 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Nature of Depth-1 Equivariant Quantum Circuit
Nov 19, 2025The Equivariant Quantum Circuit (EQC) for the Travelling Salesman Problem (TSP) has been shown to achieve near-optimal performance in solving small TSP problems (up to 20 nodes) using only two parameters at depth 1. However, extending EQCs to larger TSP problem sizes remains challenging due to the exponential time and memory for quantum circuit simulation, as well as increasing noise and decoherence when running on actual quantum hardware. In this work, we propose the Size-Invariant Grid Search (SIGS), an efficient training optimization for Quantum Reinforcement Learning (QRL), and use it to simulate the outputs of a trained Depth-1 EQC up to 350-node TSP instances - well beyond previously tractable limits. At TSP with 100 nodes, we reduce total simulation times by 96.4%, when comparing to RL simulations with the analytical expression (151 minutes using RL to under 6 minutes using SIGS on TSP-100), while achieving a mean optimality gap within 0.005 of the RL trained model on the test set. SIGS provides a practical benchmarking tool for the QRL community, allowing us to efficiently analyze the performance of QRL algorithms on larger problem sizes. We provide a theoretical explanation for SIGS called the Size-Invariant Properties that goes beyond the concept of equivariance discussed in prior literature.
Automated Conversion of Static to Dynamic Scheduler via Natural Language
May 08, 2024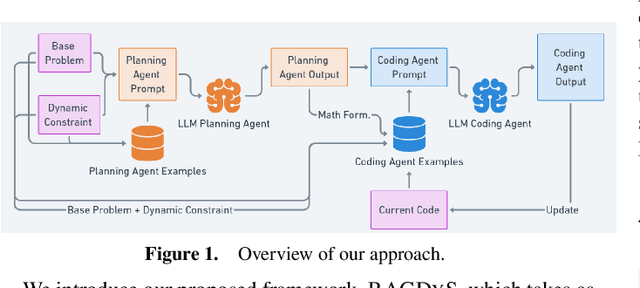

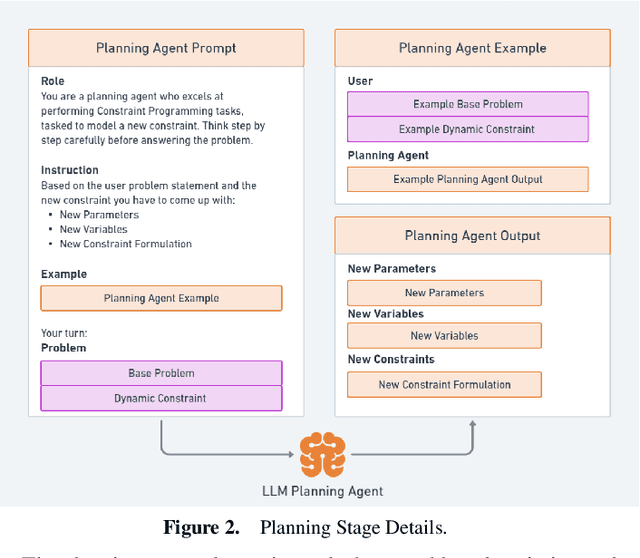
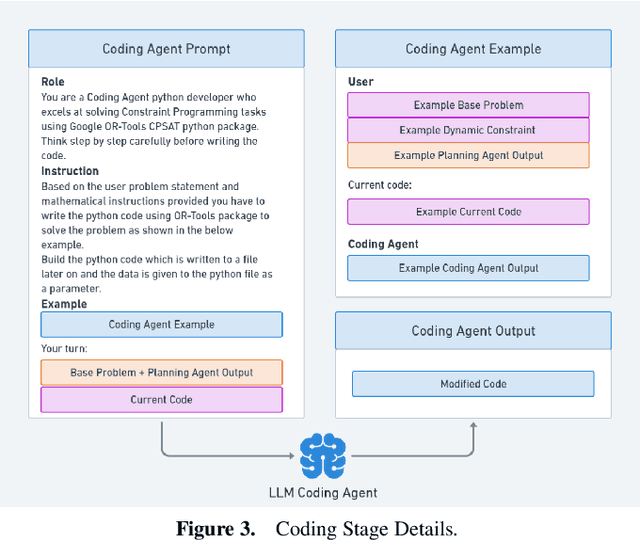
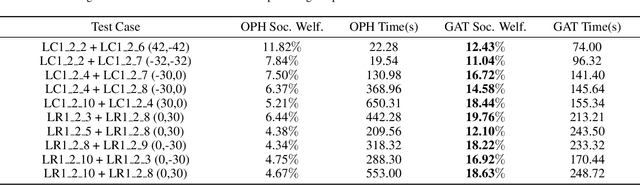
In this paper, we explore the potential application of Large Language Models (LLMs) that will automatically model constraints and generate code for dynamic scheduling problems given an existing static model. Static scheduling problems are modelled and coded by optimization experts. These models may be easily obsoleted as the underlying constraints may need to be fine-tuned in order to reflect changes in the scheduling rules. Furthermore, it may be necessary to turn a static model into a dynamic one in order to cope with disturbances in the environment. In this paper, we propose a Retrieval-Augmented Generation (RAG) based LLM model to automate the process of implementing constraints for Dynamic Scheduling (RAGDyS), without seeking help from an optimization modeling expert. Our framework aims to minimize technical complexities related to mathematical modelling and computational workload for end-users, thereby allowing end-users to quickly obtain a new schedule close to the original schedule with changes reflected by natural language constraint descriptions.
Individually Rational Collaborative Vehicle Routing through Give-And-Take Exchanges
Aug 31, 2023


