 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Medical Conversational AI through Online Reinforcement Learning with Information-Theoretic Rewards
Jan 25, 2026We present Information Gain Fine-Tuning (IGFT), a novel approach for training medical conversational AI to conduct effective patient interviews and generate comprehensive History of Present Illness (HPI) without requiring pre-collected human conversations. IGFT combines online Group Relative Policy Optimization (GRPO) with information-theoretic rewards, enabling models to learn from self-generated conversations with simulated patients. Unlike existing approaches that rely on expensive expert-annotated conversations or static datasets, our online RL framework allows models to discover effective questioning strategies through exploration. Our key innovation is an information gain reward function that tracks which clinical entities such as symptoms, temporal patterns, and medical history, are revealed during conversation. Each question's reward is computed based on its expected information gain combined with GPT-4o-mini quality assessments across dimensions including clinical relevance, patient engagement, and specificity. This hybrid approach ensures models learn to ask targeted, clinically appropriate questions that efficiently gather diagnostic information. We fine-tune two models using LoRA: Llama-3.1-8B-Instruct and DeepSeek-R1-Distill-Qwen-7B (a reasoning-optimized model). Training exclusively on Avey data containing concise HPIs, we evaluate generalization to MIMIC data with longer, more elaborate HPIs. DeepSeek-R1-Distill-Qwen-7B (IGFT) achieves F1 scores of 0.408 on Avey (10.9% improvement over base) and 0.289 on MIMIC (12.9% improvement), while Llama-3.1-8B-Instruct (IGFT) reaches 0.384 and 0.336 respectively. Both models outperform OpenAI's model on MIMIC and surpass medical domain-specific baselines like HuatuoGPT and UltraMedical, which were optimized for single-turn medical QA rather than multi-turn conversations.
Learning What to Do and What Not To Do: Offline Imitation from Expert and Undesirable Demonstrations
