 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Clinician-Friendly Platform for Ophthalmic Image Analysis Without Technical Barriers
Apr 22, 2025Artificial intelligence (AI) shows remarkable potential in medical imaging diagnostics, but current models typically require retraining when deployed across different clinical centers, limiting their widespread adoption. We introduce GlobeReady, a clinician-friendly AI platform that enables ocular disease diagnosis without retraining/fine-tuning or technical expertise. GlobeReady achieves high accuracy across imaging modalities: 93.9-98.5% for an 11-category fundus photo dataset and 87.2-92.7% for a 15-category OCT dataset. Through training-free local feature augmentation, it addresses domain shifts across centers and populations, reaching an average accuracy of 88.9% across five centers in China, 86.3% in Vietnam, and 90.2% in the UK. The built-in confidence-quantifiable diagnostic approach further boosted accuracy to 94.9-99.4% (fundus) and 88.2-96.2% (OCT), while identifying out-of-distribution cases at 86.3% (49 CFP categories) and 90.6% (13 OCT categories). Clinicians from multiple countries rated GlobeReady highly (average 4.6 out of 5) for its usability and clinical relevance. These results demonstrate GlobeReady's robust, scalable diagnostic capability and potential to support ophthalmic care without technical barriers.
Beamforming for PIN Diode-Based IRS-Assisted Systems Under a Phase Shift-Dependent Power Consumption Model
Aug 03, 2024



Intelligent reflecting surfaces (IRSs) have been regarded as a promising enabler for future wireless communication systems. In the literature, IRSs have been considered power-free or assumed to have constant power consumption. However, recent experimental results have shown that for positive-intrinsic-negative (PIN) diode-based IRSs, the power consumption dynamically changes with the phase shift configuration. This phase shift-dependent power consumption (PS-DPC) introduces a challenging power allocation problem between base station (BS) and IRS. To tackle this issue, in this paper, we investigate a rate maximization problem for IRS-assisted systems under a practical PS-DPC model. For the single-user case, we propose a generalized Benders decomposition-based beamforming method to maximize the achievable rate while satisfying a total system power