In this paper, we are concerned with the automated exchange of orders between logistics companies in a marketplace platform to optimize total revenues. We introduce a novel multi-agent approach to this problem, focusing on the Collaborative Vehicle Routing Problem (CVRP) through the lens of individual rationality. Our proposed algorithm applies the principles of Vehicle Routing Problem (VRP) to pairs of vehicles from different logistics companies, optimizing the overall routes while considering standard VRP constraints plus individual rationality constraints. By facilitating cooperation among competing logistics agents through a Give-and-Take approach, we show that it is possible to reduce travel distance and increase operational efficiency system-wide. More importantly, our approach ensures individual rationality and faster convergence, which are important properties of ensuring the long-term sustainability of the marketplace platform. We demonstrate the efficacy of our approach through extensive experiments using real-world test data from major logistics companies. The results reveal our algorithm's ability to rapidly identify numerous optimal solutions, underscoring its practical applicability and potential to transform the logistics industry.
The BeMi Stardust: a Structured Ensemble of Binarized Neural Networks
Dec 07, 2022
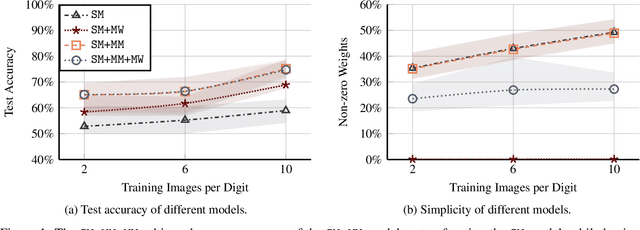
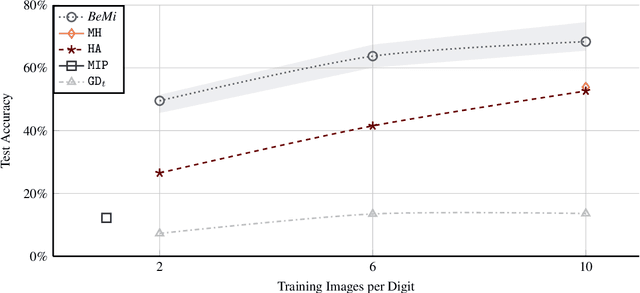
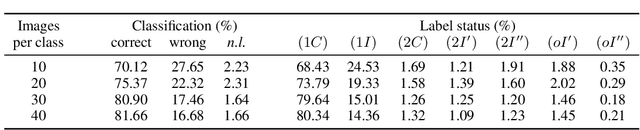
Binarized Neural Networks (BNNs) are receiving increasing attention due to their lightweight architecture and ability to run on low-power devices. The state-of-the-art for training classification BNNs restricted to few-shot learning is based on a Mixed Integer Programming (MIP) approach. This paper proposes the BeMi ensemble, a structured architecture of BNNs based on training a single BNN for each possible pair of classes and applying a majority voting scheme to predict the final output. The training of a single BNN discriminating between two classes is achieved by a MIP model that optimizes a lexicographic multi-objective function according to robustness and simplicity principles. This approach results in training networks whose output is not affected by small perturbations on the input and whose number of active weights is as small as possible, while good accuracy is preserved. We computationally validate our model using the MNIST and Fashion-MNIST datasets using up to 40 training images per class. Our structured ensemble outperforms both BNNs trained by stochastic gradient descent and state-of-the-art MIP-based approaches. While the previous approaches achieve an average accuracy of 51.1% on the MNIST dataset, the BeMi ensemble achieves an average accuracy of 61.7% when trained with 10 images per class and 76.4% when trained with 40 images per class.
