 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuotient DAGs for Off-Policy Evaluation:Forward-Flow Importance Sampling and Exact Slate Propensities
May 28, 2026Off-policy evaluation estimates how a target policy would perform using data collected by a different behavior policy, which is crucial when online testing is costly or risky, such as in recommendation or healthcare. Standard importance sampling reweights each logged trajectory, but it can treat details of the generation process as meaningful even when the evaluation target ignores them: for example, an autoregressive slate recommender may generate an ordered sequence of items while the reward and downstream estimator depend only on the unordered slate. This creates nuisance variance and a computational gap, since exact unordered slate propensities require summing over all generation orders. We introduce a quotient-DAG view that merges histories equivalent for evaluation and assigns weights using target-to-behavior forward-flow ratios on the merged graph. For slate recommendation under a set-sufficient next-item interface, this yields Forward-DP, a subset-DAG dynamic program that computes exact unordered propensities without factorial enumeration. The resulting propensity primitive enables practical propensity-based evaluation and model selection for context-dependent autoregressive slate loggers.
JEDI: Joint Embedding Diffusion World Model for Online Model-Based Reinforcement Learning
May 13, 2026Diffusion world models have recently become competitive for online model-based reinforcement learning, but current approaches expose a tension: pixel diffusion is effective but computationally expensive while the latest latent diffusion approach improves efficiency yet performs subpar. The latter also relies on separately trained latents rather than the end-to-end world-model objectives that have driven much of modern MBRL progress. In particular, JEPA-style predictive representation learning has emerged as an especially promising direction for world modeling and MBRL. Concurrently, diffusion-style objectives have gained traction across multiple domains, with iterative refinement as a promising approach for multimodal and stochastic targets. Taken together, these trends motivate Joint Embedding DIffusion (JEDI), the first online end-to-end latent diffusion world model. JEDI learns its latent space directly from the diffusion denoising loss with a JEPA framework, using denoising to learn and predict future latents rather than relying on reconstruction and pretrained models. We provide a theoretical motivation showing that conventional JEPA objectives induce a predictive information bottleneck, and that conditional diffusion denoising admits a closely related predictive-compression decomposition. Empirically, JEDI is competitive on Atari100k and outperforms the baseline with seperately trained latents where directly comparable. Relative to the pixel diffusion baseline, JEDI uses 43% less VRAM, over 3$\times$ faster world-model sampling, and 2.5$\times$ faster training. JEDI also exhibits a markedly different task-level performance profile from the pixel baseline, suggesting that end-to-end predictive latents change more than compute alone.
Absurd World: A Simple Yet Powerful Method to Absurdify the Real-world for Probing LLM Reasoning Capabilities
May 10, 2026While extremely powerful and versatile at various tasks, the thinking capabilities of large language models (LLMs) are often put under scrutiny as they sometimes fail to solve problems that humans can systematically solve. However, recent literature focuses on breaking LLM reasoning with increasingly complex problems, and whether an LLM is robust in simple logical reasoning remains underexplored. This paper proposes Absurd World, a benchmarking framework, to test LLMs against altered realism, where scenarios are logically coherent, and humans can easily solve the tasks. Absurd World breaks a real-world model into symbols, actions, sequences, and events, which are automatically altered to create absurd worlds where the logic to solve the tasks remains the same. It evaluates a large collection of models with simple and advanced prompting techniques, and proves that it is an effective tool to determine LLMs' ability to think logically, ignoring the patterns learned from the real world. One can use this framework to extensively test an LLM against a real-world problem to verify whether the LLM's reasoning capability is robust against variations of the task.
Resolving the bias-precision paradox with stochastic causal representation learning for personalized medicine
May 07, 2026Estimating individualized treatment effects from longitudinal observational data is central to data-driven medicine, yet existing methods face a fundamental limitation: reducing confounding bias often suppresses clinically informative heterogeneity, degrading patient-specific predictions. Here, we identify this tension as a bias-precision paradox in causal representation learning and introduce sampling-based maximum mean discrepancy (sMMD), a stochastic alignment strategy that replaces global adversarial balancing with subset-level matching. We instantiate this approach in a framework for counterfactual outcome prediction with attribution-grounded interpretability. Across two large-scale ICU cohorts (n = 27,783), our framework improves accuracy under distribution shift, reducing error by up to 11.5% and substantially increasing recall in high-risk tasks. Mechanistic analyses show that sMMD selectively preserves clinically decisive variables. In human-AI evaluation, our method outperforms clinicians-in-training and large language models, and improves clinician accuracy by 14.7% while reducing decision time, enabling interpretable, real-time clinical decision support.
