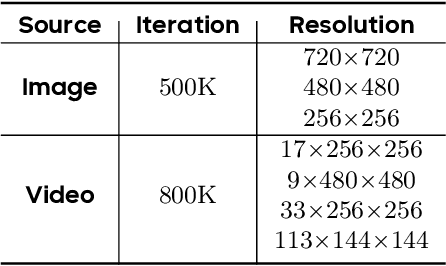
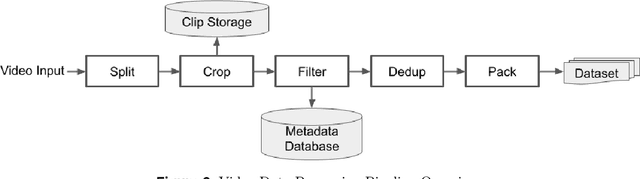

This technical report presents a cost-efficient strategy for training a video generation foundation model. We present a mid-sized research model with approximately 7 billion parameters (7B) called Seaweed-7B trained from scratch using 665,000 H100 GPU hours. Despite being trained with moderate computational resources, Seaweed-7B demonstrates highly competitive performance compared to contemporary video generation models of much larger size. Design choices are especially crucial in a resource-constrained setting. This technical report highlights the key design decisions that enhance the performance of the medium-sized diffusion model. Empirically, we make two observations: (1) Seaweed-7B achieves performance comparable to, or even surpasses, larger models trained on substantially greater GPU resources, and (2) our model, which exhibits strong generalization ability, can be effectively adapted across a wide range of downstream applications either by lightweight fine-tuning or continue training. See the project page at https://seaweed.video/
VecAug: Unveiling Camouflaged Frauds with Cohort Augmentation for Enhanced Detection
Aug 01, 2024



Fraud detection presents a challenging task characterized by ever-evolving fraud patterns and scarce labeled data. Existing methods predominantly rely on graph-based or sequence-based approaches. While graph-based approaches connect users through shared entities to capture structural information, they remain vulnerable to fraudsters who can disrupt or manipulate these connections. In contrast, sequence-based approaches analyze users' behavioral patterns, offering robustness against tampering but overlooking the interactions between similar users. Inspired by cohort analysis in retention and healthcare, this paper introduces VecAug, a novel cohort-augmented learning framework that addresses these challenges by enhancing the representation learning of target users with personalized cohort information. To this end, we first propose a vector burn-in technique for automatic cohort identification, which retrieves a task-specific cohort for each target user. Then, to fully exploit the cohort information, we introduce an attentive cohort aggregation technique for augmenting target user representations. To improve the robustness of such cohort augmentation, we also propose a novel label-aware cohort neighbor separation mechanism to distance negative cohort neighbors and calibrate the aggregated cohort information. By integrating this cohort information with target user representations, VecAug enhances the modeling capacity and generalization capabilities of the model to be augmented. Our framework is flexible and can be seamlessly integrated with existing fraud detection models. We deploy our framework on e-commerce platforms and evaluate it on three fraud detection datasets, and results show that VecAug improves the detection performance of base models by up to 2.48\% in AUC and 22.5\% in R@P$_{0.9}$, outperforming state-of-the-art methods significantly.
Unveiling the Tapestry of Consistency in Large Vision-Language Models
May 23, 2024Large vision-language models (LVLMs) have recently achieved rapid progress, exhibiting great perception and reasoning abilities concerning visual information. However, when faced with prompts in different sizes of solution spaces, LVLMs fail to always give consistent answers regarding the same knowledge point. This inconsistency of answers between different solution spaces is prevalent in LVLMs and erodes trust. To this end, we provide a multi-modal benchmark ConBench, to intuitively analyze how LVLMs perform when the solution space of a prompt revolves around a knowledge point. Based on the ConBench tool, we are the first to reveal the tapestry and get the following findings: (1) In the discriminate realm, the larger the solution space of the prompt, the lower the accuracy of the answers. (2) Establish the relationship between the discriminative and generative realms: the accuracy of the discriminative question type exhibits a strong positive correlation with its Consistency with the caption. (3) Compared to open-source models, closed-source models exhibit a pronounced bias advantage in terms of Consistency. Eventually, we ameliorate the consistency of LVLMs by trigger-based diagnostic refinement, indirectly improving the performance of their caption. We hope this paper will accelerate the research community in better evaluating their models and encourage future advancements in the consistency domain.
Transductive Learning for Unsupervised Text Style Transfer
Sep 16, 2021
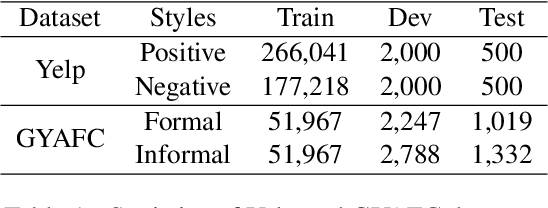