Operator Selection in Adaptive Large Neighborhood Search using Deep Reinforcement Learning
Nov 01, 2022
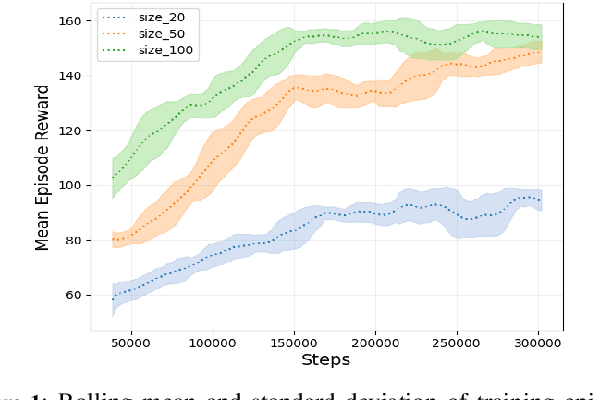


Large Neighborhood Search (LNS) is a popular heuristic for solving combinatorial optimization problems. LNS iteratively explores the neighborhoods in solution spaces using destroy and repair operators. Determining the best operators for LNS to solve a problem at hand is a labor-intensive process. Hence, Adaptive Large Neighborhood Search (ALNS) has been proposed to adaptively select operators during the search process based on operator performances of the previous search iterations. Such an operator selection procedure is a heuristic, based on domain knowledge, which is ineffective with complex, large solution spaces. In this paper, we address the problem of selecting operators for each search iteration of ALNS as a sequential decision problem and propose a Deep Reinforcement Learning based method called Deep Reinforced Adaptive Large Neighborhood Search. As such, the proposed method aims to learn based on the state of the search which operation to select to obtain a high long-term reward, i.e., a good solution to the underlying optimization problem. The proposed method is evaluated on a time-dependent orienteering problem with stochastic weights and time windows. Results show that our approach effectively learns a strategy that adaptively selects operators for large neighborhood search, obtaining competitive results compared to a state-of-the-art machine learning approach while trained with much fewer observations on small-sized problem instances.