May 27, 2025Offline imitation learning typically learns from expert and unlabeled demonstrations, yet often overlooks the valuable signal in explicitly undesirable behaviors. In this work, we study offline imitation learning from contrasting behaviors, where the dataset contains both expert and undesirable demonstrations. We propose a novel formulation that optimizes a difference of KL divergences over the state-action visitation distributions of expert and undesirable (or bad) data. Although the resulting objective is a DC (Difference-of-Convex) program, we prove that it becomes convex when expert demonstrations outweigh undesirable demonstrations, enabling a practical and stable non-adversarial training objective. Our method avoids adversarial training and handles both positive and negative demonstrations in a unified framework. Extensive experiments on standard offline imitation learning benchmarks demonstrate that our approach consistently outperforms state-of-the-art baselines.
Confidence-Based Task Prediction in Continual Disease Classification Using Probability Distribution
Jun 03, 2024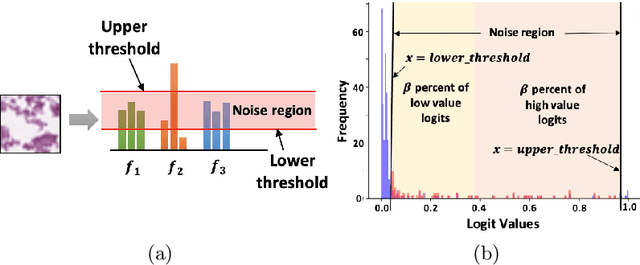
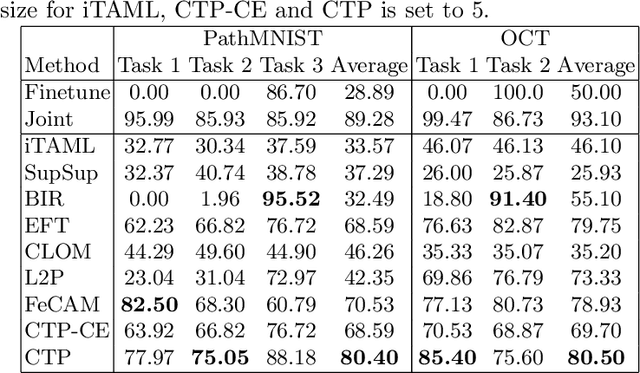
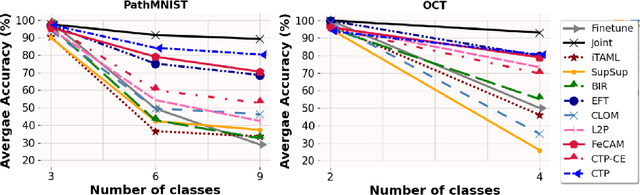
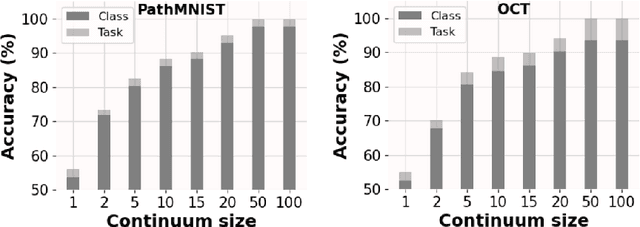
Deep learning models are widely recognized for their effectiveness in identifying medical image findings in disease classification. However, their limitations become apparent in the dynamic and ever-changing clinical environment, characterized by the continuous influx of newly annotated medical data from diverse sources. In this context, the need for continual learning becomes particularly paramount, not only to adapt to evolving medical scenarios but also to ensure the privacy of healthcare data. In our research, we emphasize the utilization of a network comprising expert classifiers, where a new expert classifier is added each time a new task is introduced. We present CTP, a task-id predictor that utilizes confidence scores, leveraging the probability distribution (logits) of the classifier to accurately determine the task-id at inference time. Logits are adjusted to ensure that classifiers yield a high-entropy distribution for data associated with tasks other than their own. By defining a noise region in the distribution and computing confidence scores, CTP achieves superior performance when compared to other relevant continual learning methods. Additionally, the performance of CTP can be further improved by providing it with a continuum of data at the time of inference.