Unsupervised style transfer models are mainly based on an inductive learning approach, which represents the style as embeddings, decoder parameters, or discriminator parameters and directly applies these general rules to the test cases. However, the lacking of parallel corpus hinders the ability of these inductive learning methods on this task. As a result, it is likely to cause severe inconsistent style expressions, like `the salad is rude`. To tackle this problem, we propose a novel transductive learning approach in this paper, based on a retrieval-based context-aware style representation. Specifically, an attentional encoder-decoder with a retriever framework is utilized. It involves top-K relevant sentences in the target style in the transfer process. In this way, we can learn a context-aware style embedding to alleviate the above inconsistency problem. In this paper, both sparse (BM25) and dense retrieval functions (MIPS) are used, and two objective functions are designed to facilitate joint learning. Experimental results show that our method outperforms several strong baselines. The proposed transductive learning approach is general and effective to the task of unsupervised style transfer, and we will apply it to the other two typical methods in the future.
Predictions of short-term driving intention using recurrent neural network on sequential data
Mar 28, 2018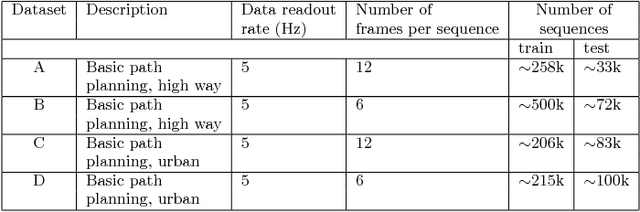



Predictions of driver's intentions and their behaviors using the road is of great importance for planning and decision making processes of autonomous driving vehicles. In particular, relatively short-term driving intentions are the fundamental units that constitute more sophisticated driving goals, behaviors, such as overtaking the slow vehicle in front, exit or merge onto a high way, etc. While it is not uncommon that most of the time human driver can rationalize, in advance, various on-road behaviors, intentions, as well as the associated risks, aggressiveness, reciprocity characteristics, etc., such reasoning skills can be challenging and difficult for an autonomous driving system to learn. In this article, we demonstrate a disciplined methodology that can be used to build and train a predictive drive system, therefore to learn the on-road characteristics aforementioned.
Cascade Ranking for Operational E-commerce Search
Jun 07, 2017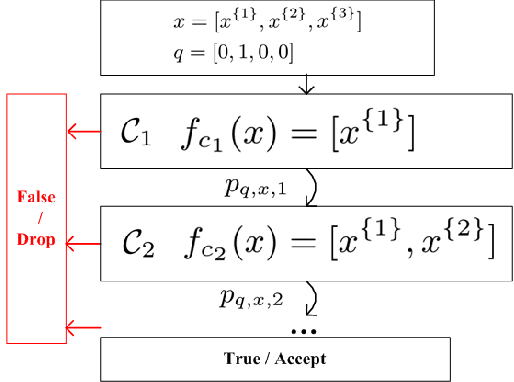
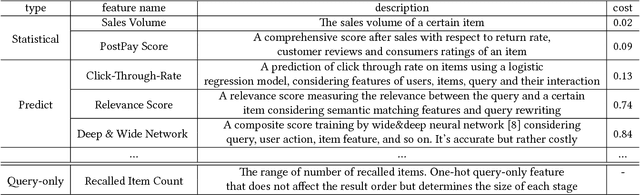


In the 'Big Data' era, many real-world applications like search involve the ranking problem for a large number of items. It is important to obtain effective ranking results and at the same time obtain the results efficiently in a timely manner for providing good user experience and saving computational costs. Valuable prior research has been conducted for learning to efficiently rank like the cascade ranking (learning) model, which uses a sequence of ranking functions to progressively filter some items and rank the remaining items. However, most existing research of learning to efficiently rank in search is studied in a relatively small computing environments with simulated user queries. This paper presents novel research and thorough study of designing and deploying a Cascade model in a Large-scale Operational E-commerce Search application (CLOES), which deals with hundreds of millions of user queries per day with hundreds of servers. The challenge of the real-world application provides new insights for research: 1). Real-world search applications often involve multiple factors of preferences or constraints with respect to user experience and computational costs such as search accuracy, search latency, size of search results and total CPU cost, while most existing search solutions only address one or two factors; 2). Effectiveness of e-commerce search involves multiple types of user behaviors such as click and purchase, while most existing cascade ranking in search only models the click behavior. Based on these observations, a novel cascade ranking model is designed and deployed in an operational e-commerce search application. An extensive set of experiments demonstrate the advantage of the proposed work to address multiple factors of effectiveness, efficiency and user experience in the real-world application.
Modeling of the Latent Embedding of Music using Deep Neural Network
May 12, 2017
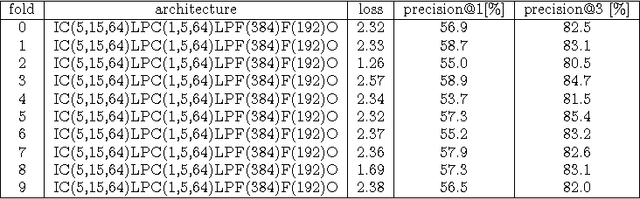