QROSS: QUBO Relaxation Parameter Optimisation via Learning Solver Surrogates
Mar 19, 2021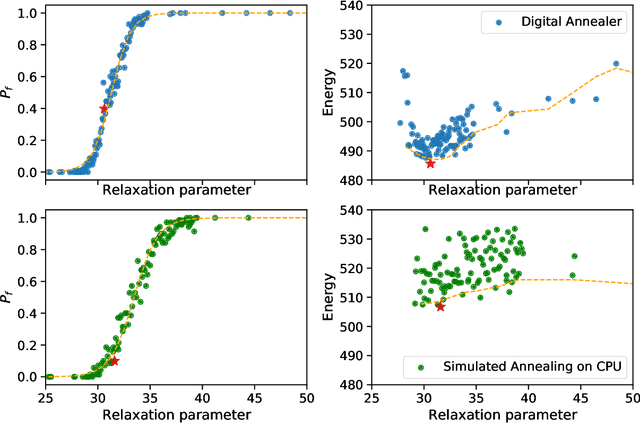
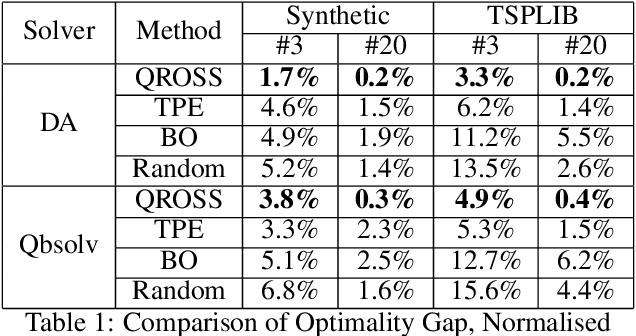
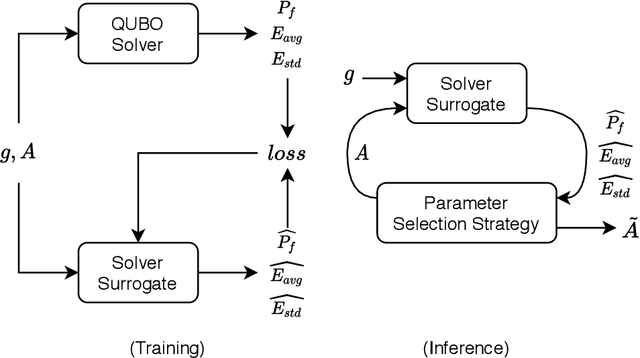
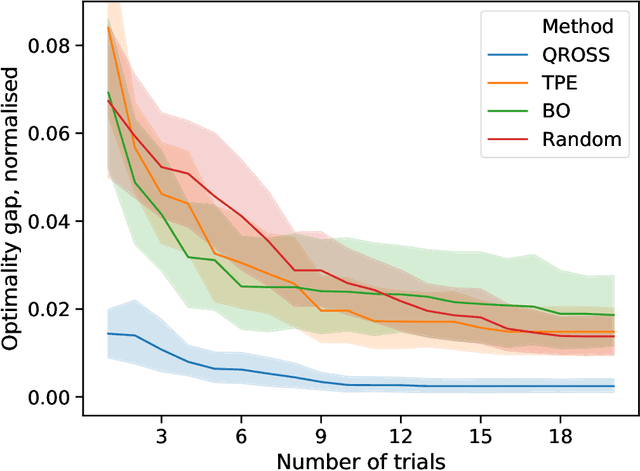
An increasingly popular method for solving a constrained combinatorial optimisation problem is to first convert it into a quadratic unconstrained binary optimisation (QUBO) problem, and solve it using a standard QUBO solver. However, this relaxation introduces hyper-parameters that balance the objective and penalty terms for the constraints, and their chosen values significantly impact performance. Hence, tuning these parameters is an important problem. Existing generic hyper-parameter tuning methods require multiple expensive calls to a QUBO solver, making them impractical for performance critical applications when repeated solutions of similar combinatorial optimisation problems are required. In this paper, we propose the QROSS method, in which we build surrogate models of QUBO solvers via learning from solver data on a collection of instances of a problem. In this way, we are able capture the common structure of the instances and their interactions with the solver, and produce good choices of penalty parameters with fewer number of calls to the QUBO solver. We take the Traveling Salesman Problem (TSP) as a case study, where we demonstrate that our method can find better solutions with fewer calls to QUBO solver compared with conventional hyper-parameter tuning techniques. Moreover, with simple adaptation methods, QROSS is shown to generalise well to out-of-distribution datasets and different types of QUBO solvers.
