 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJEDI: Joint Embedding Diffusion World Model for Online Model-Based Reinforcement Learning
May 13, 2026Diffusion world models have recently become competitive for online model-based reinforcement learning, but current approaches expose a tension: pixel diffusion is effective but computationally expensive while the latest latent diffusion approach improves efficiency yet performs subpar. The latter also relies on separately trained latents rather than the end-to-end world-model objectives that have driven much of modern MBRL progress. In particular, JEPA-style predictive representation learning has emerged as an especially promising direction for world modeling and MBRL. Concurrently, diffusion-style objectives have gained traction across multiple domains, with iterative refinement as a promising approach for multimodal and stochastic targets. Taken together, these trends motivate Joint Embedding DIffusion (JEDI), the first online end-to-end latent diffusion world model. JEDI learns its latent space directly from the diffusion denoising loss with a JEPA framework, using denoising to learn and predict future latents rather than relying on reconstruction and pretrained models. We provide a theoretical motivation showing that conventional JEPA objectives induce a predictive information bottleneck, and that conditional diffusion denoising admits a closely related predictive-compression decomposition. Empirically, JEDI is competitive on Atari100k and outperforms the baseline with seperately trained latents where directly comparable. Relative to the pixel diffusion baseline, JEDI uses 43% less VRAM, over 3$\times$ faster world-model sampling, and 2.5$\times$ faster training. JEDI also exhibits a markedly different task-level performance profile from the pixel baseline, suggesting that end-to-end predictive latents change more than compute alone.
JEDI: Latent End-to-end Diffusion Mitigates Agent-Human Performance Asymmetry in Model-Based Reinforcement Learning
May 26, 2025Recent advances in model-based reinforcement learning (MBRL) have achieved super-human level performance on the Atari100k benchmark, driven by reinforcement learning agents trained on powerful diffusion world models. However, we identify that the current aggregates mask a major performance asymmetry: MBRL agents dramatically outperform humans in some tasks despite drastically underperforming in others, with the former inflating the aggregate metrics. This is especially pronounced in pixel-based agents trained with diffusion world models. In this work, we address the pronounced asymmetry observed in pixel-based agents as an initial attempt to reverse the worrying upward trend observed in them. We address the problematic aggregates by delineating all tasks as Agent-Optimal or Human-Optimal and advocate for equal importance on metrics from both sets. Next, we hypothesize this pronounced asymmetry is due to the lack of temporally-structured latent space trained with the World Model objective in pixel-based methods. Lastly, to address this issue, we propose Joint Embedding DIffusion (JEDI), a novel latent diffusion world model trained end-to-end with the self-consistency objective. JEDI outperforms SOTA models in human-optimal tasks while staying competitive across the Atari100k benchmark, and runs 3 times faster with 43% lower memory than the latest pixel-based diffusion baseline. Overall, our work rethinks what it truly means to cross human-level performance in Atari100k.
Octopi: Object Property Reasoning with Large Tactile-Language Models
May 05, 2024



Physical reasoning is important for effective robot manipulation. Recent work has investigated both vision and language modalities for physical reasoning; vision can reveal information about objects in the environment and language serves as an abstraction and communication medium for additional context. Although these works have demonstrated success on a variety of physical reasoning tasks, they are limited to physical properties that can be inferred from visual or language inputs. In this work, we investigate combining tactile perception with language, which enables embodied systems to obtain physical properties through interaction and apply common-sense reasoning. We contribute a new dataset PhysiCleAR, which comprises both physical/property reasoning tasks and annotated tactile videos obtained using a GelSight tactile sensor. We then introduce Octopi, a system that leverages both tactile representation learning and large vision-language models to predict and reason about tactile inputs with minimal language fine-tuning. Our evaluations on PhysiCleAR show that Octopi is able to effectively use intermediate physical property predictions to improve physical reasoning in both trained tasks and for zero-shot reasoning. PhysiCleAR and Octopi are available on https://github.com/clear-nus/octopi.
A Review on Robot Manipulation Methods in Human-Robot Interactions
Sep 09, 2023