RLPeri: Accelerating Visual Perimetry Test with Reinforcement Learning and Convolutional Feature Extraction
Mar 08, 2024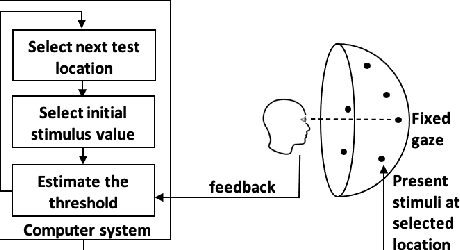
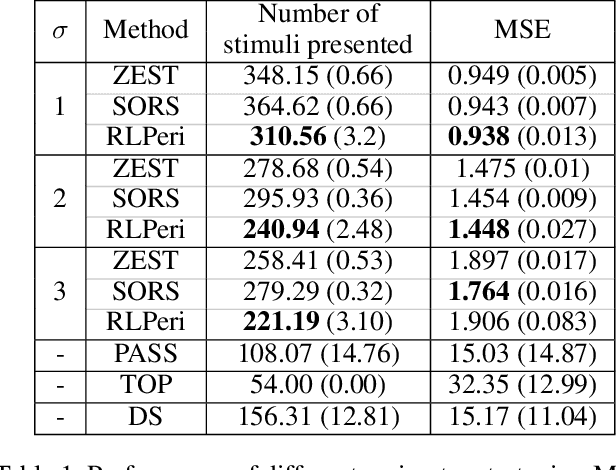
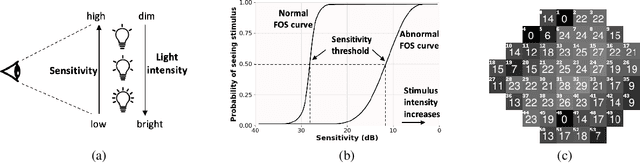
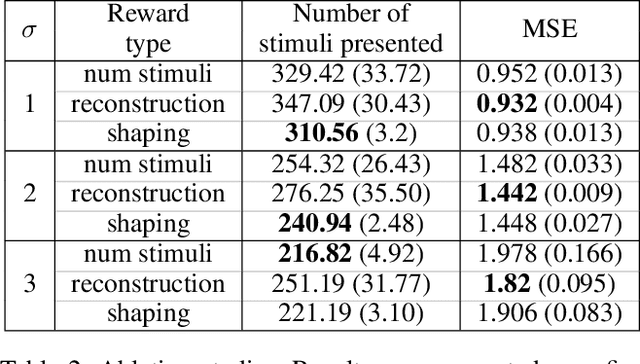
Visual perimetry is an important eye examination that helps detect vision problems caused by ocular or neurological conditions. During the test, a patient's gaze is fixed at a specific location while light stimuli of varying intensities are presented in central and peripheral vision. Based on the patient's responses to the stimuli, the visual field mapping and sensitivity are determined. However, maintaining high levels of concentration throughout the test can be challenging for patients, leading to increased examination times and decreased accuracy. In this work, we present RLPeri, a reinforcement learning-based approach to optimize visual perimetry testing. By determining the optimal sequence of locations and initial stimulus values, we aim to reduce the examination time without compromising accuracy. Additionally, we incorporate reward shaping techniques to further improve the testing performance. To monitor the patient's responses over time during testing, we represent the test's state as a pair of 3D matrices. We apply two different convolutional kernels to extract spatial features across locations as well as features across different stimulus values for each location. Through experiments, we demonstrate that our approach results in a 10-20% reduction in examination time while maintaining the accuracy as compared to state-of-the-art methods. With the presented approach, we aim to make visual perimetry testing more efficient and patient-friendly, while still providing accurate results.
* Published at AAAI-24
Learning Individual Policies in Large Multi-agent Systems through Local Variance Minimization
Dec 27, 2022In multi-agent systems with large number of agents, typically the contribution of each agent to the value of other agents is minimal (e.g., aggregation systems such as Uber, Deliveroo). In this paper, we consider such multi-agent systems where each agent is self-interested and takes a sequence of decisions and represent them as a Stochastic Non-atomic Congestion Game (SNCG). We derive key properties for equilibrium solutions in SNCG model with non-atomic and also nearly