Early Quantization Shrinks Codebook: A Simple Fix for Diversity-Preserving Tokenization
Mar 17, 2026Vector quantization is a technique in machine learning that discretizes continuous representations into a set of discrete vectors. It is widely employed in tokenizing data representations for large language models, diffusion models, and other generative models. Despite its prevalence, the characteristics and behaviors of vector quantization in generative models remain largely underexplored. In this study, we systematically investigate the issue of collapses in vector quantization, where collapsed representations are observed across discrete codebook tokens and continuous latent embeddings. By leveraging both synthetic and real datasets, we identify the severity of each type of collapses and triggering conditions. Our analysis reveals that random initialization and limited encoder capacity result in tokens collapse and embeddings collapse. Building on these findings, we propose potential solutions aimed at mitigating each collapse. To the best of our knowledge, this is the first comprehensive study examining representation collapsing problems in vector quantization.
VQKV: High-Fidelity and High-Ratio Cache Compression via Vector-Quantization
Mar 17, 2026The growing context length of Large Language Models (LLMs) enlarges the Key-Value (KV) cache, limiting deployment in resource-limited environments. Prior training-free approaches for KV cache compression typically rely on low-rank approximation or scalar quantization, which fail to simultaneously achieve high compression ratios and high reconstruction fidelity. We propose VQKV, a novel, training-free method introducing vector quantization (VQ) to obtain highly compressed KV representations while preserving high model fidelity, allowing for the representation of thousands of floating-point values with just a few integer indices. As a result, VQKV achieves an 82.8\% compression ratio on LLaMA3.1-8B while retaining 98.6\% of the baseline performance on LongBench and enabling 4.3x longer generation length on the same memory footprint.
Expected Return Causes Outcome-Level Mode Collapse in Reinforcement Learning and How to Fix It with Inverse Probability Scaling
Jan 29, 2026Many reinforcement learning (RL) problems admit multiple terminal solutions of comparable quality, where the goal is not to identify a single optimum but to represent a diverse set of high-quality outcomes. Nevertheless, policies trained by standard expected return maximization routinely collapse onto a small subset of outcomes, a phenomenon commonly attributed to insufficient exploration or weak regularization. We show that this explanation is incomplete: outcome level mode collapse is a structural consequence of the expected-return objective itself. Under idealized learning dynamics, the log-probability ratio between any two outcomes evolves linearly in their reward difference, implying exponential ratio divergence and inevitable collapse independent of the exploration strategy, entropy regularization, or optimization algorithm. We identify the source of this pathology as the probability multiplier inside the expectation and propose a minimal correction: inverse probability scaling, which removes outcome-frequency amplification from the learning signal, fundamentally changes the learning dynamics, and provably yields reward-proportional terminal distributions, preventing collapse in multimodal settings. We instantiate this principle in Group Relative Policy Optimization (GRPO) as a drop-in modification, IPS-GRPO, requiring no auxiliary models or architectural changes. Across different reasoning and molecular generation tasks, IPS-GRPO consistently reduces outcome-level mode collapse while matching or exceeding baseline performance, suggesting that correcting the objective rather than adding exploration heuristics is key to reliable multimodal policy optimization.
AI-generated data contamination erodes pathological variability and diagnostic reliability
Jan 21, 2026Generative artificial intelligence (AI) is rapidly populating medical records with synthetic content, creating a feedback loop where future models are increasingly at risk of training on uncurated AI-generated data. However, the clinical consequences of this AI-generated data contamination remain unexplored. Here, we show that in the absence of mandatory human verification, this self-referential cycle drives a rapid erosion of pathological variability and diagnostic reliability. By analysing more than 800,000 synthetic data points across clinical text generation, vision-language reporting, and medical image synthesis, we find that models progressively converge toward generic phenotypes regardless of the model architecture. Specifically, rare but critical findings, including pneumothorax and effusions, vanish from the synthetic content generated by AI models, while demographic representations skew heavily toward middle-aged male phenotypes. Crucially, this degradation is masked by false diagnostic confidence; models continue to issue reassuring reports while failing to detect life-threatening pathology, with false reassurance rates tripling to 40%. Blinded physician evaluation confirms that this decoupling of confidence and accuracy renders AI-generated documentation clinically useless after just two generations. We systematically evaluate three mitigation strategies, finding that while synthetic volume scaling fails to prevent collapse, mixing real data with quality-aware filtering effectively preserves diversity. Ultimately, our results suggest that without policy-mandated human oversight, the deployment of generative AI threatens to degrade the very healthcare data ecosystems it relies upon.