consumption constraint. Moreover, we propose a low-complexity beamforming design, where the powers allocated to BS and IRS are optimized offline based on statistical channel state information. Furthermore, for the multi-user case, we solve an equivalent weighted mean square error minimization problem with two different joint power allocation and phase shift optimization methods. Simulation results indicate that compared to baseline schemes, our proposed methods can flexibly optimize the power allocation between BS and IRS, thus achieving better performance. The optimized power allocation strategy strongly depends on the system power budget. When the system power budget is high, the PS-DPC is not the dominant factor in the system power consumption, allowing the IRS to turn on as many PIN diodes as needed to achieve high beamforming quality. When the system power budget is limited, however, more power tends to be allocated to the BS to enhance the transmit power, resulting in a lower beamforming quality at the IRS due to the reduced PS-DPC budget.
Enhancing Diagnostic Reliability of Foundation Model with Uncertainty Estimation in OCT Images
Jun 18, 2024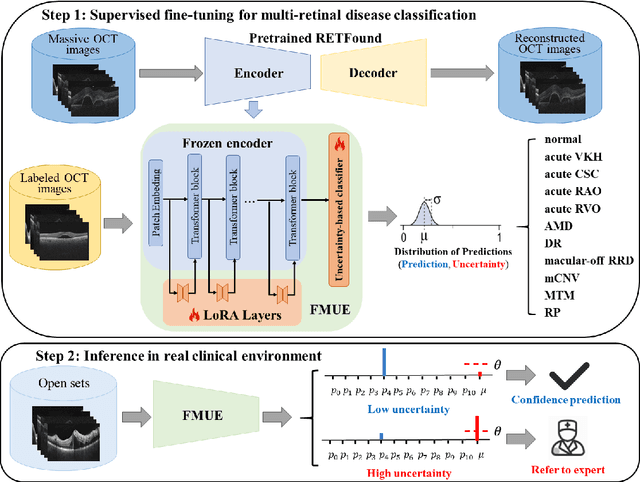
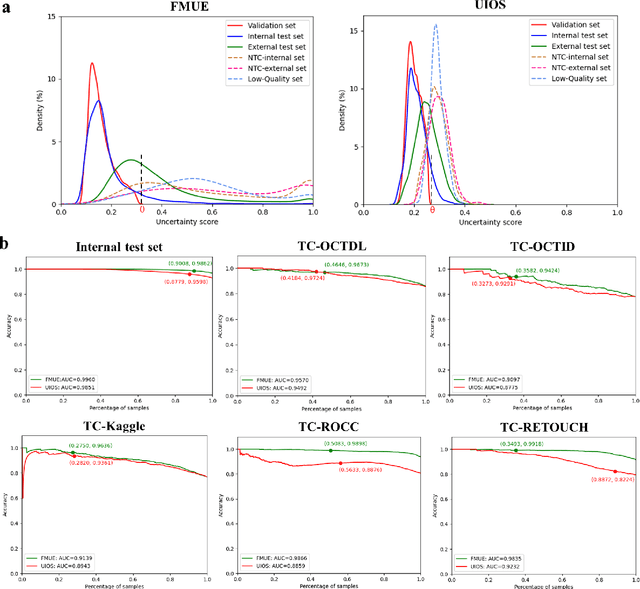
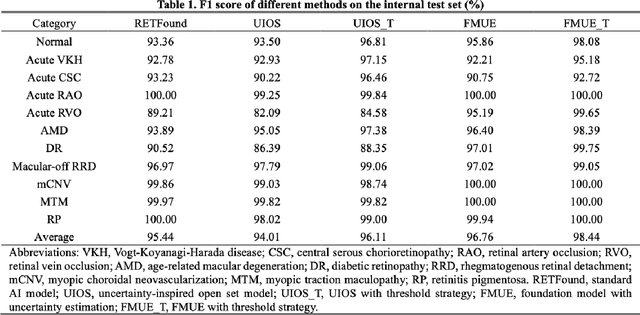
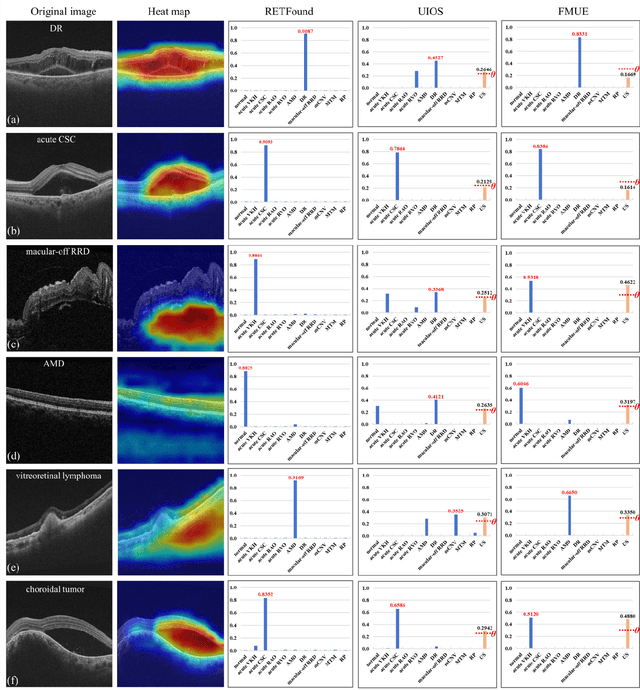
Inability to express the confidence level and detect unseen classes has limited the clinical implementation of artificial intelligence in the real-world. We developed a foundation model with uncertainty estimation (FMUE) to detect 11 retinal conditions on optical coherence tomography (OCT). In the internal test set, FMUE achieved a higher F1 score of 96.76% than two state-of-the-art algorithms, RETFound and UIOS, and got further improvement with thresholding strategy to 98.44%. In the external test sets obtained from other OCT devices, FMUE achieved an accuracy of 88.75% and 92.73% before and after thresholding. Our model is superior to two ophthalmologists with a higher F1 score (95.17% vs. 61.93% &71.72%). Besides, our model correctly predicts high uncertainty scores for samples with ambiguous features, of non-target-category diseases, or with low-quality to prompt manual checks and prevent misdiagnosis. FMUE provides a trustworthy method for automatic retinal anomalies detection in the real-world clinical open set environment.
