 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Gradient With Value Function Approximation For Collective Multiagent Planning
Paper and Code
Apr 09, 2018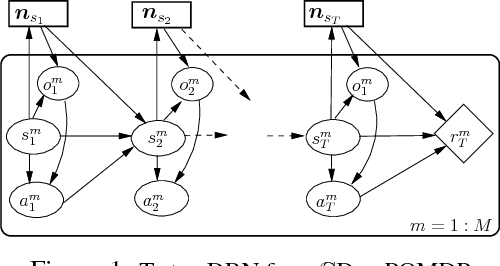

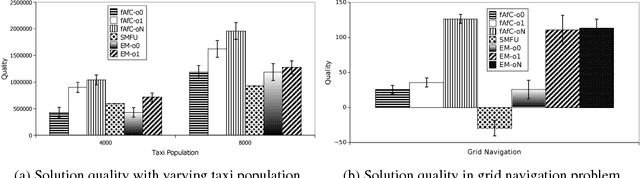
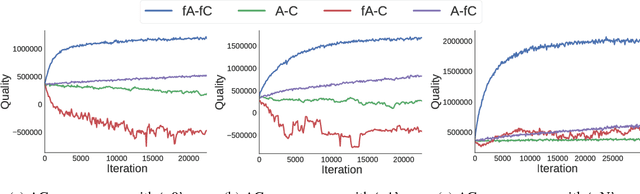
Decentralized (PO)MDPs provide an expressive framework for sequential decision making in a multiagent system. Given their computational complexity, recent research has focused on tractable yet practical subclasses of Dec-POMDPs. We address such a subclass called CDEC-POMDP where the collective behavior of a population of agents affects the joint-reward and environment dynamics. Our main contribution is an actor-critic (AC) reinforcement learning method for optimizing CDEC-POMDP policies. Vanilla AC has slow convergence for larger problems. To address this, we show how a particular decomposition of the approximate action-value function over agents leads to effective updates, and also derive a new way to train the critic based on local reward signals. Comparisons on a synthetic benchmark and a real-world taxi fleet optimization problem show that our new AC approach provides better quality solutions than previous best approaches.