Robot manipulation is an important part of human-robot interaction technology. However, traditional pre-programmed methods can only accomplish simple and repetitive tasks. To enable effective communication between robots and humans, and to predict and adapt to uncertain environments, this paper reviews recent autonomous and adaptive learning in robotic manipulation algorithms. It includes typical applications and challenges of human-robot interaction, fundamental tasks of robot manipulation and one of the most widely used formulations of robot manipulation, Markov Decision Process. Recent research focusing on robot manipulation is mainly based on Reinforcement Learning and Imitation Learning. This review paper shows the importance of Deep Reinforcement Learning, which plays an important role in manipulating robots to complete complex tasks in disturbed and unfamiliar environments. With the introduction of Imitation Learning, it is possible for robot manipulation to get rid of reward function design and achieve a simple, stable and supervised learning process. This paper reviews and compares the main features and popular algorithms for both Reinforcement Learning and Imitation Learning.
BOSS: A Benchmark for Human Belief Prediction in Object-context Scenarios
Jun 21, 2022

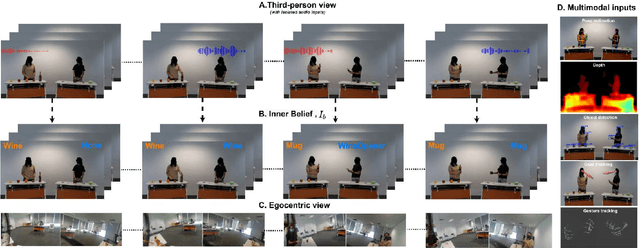

Humans with an average level of social cognition can infer the beliefs of others based solely on the nonverbal communication signals (e.g. gaze, gesture, pose and contextual information) exhibited during social interactions. This social cognitive ability to predict human beliefs and intentions is more important than ever for ensuring safe human-robot interaction and collaboration. This paper uses the combined knowledge of Theory of Mind (ToM) and Object-Context Relations to investigate methods for enhancing collaboration between humans and autonomous systems in environments where verbal communication is prohibited. We propose a novel and challenging multimodal video dataset for assessing the capability of artificial intelligence (AI) systems in predicting human belief states in an object-context scenario. The proposed dataset consists of precise labelling of human belief state ground-truth and multimodal inputs replicating all nonverbal communication inputs captured by human perception. We further evaluate our dataset with existing deep learning models and provide new insights into the effects of the various input modalities and object-context relations on the performance of the baseline models.
Good Time to Ask: A Learning Framework for Asking for Help in Embodied Visual Navigation
Jun 20, 2022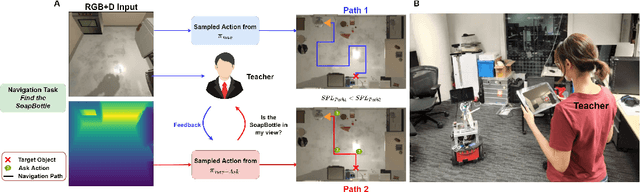
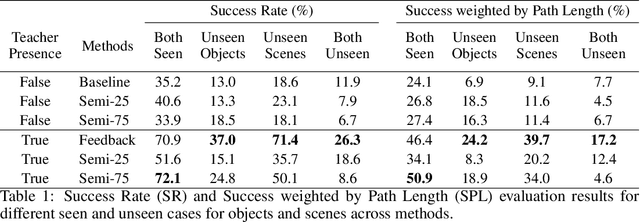
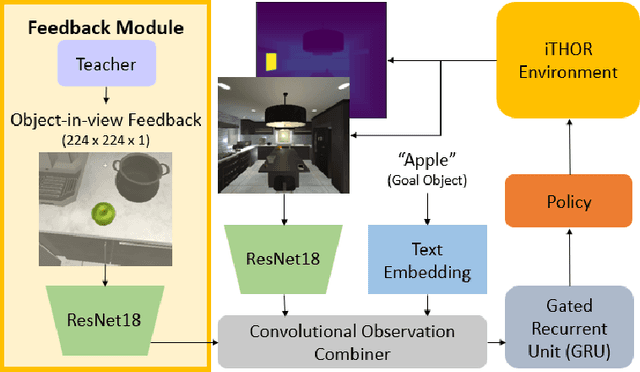
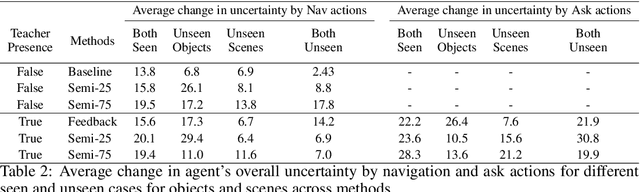
In reality, it is often more efficient to ask for help than to search the entire space to find an object with an unknown location. We present a learning framework that enables an agent to actively ask for help in such embodied visual navigation tasks, where the feedback informs the agent of where the goal is in its view. To emulate the real-world scenario that a teacher may not always be present, we propose a training curriculum where feedback is not always available. We formulate an uncertainty measure of where the goal is and use empirical results to show that through this approach, the agent learns to ask for help effectively while remaining robust when feedback is not available.
ABCDE: An Agent-Based Cognitive Development Environment
Jun 10, 2022