Common and Rare Fundus Diseases Identification Using Vision-Language Foundation Model with Knowledge of Over 400 Diseases
Jun 13, 2024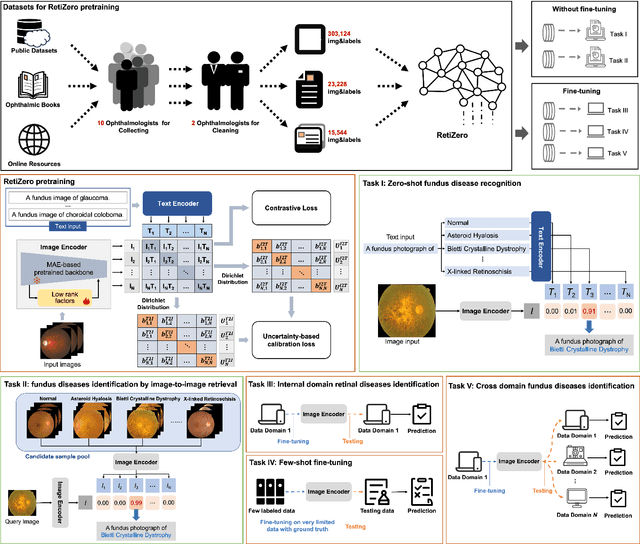
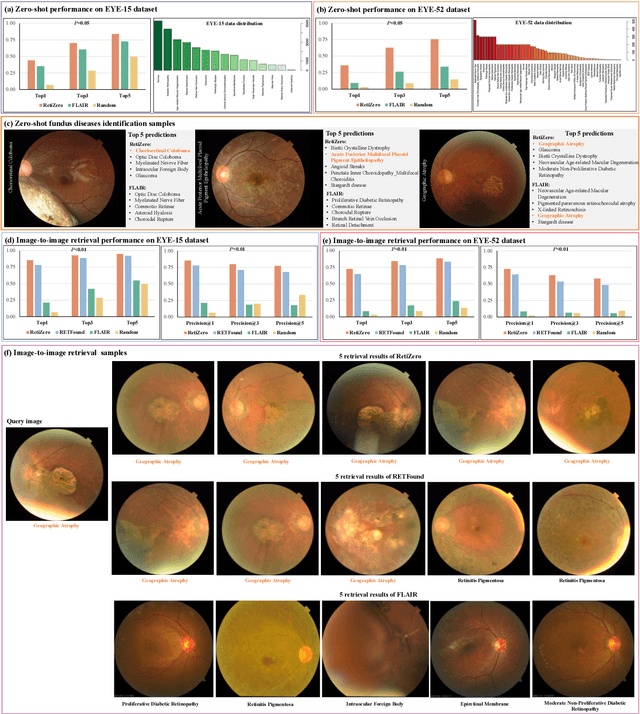
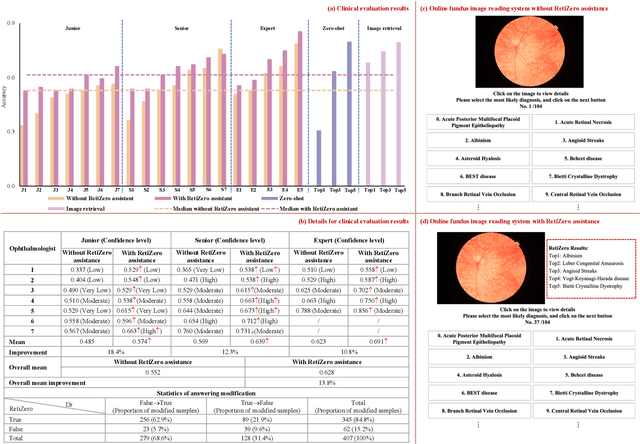
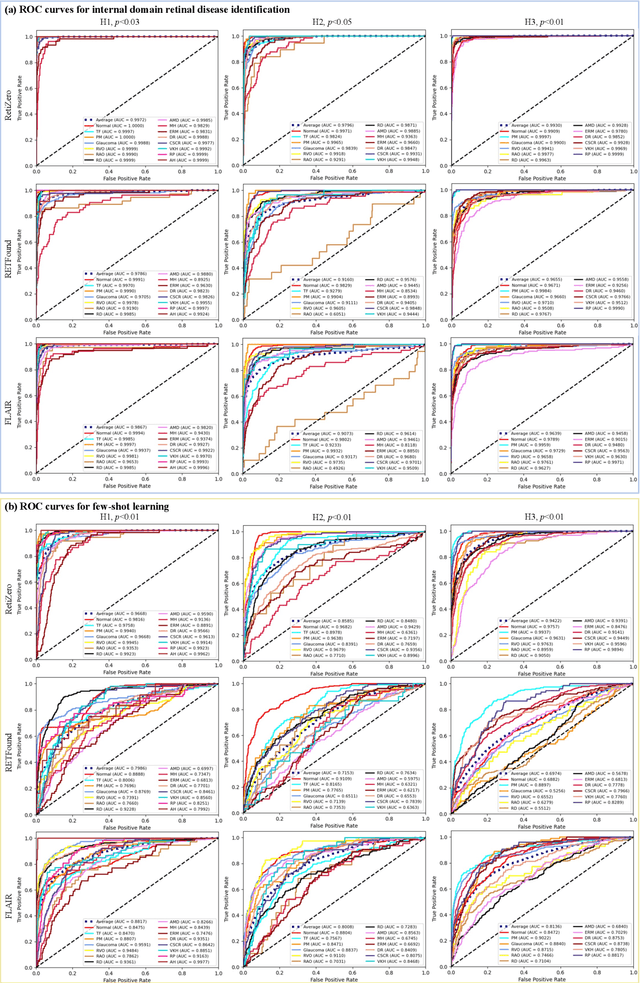
The current retinal artificial intelligence models were trained using data with a limited category of diseases and limited knowledge. In this paper, we present a retinal vision-language foundation model (RetiZero) with knowledge of over 400 fundus diseases. Specifically, we collected 341,896 fundus images paired with text descriptions from 29 publicly available datasets, 180 ophthalmic books, and online resources, encompassing over 400 fundus diseases across multiple countries and ethnicities. RetiZero achieved outstanding performance across various downstream tasks, including zero-shot retinal disease recognition, image-to-image retrieval, internal domain and cross-domain retinal disease classification, and few-shot fine-tuning. Specially, in the zero-shot scenario, RetiZero achieved a Top5 score of 0.8430 and 0.7561 on 15 and 52 fundus diseases respectively. In the image-retrieval task, RetiZero achieved a Top5 score of 0.9500 and 0.8860 on 15 and 52 retinal diseases respectively. Furthermore, clinical evaluations by ophthalmology experts from different countries demonstrate that RetiZero can achieve performance comparable to experienced ophthalmologists using zero-shot and image retrieval methods without requiring model retraining. These capabilities of retinal disease identification strengthen our RetiZero foundation model in clinical implementation.