While both the data volume and heterogeneity of the digital music content is huge, it has become increasingly important and convenient to build a recommendation or search system to facilitate surfacing these content to the user or consumer community. Most of the recommendation models fall into two primary species, collaborative filtering based and content based approaches. Variants of instantiations of collaborative filtering approach suffer from the common issues of so called "cold start" and "long tail" problems where there is not much user interaction data to reveal user opinions or affinities on the content and also the distortion towards the popular content. Content-based approaches are sometimes limited by the richness of the available content data resulting in a heavily biased and coarse recommendation result. In recent years, the deep neural network has enjoyed a great success in large-scale image and video recognitions. In this paper, we propose and experiment using deep convolutional neural network to imitate how human brain processes hierarchical structures in the auditory signals, such as music, speech, etc., at various timescales. This approach can be used to discover the latent factor models of the music based upon acoustic hyper-images that are extracted from the raw audio waves of music. These latent embeddings can be used either as features to feed to subsequent models, such as collaborative filtering, or to build similarity metrics between songs, or to classify music based on the labels for training such as genre, mood, sentiment, etc.
Robust Local Search for Solving RCPSP/max with Durational Uncertainty
Jan 18, 2014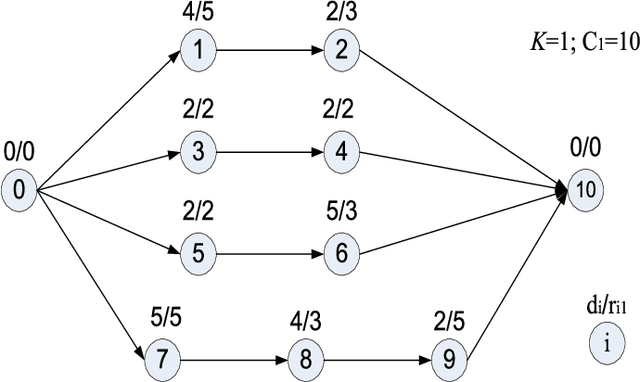

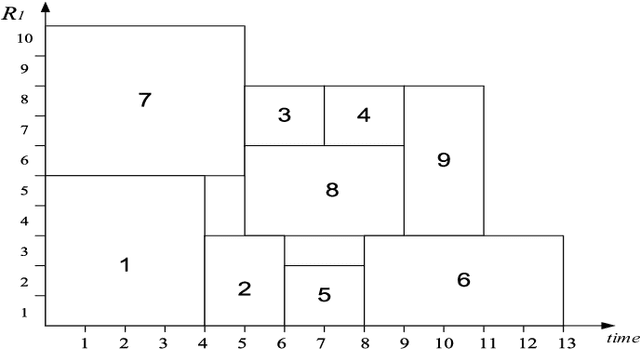

Scheduling problems in manufacturing, logistics and project management have frequently been modeled using the framework of Resource Constrained Project Scheduling Problems with minimum and maximum time lags (RCPSP/max). Due to the importance of these problems, providing scalable solution schedules for RCPSP/max problems is a topic of extensive research. However, all existing methods for solving RCPSP/max assume that durations of activities are known with certainty, an assumption that does not hold in real world scheduling problems where unexpected external events such as manpower availability, weather changes, etc. lead to delays or advances in completion of activities. Thus, in this paper, our focus is on providing a scalable method for solving RCPSP/max problems with durational uncertainty. To that end, we introduce the robust local search method consisting of three key ideas: (a) Introducing and studying the properties of two decision rule approximations used to compute start times of activities with respect to dynamic realizations of the durational uncertainty; (b) Deriving the expression for robust makespan of an execution strategy based on decision rule approximations; and (c) A robust local search mechanism to efficiently compute activity execution strategies that are robust against durational uncertainty. Furthermore, we also provide enhancements to local search that exploit temporal dependencies between activities. Our experimental results illustrate that robust local search is able to provide robust execution strategies efficiently.