Entropy Controlled Non-Stationarity for Improving Performance of Independent Learners in Anonymous MARL Settings
May 27, 2018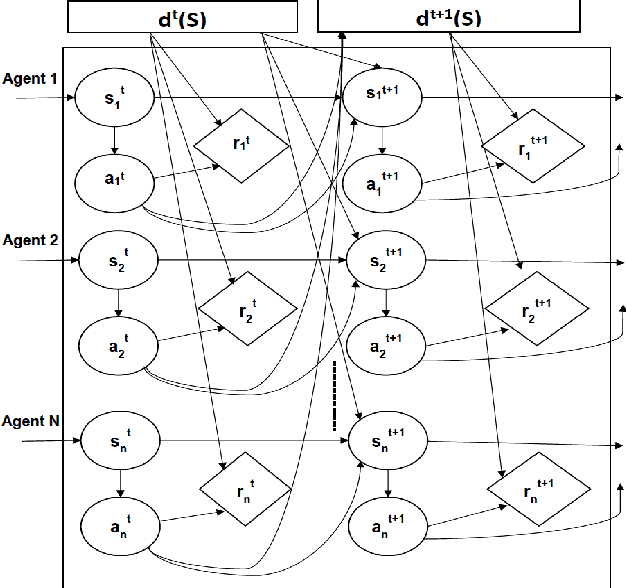
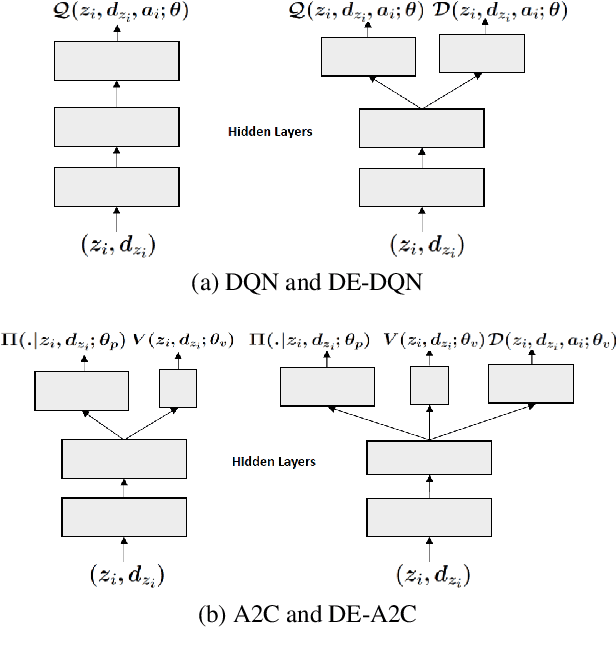
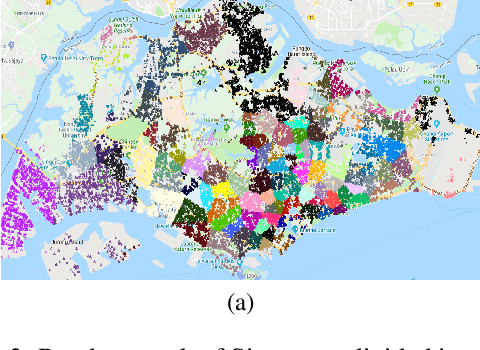
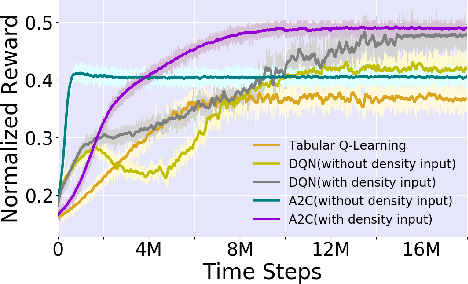
With the advent of sequential matching (of supply and demand) systems (uber, Lyft, Grab for taxis; ubereats, deliveroo, etc for food; amazon prime, lazada etc. for groceries) across many online and offline services, individuals (taxi drivers, delivery boys, delivery van drivers, etc.) earn more by being at the "right" place at the "right" time. We focus on learning techniques for providing guidance (on right locations to be at right times) to individuals in the presence of other "learning" individuals. Interactions between indivduals are anonymous, i.e, the outcome of an interaction (competing for demand) is independent of the identity of the agents and therefore we refer to these as Anonymous MARL settings. Existing research of relevance is on independent learning using Reinforcement Learning (RL) or on Multi-Agent Reinforcement Learning (MARL). The number of individuals in aggregation systems is extremely large and individuals have their own selfish interest (of maximising revenue). Therefore, traditional MARL approaches are either not scalable or assumptions of common objective or action coordination are not viable. In this paper, we focus on improving performance of independent reinforcement learners, specifically the popular Deep Q-Networks (DQN) and Advantage Actor Critic (A2C) approaches by exploiting anonymity. Specifically, we control non-stationarity introduced by other agents using entropy of agent density distribution. We demonstrate a significant improvement in revenue for individuals and for all agents together with our learners on a generic experimental set up for aggregation systems and a real world taxi dataset.