Confidence-aware multi-modality learning for eye disease screening
May 28, 2024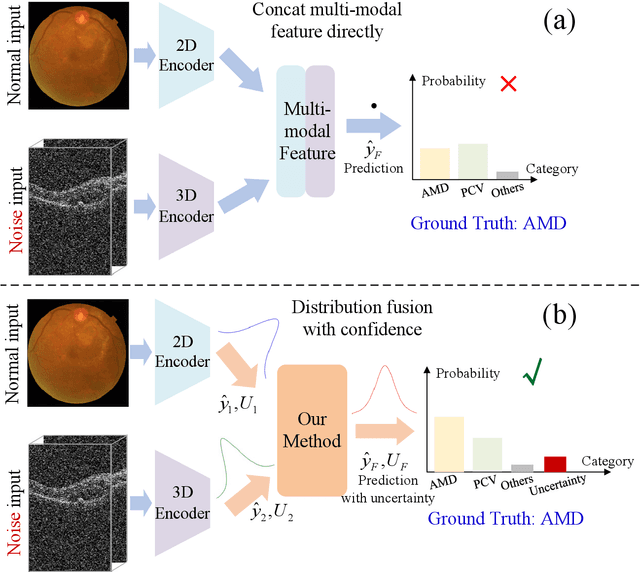
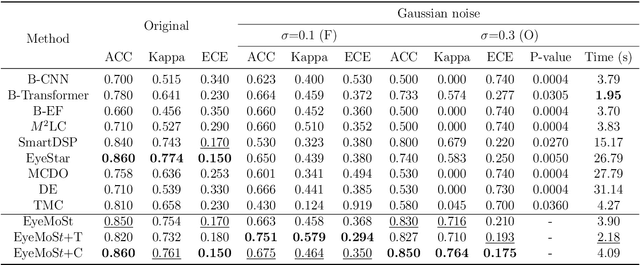
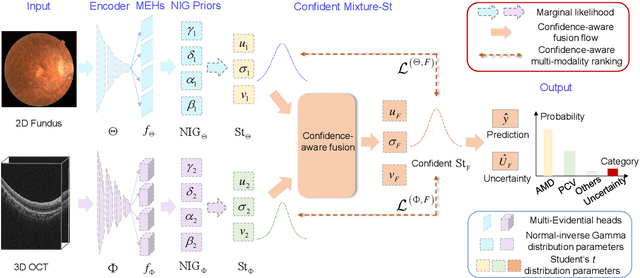
Multi-modal ophthalmic image classification plays a key role in diagnosing eye diseases, as it integrates information from different sources to complement their respective performances. However, recent improvements have mainly focused on accuracy, often neglecting the importance of confidence and robustness in predictions for diverse modalities. In this study, we propose a novel multi-modality evidential fusion pipeline for eye disease screening. It provides a measure of confidence for each modality and elegantly integrates the multi-modality information using a multi-distribution fusion perspective. Specifically, our method first utilizes normal inverse gamma prior distributions over pre-trained models to learn both aleatoric and epistemic uncertainty for uni-modality. Then, the normal inverse gamma distribution is analyzed as the Student's t distribution. Furthermore, within a confidence-aware fusion framework, we propose a mixture of Student's t distributions to effectively integrate different modalities, imparting the model with heavy-tailed properties and enhancing its robustness and reliability. More importantly, the confidence-aware multi-modality ranking regularization term induces the model to more reasonably rank the noisy single-modal and