 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRLPeri: Accelerating Visual Perimetry Test with Reinforcement Learning and Convolutional Feature Extraction
Mar 08, 2024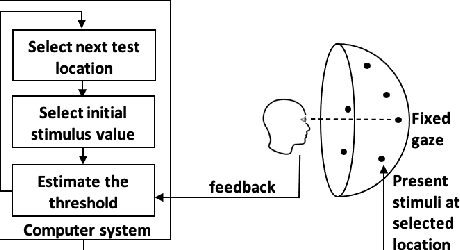
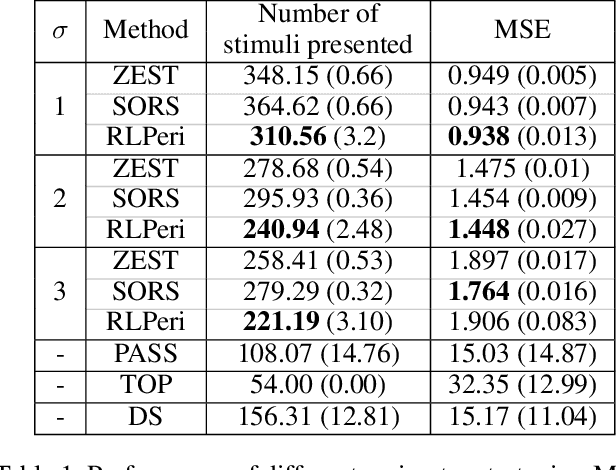
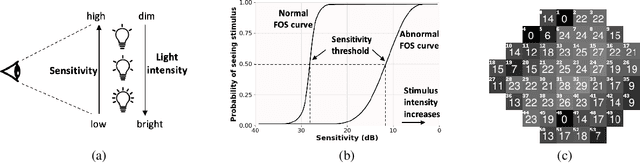
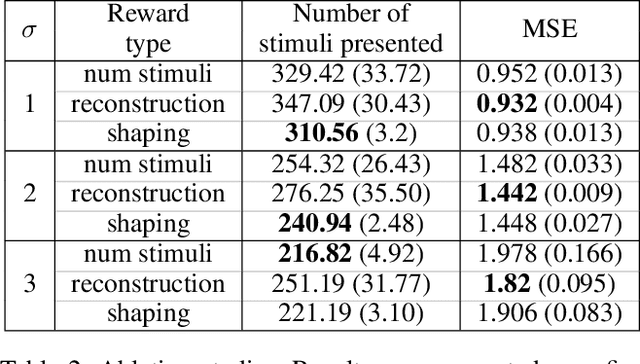
Visual perimetry is an important eye examination that helps detect vision problems caused by ocular or neurological conditions. During the test, a patient's gaze is fixed at a specific location while light stimuli of varying intensities are presented in central and peripheral vision. Based on the patient's responses to the stimuli, the visual field mapping and sensitivity are determined. However, maintaining high levels of concentration throughout the test can be challenging for patients, leading to increased examination times and decreased accuracy. In this work, we present RLPeri, a reinforcement learning-based approach to optimize visual perimetry testing. By determining the optimal sequence of locations and initial stimulus values, we aim to reduce the examination time without compromising accuracy. Additionally, we incorporate reward shaping techniques to further improve the testing performance. To monitor the patient's responses over time during testing, we represent the test's state as a pair of 3D matrices. We apply two different convolutional kernels to extract spatial features across locations as well as features across different stimulus values for each location. Through experiments, we demonstrate that our approach results in a 10-20% reduction in examination time while maintaining the accuracy as compared to state-of-the-art methods. With the presented approach, we aim to make visual perimetry testing more efficient and patient-friendly, while still providing accurate results.
* Published at AAAI-24
BOSS: A Benchmark for Human Belief Prediction in Object-context Scenarios
Jun 21, 2022

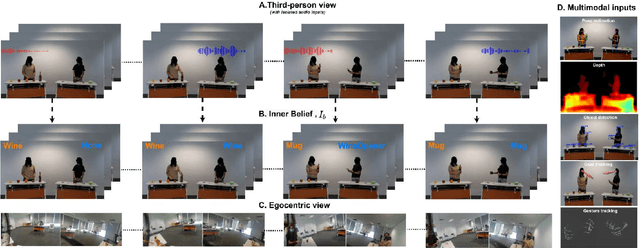

Humans with an average level of social cognition can infer the beliefs of others based solely on the nonverbal communication signals (e.g. gaze, gesture, pose and contextual information) exhibited during social interactions. This social cognitive ability to predict human beliefs and intentions is more important than ever for ensuring safe human-robot interaction and collaboration. This paper uses the combined knowledge of Theory of Mind (ToM) and Object-Context Relations to investigate methods for enhancing collaboration between humans and autonomous systems in environments where verbal communication is prohibited. We propose a novel and challenging multimodal video dataset for assessing the capability of artificial intelligence (AI) systems in predicting human belief states in an object-context scenario. The proposed dataset consists of precise labelling of human belief state ground-truth and multimodal inputs replicating all nonverbal communication inputs captured by human perception. We further evaluate our dataset with existing deep learning models and provide new insights into the effects of the various input modalities and object-context relations on the performance of the baseline models.