Children's cognitive abilities are sometimes cited as AI benchmarks. How can the most common 1,000 concepts (89\% of everyday use) be learnt in a naturalistic children's setting? Cognitive development in children is about quality, and new concepts can be conveyed via simple examples. Our approach of knowledge scaffolding uses simple objects and actions to convey concepts, like how children are taught. We introduce ABCDE, an interactive 3D environment modeled after a typical playroom for children. It comes with 300+ unique 3D object assets (mostly toys), and a large action space for child and parent agents to interact with objects and each other. ABCDE is the first environment aimed at mimicking a naturalistic setting for cognitive development in children; no other environment focuses on high-level concept learning through learner-teacher interactions. The simulator can be found at https://pypi.org/project/ABCDESim/1.0.0/
PIP: Physical Interaction Prediction via Mental Imagery with Span Selection
Sep 10, 2021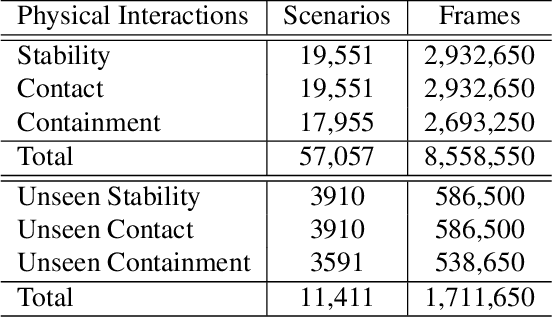

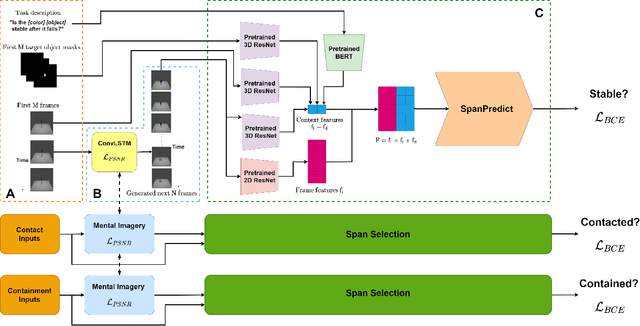

To align advanced artificial intelligence (AI) with human values and promote safe AI, it is important for AI to predict the outcome of physical interactions. Even with the ongoing debates on how humans predict the outcomes of physical interactions among objects in the real world, there are works attempting to tackle this task via cognitive-inspired AI approaches. However, there is still a lack of AI approaches that mimic the mental imagery humans use to predict physical interactions in the real world. In this work, we propose a novel PIP scheme: Physical Interaction Prediction via Mental Imagery with Span Selection. PIP utilizes a deep generative model to output future frames of physical interactions among objects before extracting crucial information for predicting physical interactions by focusing on salient frames using span selection. To evaluate our model, we propose a large-scale SPACE+ dataset of synthetic video frames, including three physical interaction events in a 3D environment. Our experiments show that PIP outperforms baselines and human performance in physical interaction prediction for both seen and unseen objects. Furthermore, PIP's span selection scheme can effectively identify the frames where physical interactions among objects occur within the generated frames, allowing for added interpretability.
A Survey of Embodied AI: From Simulators to Research Tasks
Mar 14, 2021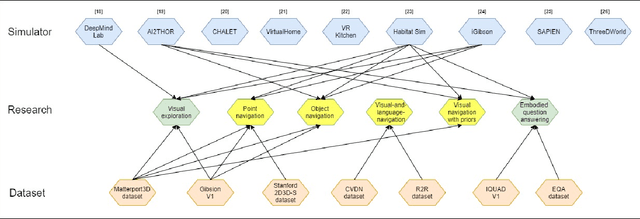
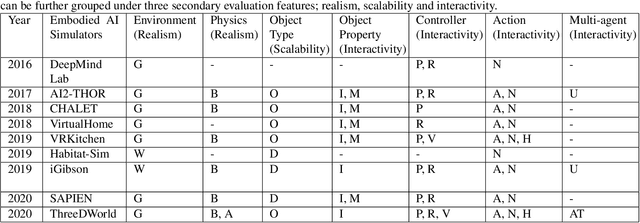