fused-modal confidence, leading to improved reliability and accuracy. Experimental results on both public and internal datasets demonstrate that our model excels in robustness, particularly in challenging scenarios involving Gaussian noise and modality missing conditions. Moreover, our model exhibits strong generalization capabilities to out-of-distribution data, underscoring its potential as a promising solution for multimodal eye disease screening.
Uncertainty-inspired Open Set Learning for Retinal Anomaly Identification
Apr 08, 2023
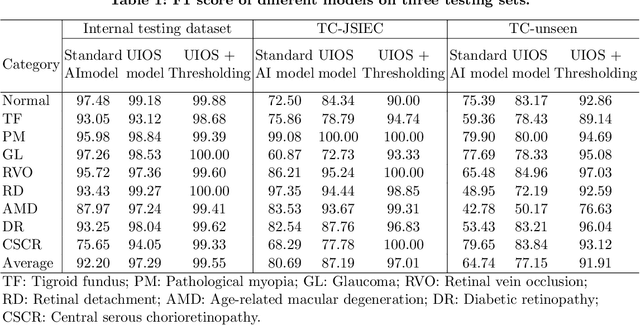


Failure to recognize samples from the classes unseen during training is a major limit of artificial intelligence (AI) in real-world implementation of retinal anomaly classification. To resolve this obstacle, we propose an uncertainty-inspired open-set (UIOS) model which was trained with fundus images of 9 common retinal conditions. Besides the probability of each category, UIOS also calculates an uncertainty score to express its confidence. Our UIOS model with thresholding strategy achieved an F1 score of 99.55%, 97.01% and 91.91% for the internal testing set, external testing set and non-typical testing set, respectively, compared to the F1 score of 92.20%, 80.69% and 64.74% by the standard AI model. Furthermore, UIOS correctly predicted high uncertainty scores, which prompted the need for a manual check, in the datasets of rare retinal diseases, low-quality fundus images, and non-fundus images. This work provides a robust method for real-world screening of retinal anomalies.