non-atomic agents. With those key equilibrium properties, we provide a novel Multi-Agent Reinforcement Learning (MARL) mechanism that minimizes variance across values of agents in the same state. To demonstrate the utility of this new mechanism, we provide detailed results on a real-world taxi dataset and also a generic simulator for aggregation systems. We show that our approach reduces the variance in revenues earned by taxi drivers, while still providing higher joint revenues than leading approaches.
Value Variance Minimization for Learning Approximate Equilibrium in Aggregation Systems
Mar 16, 2020
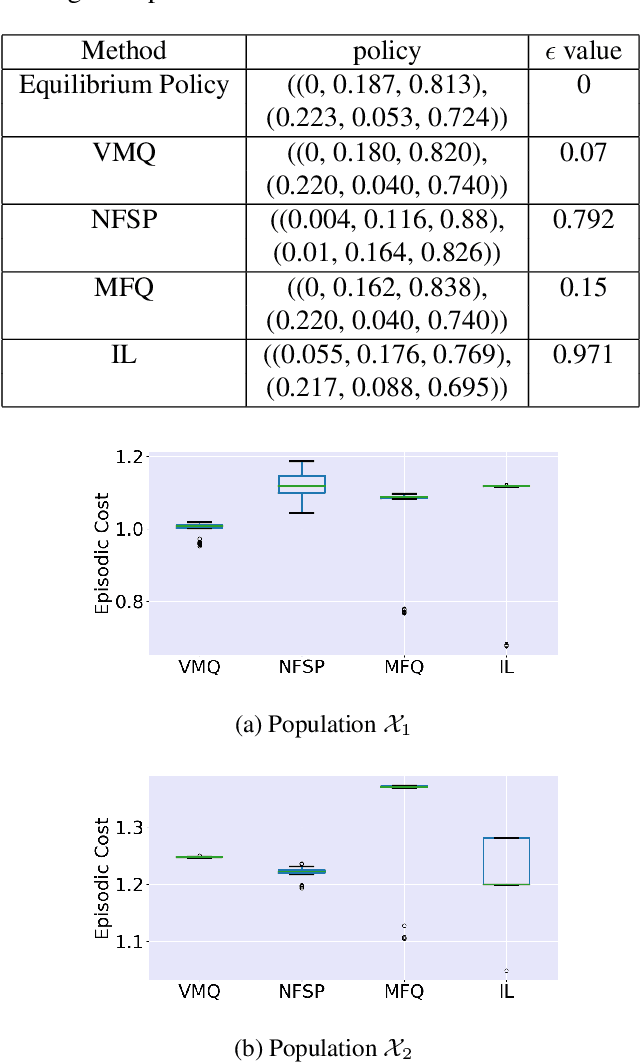
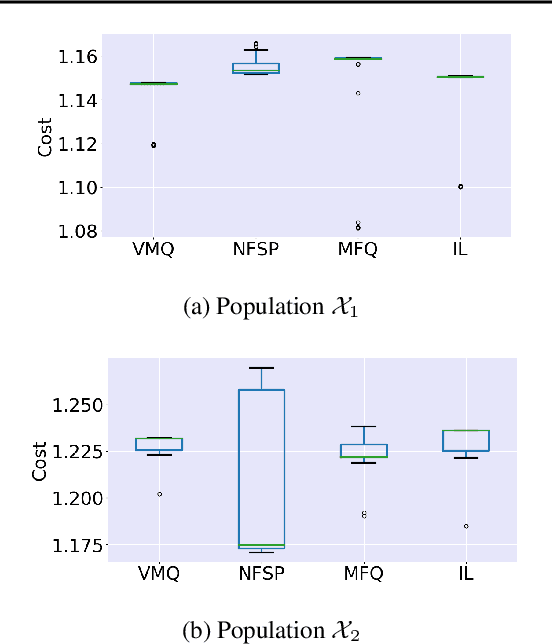
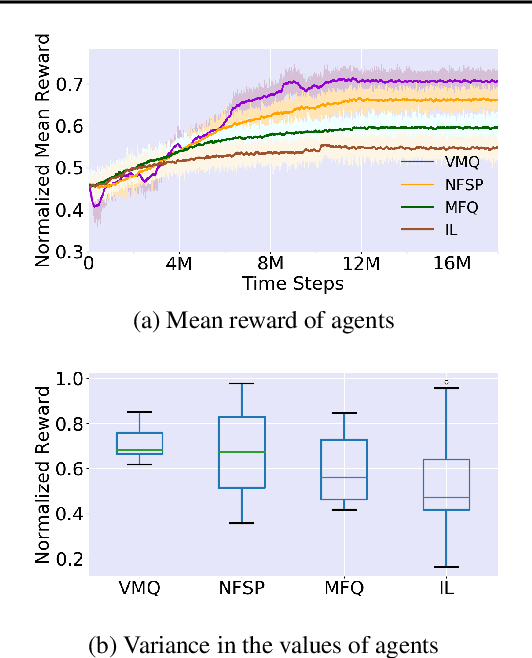
For effective matching of resources (e.g., taxis, food, bikes, shopping items) to customer demand, aggregation systems have been extremely successful. In aggregation systems, a central entity (e.g., Uber, Food Panda, Ofo) aggregates supply (e.g., drivers, delivery personnel) and matches demand to supply on a continuous basis (sequential decisions). Due to the objective of the central entity to maximize its profits, individual suppliers get sacrificed thereby creating incentive for individuals to leave the system. In this paper, we consider the problem of learning approximate equilibrium solutions (win-win solutions) in aggregation systems, so that individuals have an incentive to remain in the aggregation system. Unfortunately, such systems have thousands of agents and have to consider demand uncertainty and the underlying problem is a (Partially Observable) Stochastic Game. Given the significant complexity of learning or planning in a stochastic game, we make three key contributions: (a) To exploit infinitesimally small contribution of each agent and anonymity (reward and transitions between agents are dependent on agent counts) in interactions, we represent this as a Multi-Agent Reinforcement Learning (MARL) problem that builds on insights from non-atomic congestion games model; (b) We provide a novel variance reduction mechanism for moving joint solution towards Nash Equilibrium that exploits the infinitesimally small contribution of each agent; and finally (c) We provide detailed results on three different domains to demonstrate the utility of our approach in comparison to state-of-the-art methods.