Policy Gradient With Value Function Approximation For Collective Multiagent Planning
Apr 09, 2018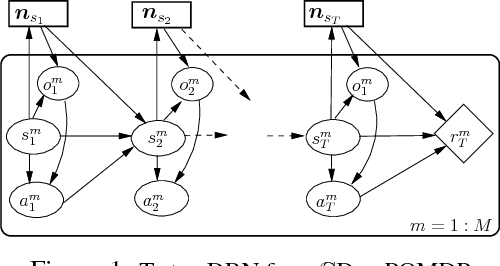

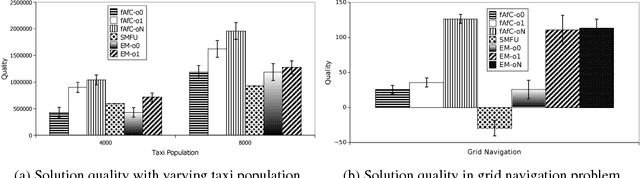
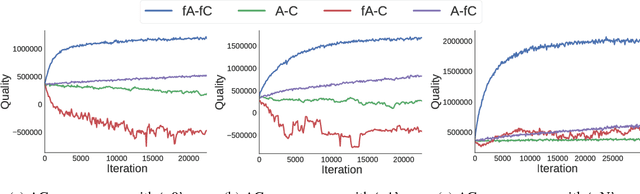
Decentralized (PO)MDPs provide an expressive framework for sequential decision making in a multiagent system. Given their computational complexity, recent research has focused on tractable yet practical subclasses of Dec-POMDPs. We address such a subclass called CDEC-POMDP where the collective behavior of a population of agents affects the joint-reward and environment dynamics. Our main contribution is an actor-critic (AC) reinforcement learning method for optimizing CDEC-POMDP policies. Vanilla AC has slow convergence for larger problems. To address this, we show how a particular decomposition of the approximate action-value function over agents leads to effective updates, and also derive a new way to train the critic based on local reward signals. Comparisons on a synthetic benchmark and a real-world taxi fleet optimization problem show that our new AC approach provides better quality solutions than previous best approaches.
Local Gaussian Processes for Efficient Fine-Grained Traffic Speed Prediction
Aug 27, 2017
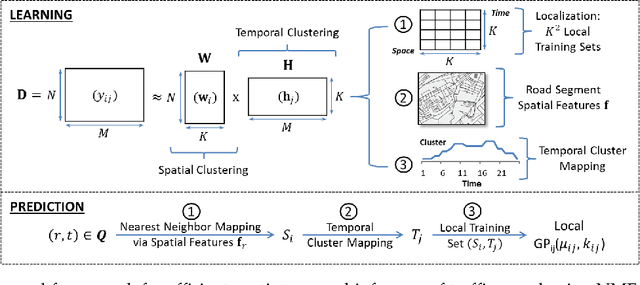
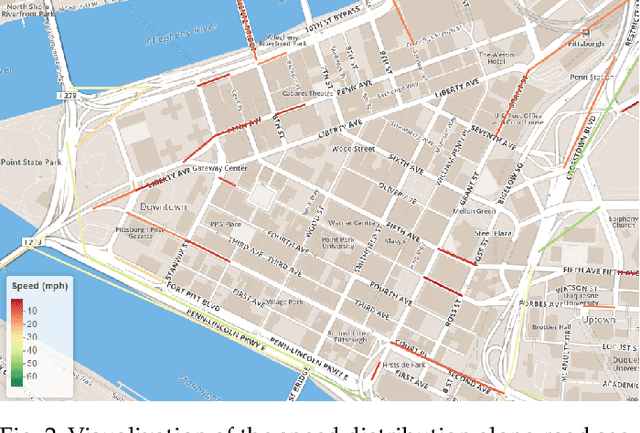

Traffic speed is a key indicator for the efficiency of an urban transportation system. Accurate modeling of the spatiotemporally varying traffic speed thus plays a crucial role in urban planning and development. This paper addresses the problem of efficient fine-grained traffic speed prediction using big traffic data obtained from static sensors. Gaussian processes (GPs) have been previously used to model various traffic phenomena, including flow and speed. However, GPs do not scale with big traffic data due to their cubic time complexity. In this work, we address their efficiency issues by proposing local GPs to learn from and make predictions for correlated subsets of data. The main idea is to quickly group speed variables in both spatial and temporal dimensions into a finite number of clusters, so that future and unobserved traffic speed queries can be heuristically mapped to one of such clusters. A local GP corresponding to that cluster can then be trained on the fly