Reliable Multimodality Eye Disease Screening via Mixture of Student's t Distributions
Mar 17, 2023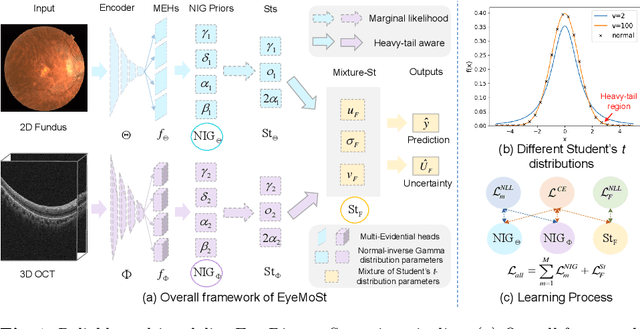
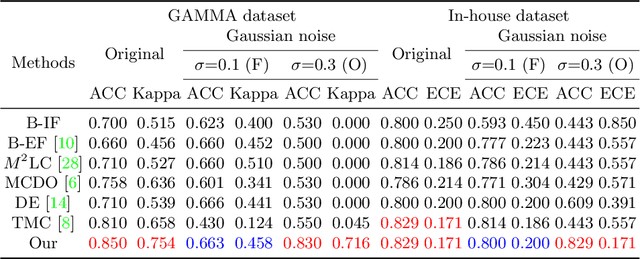
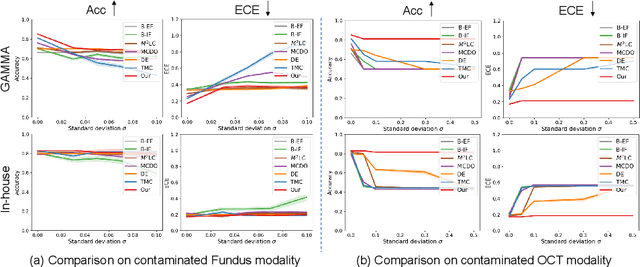

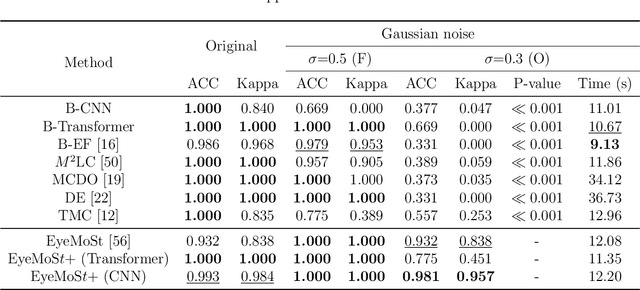
Multimodality eye disease screening is crucial in ophthalmology as it integrates information from diverse sources to complement their respective performances. However, the existing methods are weak in assessing the reliability of each unimodality, and directly fusing an unreliable modality may cause screening errors. To address this issue, we introduce a novel multimodality evidential fusion pipeline for eye disease screening, EyeMoS$t$, which provides a measure of confidence for unimodality and elegantly integrates the multimodality information from a multi-distribution fusion perspective. Specifically, our model estimates both local uncertainty for unimodality and global uncertainty for the fusion modality to produce reliable classification results. More importantly, the proposed mixture of Student's $t$ distributions adaptively integrates different modalities to endow the model with heavy-tailed properties, increasing robustness and reliability. Our experimental findings on both public and in-house datasets show that our model is more reliable than current methods. Additionally, EyeMos$t$ has the potential ability to serve as a data quality discriminator, enabling reliable decision-making for multimodality eye disease screening.
