 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Discrete Optimisation Via Decoupled Straight-Through Gumbel-Softmax
Oct 17, 2024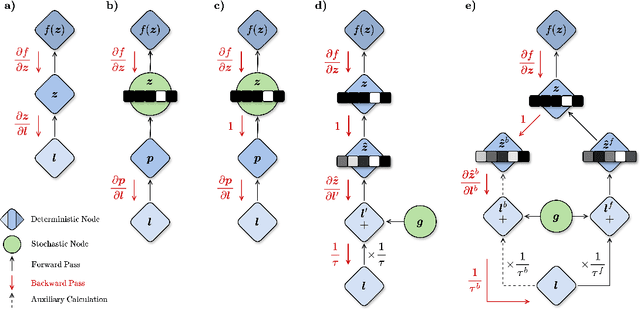

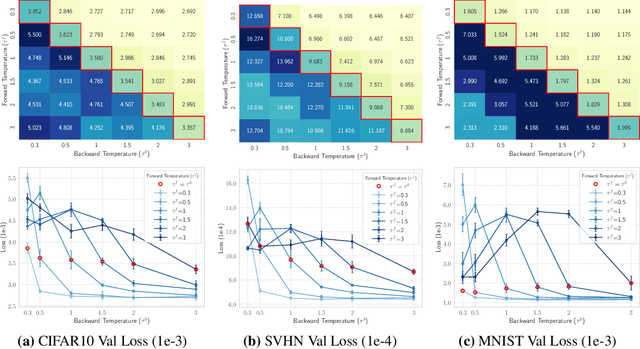
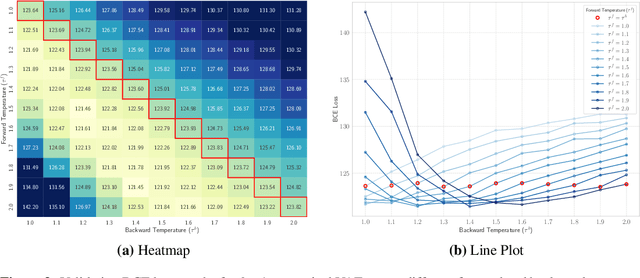
Discrete representations play a crucial role in many deep learning architectures, yet their non-differentiable nature poses significant challenges for gradient-based optimization. To address this issue, various gradient estimators have been developed, including the Straight-Through Gumbel-Softmax (ST-GS) estimator, which combines the Straight-Through Estimator (STE) and the Gumbel-based reparameterization trick. However, the performance of ST-GS is highly sensitive to temperature, with its selection often compromising gradient fidelity. In this work, we propose a simple yet effective extension to ST-GS by employing decoupled temperatures for forward and backward passes, which we refer to as "Decoupled ST-GS". We show that our approach significantly enhances the original ST-GS through extensive experiments across multiple tasks and datasets. We further investigate the impact of our method on gradient fidelity from multiple perspectives, including the gradient gap and the bias-variance trade-off of estimated gradients. Our findings contribute to the ongoing effort to improve discrete optimization in deep learning, offering a practical solution that balances simplicity and effectiveness.
Gaussian Mixture Vector Quantization with Aggregated Categorical Posterior
Oct 14, 2024



The vector quantization is a widely used method to map continuous representation to discrete space and has important application in tokenization for generative mode, bottlenecking information and many other tasks in machine learning. Vector Quantized Variational Autoencoder (VQ-VAE) is a type of variational autoencoder using discrete embedding as latent. We generalize the technique further, enriching the probabilistic framework with a Gaussian mixture as the underlying generative model. This framework leverages a codebook of latent means and adaptive variances to capture complex data distributions. This principled framework avoids various heuristics and strong assumptions that are needed with the VQ-VAE to address training instability and to improve codebook utilization. This approach integrates the benefits of both discrete and continuous representations within a variational Bayesian framework. Furthermore, by introducing the \textit{Aggregated Categorical Posterior Evidence Lower Bound} (ALBO), we offer a principled alternative optimization objective that aligns variational distributions with the generative model. Our experiments demonstrate that GM-VQ improves codebook utilization and reduces information loss without relying on handcrafted heuristics.
VQSynery: Robust Drug Synergy Prediction With Vector Quantization Mechanism
Mar 05, 2024The pursuit of optimizing cancer therapies is significantly advanced by the accurate prediction of drug synergy. Traditional methods, such as clinical trials, are reliable yet encumbered by extensive time and financial demands. The emergence of high-throughput screening and computational innovations has heralded a shift towards more efficient methodologies for exploring drug interactions. In this study, we present VQSynergy, a novel framework that employs the Vector Quantization (VQ) mechanism, integrated with gated residuals and a tailored attention mechanism, to enhance the precision and generalizability of drug synergy predictions. Our findings demonstrate that VQSynergy surpasses existing models in terms of robustness, particularly under Gaussian noise conditions, highlighting its superior performance and utility in the complex and often noisy domain of drug synergy research. This study underscores the potential of VQSynergy in revolutionizing the field through its advanced predictive capabilities, thereby contributing to the optimization of cancer treatment strategies.