There has been an emerging paradigm shift from the era of "internet AI" to "embodied AI", whereby AI algorithms and agents no longer simply learn from datasets of images, videos or text curated primarily from the internet. Instead, they learn through embodied physical interactions with their environments, whether real or simulated. Consequently, there has been substantial growth in the demand for embodied AI simulators to support a diversity of embodied AI research tasks. This growing interest in embodied AI is beneficial to the greater pursuit of artificial general intelligence, but there is no contemporary and comprehensive survey of this field. This paper comprehensively surveys state-of-the-art embodied AI simulators and research, mapping connections between these. By benchmarking nine state-of-the-art embodied AI simulators in terms of seven features, this paper aims to understand the simulators in their provision for use in embodied AI research. Finally, based upon the simulators and a pyramidal hierarchy of embodied AI research tasks, this paper surveys the main research tasks in embodied AI -- visual exploration, visual navigation and embodied question answering (QA), covering the state-of-the-art approaches, evaluation and datasets.
Actionet: An Interactive End-To-End Platform For Task-Based Data Collection And Augmentation In 3D Environment
Oct 03, 2020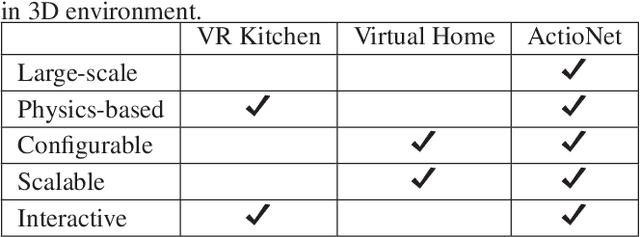
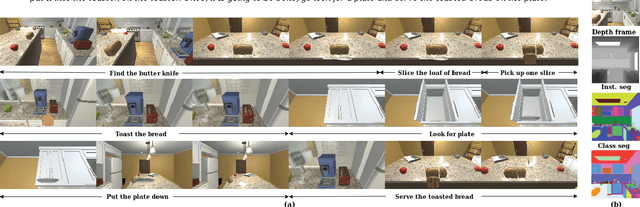
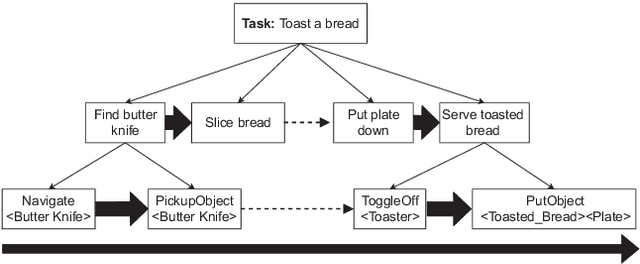
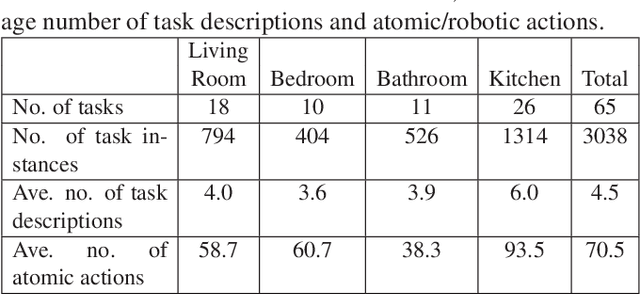
The problem of task planning for artificial agents remains largely unsolved. While there has been increasing interest in data-driven approaches for the study of task planning for artificial agents, a significant remaining bottleneck is the dearth of large-scale comprehensive task-based datasets. In this paper, we present ActioNet, an interactive end-to-end platform for data collection and augmentation of task-based dataset in 3D environment. Using ActioNet, we collected a large-scale comprehensive task-based dataset, comprising over 3000 hierarchical task structures and videos. Using the hierarchical task structures, the videos are further augmented across 50 different scenes to give over 150,000 video. To our knowledge, ActioNet is the first interactive end-to-end platform for such task-based dataset generation and the accompanying dataset is the largest task-based dataset of such comprehensive nature. The ActioNet platform and dataset will be made available to facilitate research in hierarchical task planning.