Channel Estimation for BIOS-Assisted Multi-User MIMO Systems: A Heterogeneous Two-timescale Strategy
Feb 16, 2023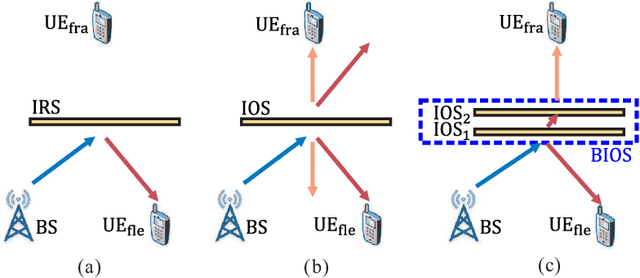
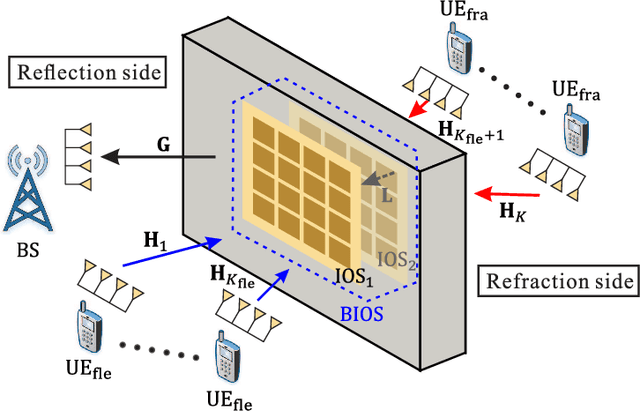
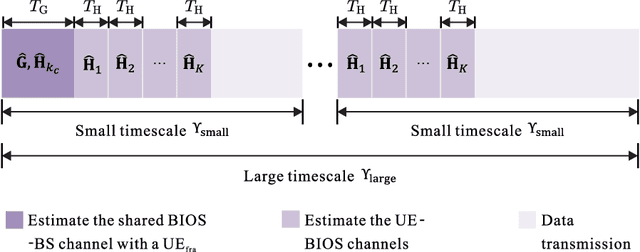

Bilayer intelligent omni-surface (BIOS) has recently attracted increasing attention due to its capability of independent beamforming on both reflection and refraction sides. However, its specific bilayer structure makes the channel estimation problem more challenging than the conventional intelligent reflecting surface (IRS) or intelligent omni-surface (IOS). In this paper, we investigate the channel estimation problem in the BIOS-assisted multi-user multiple-input multiple-output system. We find that in contrast to the IRS or IOS, where the forms of the cascaded channels of all user equipments (UEs) are the same, in the BIOS, those of the UEs on the reflection side are different from those on the refraction side, which is referred to as the heterogeneous channel property. By exploiting it along with the two-timescale and sparsity properties of channels and applying the manifold optimization method, we propose an efficient channel estimation scheme to reduce the training overhead in the BIOS-assisted system. Moreover, we investigate the joint optimization of base station digital beamforming and BIOS passive analog beamforming. Simulation results show that the proposed estimation scheme can significantly reduce the training overhead with competitive estimation quality, and thus keeps the performance advantage of BIOS over IRS and IOS with imperfect channel state information.
Channel Estimation for IRS-Assisted Millimeter-Wave MIMO Systems: Sparsity-Inspired Approaches
Jul 24, 2021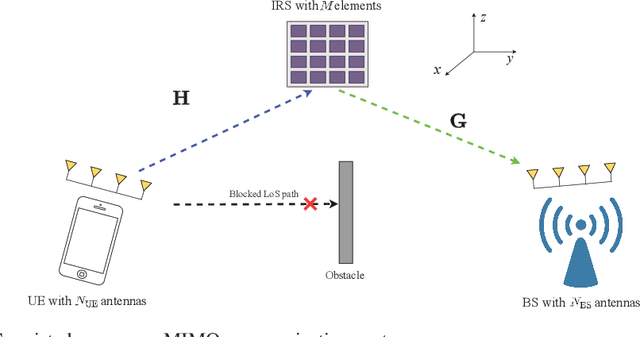
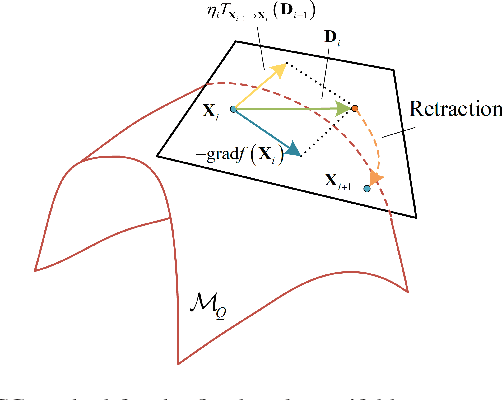
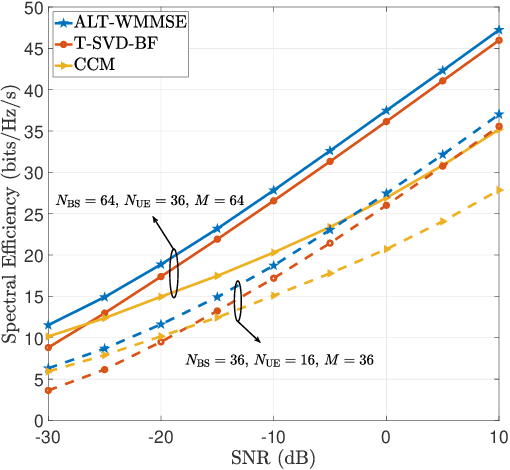
Due to their ability to create favorable line-of-sight (LoS) propagation environments, intelligent reflecting surfaces (IRSs) are regarded as promising enablers for future millimeter-wave (mm-wave) wireless communication. In this paper, we investigate channel estimation for IRS-assisted mm-wave multiple-input multiple-output (MIMO) {\color{black}wireles}s systems. By leveraging the sparsity of mm-wave channels