Entropy Controlled Non-Stationarity for Improving Performance of Independent Learners in Anonymous MARL Settings
May 27, 2018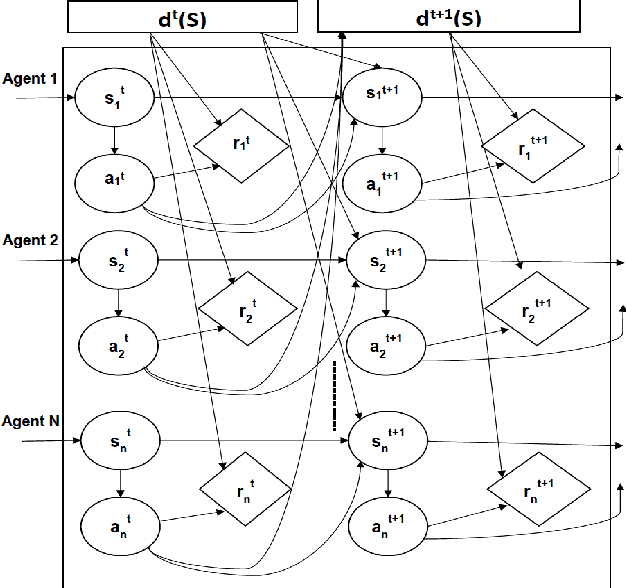
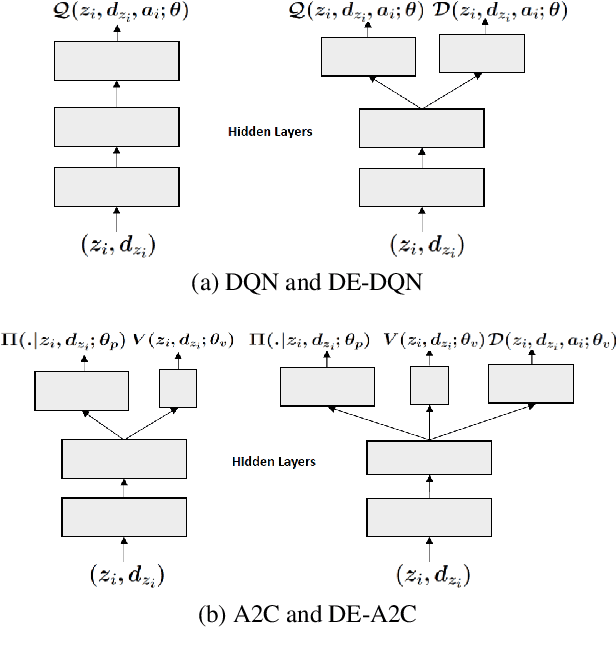
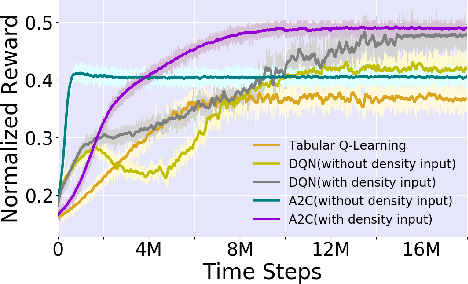
With the advent of sequential matching (of supply and demand) systems (uber, Lyft, Grab for taxis; ubereats, deliveroo, etc for food; amazon prime, lazada etc. for groceries) across many online and offline services, individuals (taxi drivers, delivery boys, delivery van drivers, etc.) earn more by being at the "right" place at the "right" time. We focus on learning techniques for providing guidance (on right locations to be at right times) to individuals in the presence of other "learning" individuals. Interactions between indivduals are anonymous, i.e, the outcome of an interaction (competing for demand) is independent of the identity of the agents and therefore we refer to these as Anonymous MARL settings. Existing research of relevance is on independent learning using Reinforcement Learning (RL) or on Multi-Agent Reinforcement Learning (MARL). The number of individuals in aggregation systems is extremely large and individuals have their own selfish interest (of maximising revenue). Therefore, traditional MARL approaches are either not scalable or assumptions of common objective or action coordination are not viable. In this paper, we focus on improving performance of independent reinforcement learners, specifically the popular Deep Q-Networks (DQN) and Advantage Actor Critic (A2C) approaches by exploiting anonymity. Specifically, we control non-stationarity introduced by other agents using entropy of agent density distribution. We demonstrate a significant improvement in revenue for individuals and for all agents together with our learners on a generic experimental set up for aggregation systems and a real world taxi dataset.