Bridging Mechanistic Interpretability and Prompt Engineering with Gradient Ascent for Interpretable Persona Control
Jan 06, 2026Controlling emergent behavioral personas (e.g., sycophancy, hallucination) in Large Language Models (LLMs) is critical for AI safety, yet remains a persistent challenge. Existing solutions face a dilemma: manual prompt engineering is intuitive but unscalable and imprecise, while automatic optimization methods are effective but operate as "black boxes" with no interpretable connection to model internals. We propose a novel framework that adapts gradient ascent to LLMs, enabling targeted prompt discovery. In specific, we propose two methods, RESGA and SAEGA, that both optimize randomly initialized prompts to achieve better aligned representation with an identified persona direction. We introduce fluent gradient ascent to control the fluency of discovered persona steering prompts. We demonstrate RESGA and SAEGA's effectiveness across Llama 3.1, Qwen 2.5, and Gemma 3 for steering three different personas,sycophancy, hallucination, and myopic reward. Crucially, on sycophancy, our automatically discovered prompts achieve significant improvement (49.90% compared with 79.24%). By grounding prompt discovery in mechanistically meaningful features, our method offers a new paradigm for controllable and interpretable behavior modification.
How does My Model Fail? Automatic Identification and Interpretation of Physical Plausibility Failure Modes with Matryoshka Transcoders
Nov 18, 2025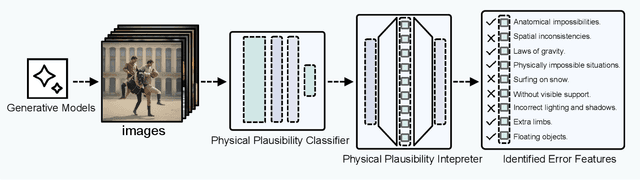
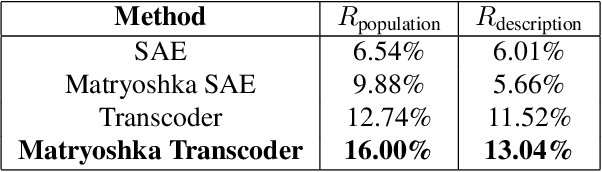
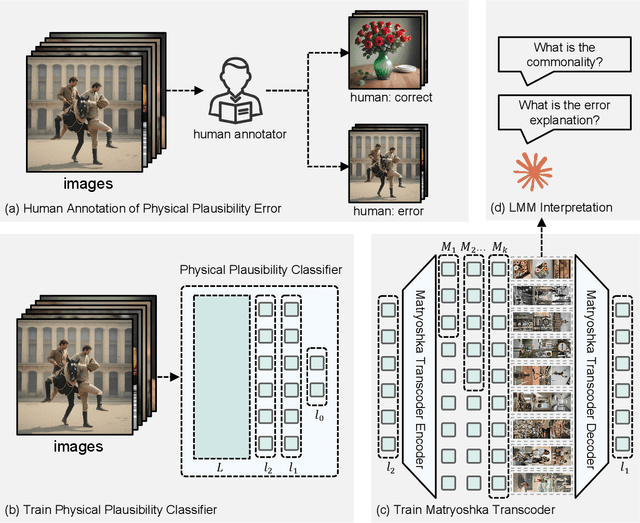
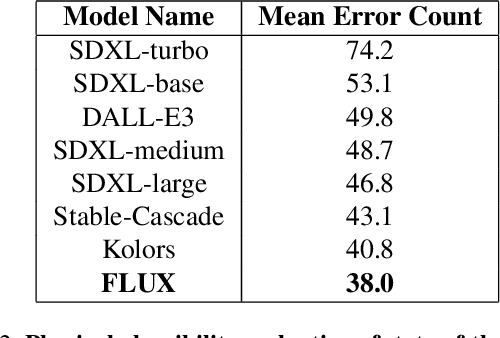
Although recent generative models are remarkably capable of producing instruction-following and realistic outputs, they remain prone to notable physical plausibility failures. Though critical in applications, these physical plausibility errors often escape detection by existing evaluation methods. Furthermore, no framework exists for automatically identifying and interpreting specific physical error patterns in natural language, preventing targeted model improvements. We introduce Matryoshka Transcoders, a novel framework for the automatic discovery and interpretation of physical plausibility features in generative models. Our approach extends the Matryoshka representation learning paradigm to transcoder architectures, enabling hierarchical sparse feature learning at multiple granularity levels. By training on intermediate representations from a physical plausibility classifier and leveraging large multimodal models for interpretation, our method identifies diverse physics-related failure modes without manual feature engineering, achieving superior feature relevance and feature accuracy compared to existing approaches. We utilize the discovered visual patterns to establish a benchmark for evaluating physical plausibility in generative models. Our analysis of eight state-of-the-art generative models provides valuable insights into how these models fail to follow physical constraints, paving the way for further model improvements.