in the angular domain, we formulate the channel estimation problem as an $\ell_1$-norm regularized optimization problem with fixed-rank constraints. To tackle the non-convexity of the formulated problem, an efficient algorithm is proposed by capitalizing on alternating minimization and manifold optimization (MO), which yields a locally optimal solution. To further reduce the computational complexity of the estimation algorithm, we propose a compressive sensing- (CS-) based channel estimation approach. In particular, a three-stage estimation protocol is put forward where the subproblem in each stage can be solved via low-complexity CS methods. Furthermore, based on the acquired channel state information (CSI) of the cascaded channel, we design a passive beamforming algorithm for maximization of the spectral efficiency. Simulation results reveal that the proposed MO-based estimation (MO-EST) and beamforming algorithms significantly outperform two benchmark schemes while the CS-based estimation (CS-EST) algorithm strikes a balance between performance and complexity. In addition, we demonstrate the robustness of the MO-EST algorithm with respect to imperfect knowledge of the sparsity level of the channels, which is crucial for practical implementations.
Neural Logic Machines
Apr 26, 2019
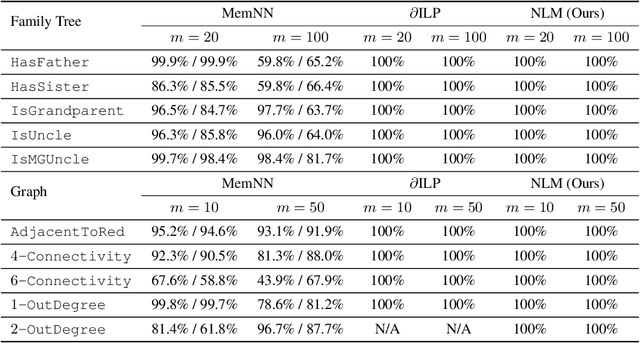
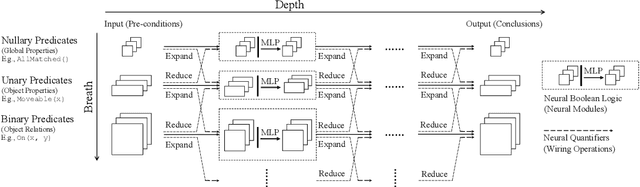
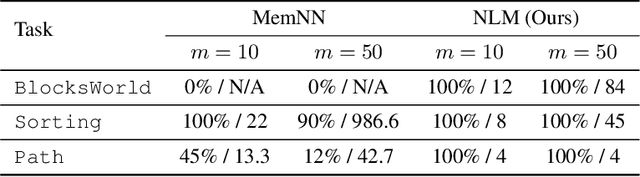
We propose the Neural Logic Machine (NLM), a neural-symbolic architecture for both inductive learning and logic reasoning. NLMs exploit the power of both neural networks---as function approximators, and logic programming---as a symbolic processor for objects with properties, relations, logic connectives, and quantifiers. After being trained on small-scale tasks (such as sorting short arrays), NLMs can recover lifted rules, and generalize to large-scale tasks (such as sorting longer arrays). In our experiments, NLMs achieve perfect generalization in a number of tasks, from relational reasoning tasks on the family tree and general graphs, to decision making tasks including sorting arrays, finding shortest paths, and playing the blocks world. Most of these tasks are hard to accomplish for neural networks or inductive logic programming alone.