to make predictions in real-time. We call this method localization. We use non-negative matrix factorization for localization and propose simple heuristics for cluster mapping. We additionally leverage on the expressiveness of GP kernel functions to model road network topology and incorporate side information. Extensive experiments using real-world traffic data collected in the two U.S. cities of Pittsburgh and Washington, D.C., show that our proposed local GPs significantly improve both runtime performances and prediction accuracies compared to the baseline global and local GPs.
Robust Local Search for Solving RCPSP/max with Durational Uncertainty
Jan 18, 2014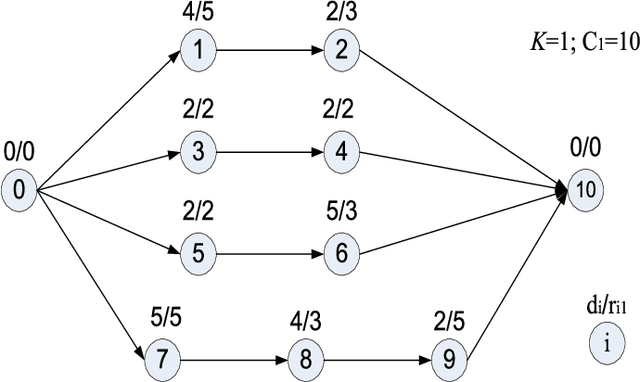

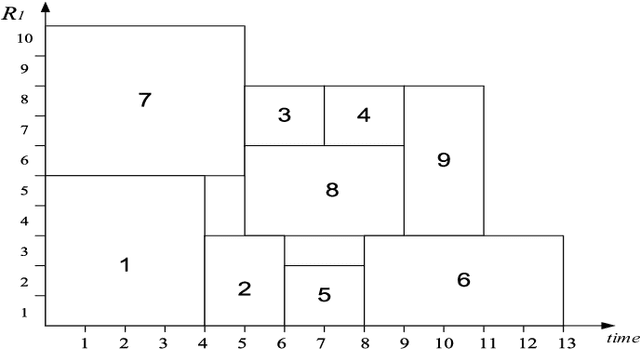

Scheduling problems in manufacturing, logistics and project management have frequently been modeled using the framework of Resource Constrained Project Scheduling Problems with minimum and maximum time lags (RCPSP/max). Due to the importance of these problems, providing scalable solution schedules for RCPSP/max problems is a topic of extensive research. However, all existing methods for solving RCPSP/max assume that durations of activities are known with certainty, an assumption that does not hold in real world scheduling problems where unexpected external events such as manpower availability, weather changes, etc. lead to delays or advances in completion of activities. Thus, in this paper, our focus is on providing a scalable method for solving RCPSP/max problems with durational uncertainty. To that end, we introduce the robust local search method consisting of three key ideas: (a) Introducing and studying the properties of two decision rule approximations used to compute start times of activities with respect to dynamic realizations of the durational uncertainty; (b) Deriving the expression for robust makespan of an execution strategy based on decision rule approximations; and (c) A robust local search mechanism to efficiently compute activity execution strategies that are robust against durational uncertainty. Furthermore, we also provide enhancements to local search that exploit temporal dependencies between activities. Our experimental results illustrate that robust local search is able to provide robust execution strategies efficiently.