 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-Aware Temporal Modeling for Chronic Disease Progression Prediction
Aug 20, 2025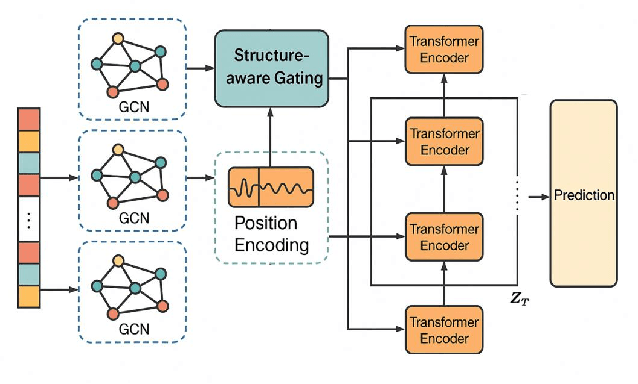
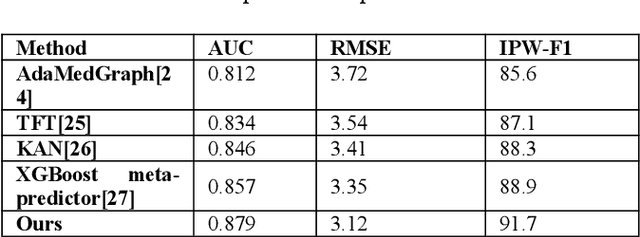
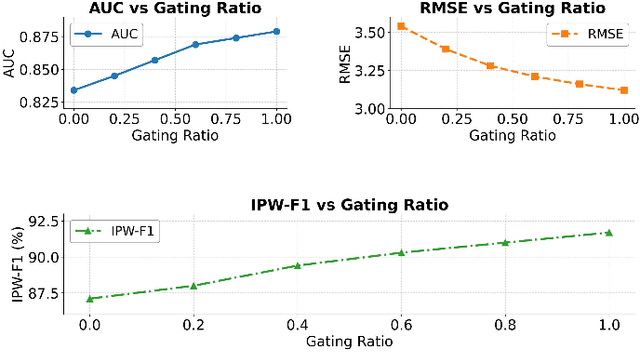
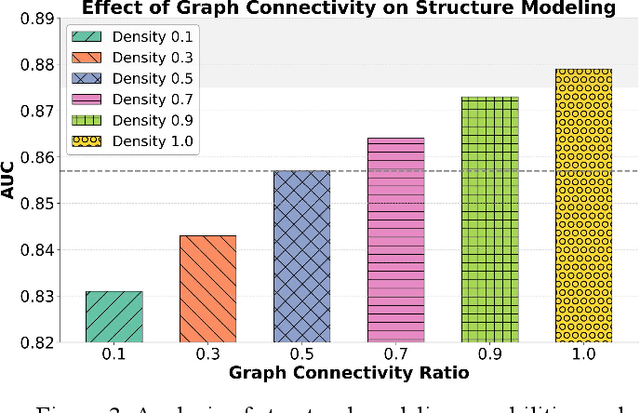
This study addresses the challenges of symptom evolution complexity and insufficient temporal dependency modeling in Parkinson's disease progression prediction. It proposes a unified prediction framework that integrates structural perception and temporal modeling. The method leverages graph neural networks to model the structural relationships among multimodal clinical symptoms and introduces graph-based representations to capture semantic dependencies between symptoms. It also incorporates a Transformer architecture to model dynamic temporal features during disease progression. To fuse structural and temporal information, a structure-aware gating mechanism is designed to dynamically adjust the fusion weights between structural encodings and temporal features, enhancing the model's ability to identify key progression stages. To improve classification accuracy and stability, the framework includes a multi-component modeling pipeline, consisting of a graph construction module, a temporal encoding module, and a prediction output layer. The model is evaluated on real-world longitudinal Parkinson's disease data. The experiments involve comparisons with mainstream models, sensitivity analysis of hyperparameters, and graph connection density control. Results show that the proposed method outperforms existing approaches in AUC, RMSE, and IPW-F1 metrics. It effectively distinguishes progression stages and improves the model's ability to capture personalized symptom trajectories. The overall framework demonstrates strong generalization and structural scalability, providing reliable support for intelligent modeling of chronic progressive diseases such as Parkinson's disease.
Clinical NLP with Attention-Based Deep Learning for Multi-Disease Prediction
Jul 02, 2025This paper addresses the challenges posed by the unstructured nature and high-dimensional semantic complexity of electronic health record texts. A deep learning method based on attention mechanisms is proposed to achieve unified modeling for information extraction and multi-label disease prediction. The study is conducted on the MIMIC-IV dataset. A Transformer-based architecture is used to perform representation learning over clinical text. Multi-layer self-attention mechanisms are employed to capture key medical entities and their contextual relationships. A Sigmoid-based multi-label classifier is then applied to predict multiple disease labels. The model incorporates a context-aware semantic alignment mechanism, enhancing its representational capacity in typical medical scenarios such as label co-occurrence and sparse information. To comprehensively evaluate model performance, a series of experiments were conducted, including baseline comparisons, hyperparameter sensitivity analysis, data perturbation studies, and noise injection tests. Results demonstrate that the proposed method consistently outperforms representative existing approaches across multiple performance metrics. The model maintains strong generalization under varying data scales, interference levels, and model depth configurations. The framework developed in this study offers an efficient algorithmic foundation for processing real-world clinical texts and presents practical significance for multi-label medical text modeling tasks.
YOLOv11-RGBT: Towards a Comprehensive Single-Stage Multispectral Object Detection Framework
Jun 18, 2025Multispectral object detection, which integrates information from multiple bands, can enhance detection accuracy and environmental adaptability, holding great application potential across various fields. Although existing methods have made progress in cross-modal interaction, low-light conditions, and model lightweight, there are still challenges like the lack of a unified single-stage framework, difficulty in balancing performance and fusion strategy, and unreasonable modality weight allocation. To address these, based on the YOLOv11 framework, we present YOLOv11-RGBT, a new comprehensive multimodal object detection framework. We designed six multispectral fusion modes and successfully applied them to models from YOLOv3 to YOLOv12 and RT-DETR. After reevaluating the importance of the two modalities, we proposed a P3 mid-fusion strategy and multispectral controllable fine-tuning (MCF) strategy for multispectral models. These improvements optimize feature fusion, reduce redundancy and mismatches, and boost overall model performance. Experiments show our framework excels on three major open-source multispectral object detection datasets, like LLVIP and FLIR. Particularly, the multispectral controllable fine-tuning strategy significantly enhanced model adaptability and robustness. On the FLIR dataset, it consistently improved YOLOv11 models' mAP by 3.41%-5.65%, reaching a maximum of 47.61%, verifying the framework and strategies' effectiveness. The code is available at: https://github.com/wandahangFY/YOLOv11-RGBT.
SeqPO-SiMT: Sequential Policy Optimization for Simultaneous Machine Translation
May 27, 2025



We present Sequential Policy Optimization for Simultaneous Machine Translation (SeqPO-SiMT), a new policy optimization framework that defines the simultaneous machine translation (SiMT) task as a sequential decision making problem, incorporating a tailored reward to enhance translation quality while reducing latency. In contrast to popular Reinforcement Learning from Human Feedback (RLHF) methods, such as PPO and DPO, which are typically applied in single-step tasks, SeqPO-SiMT effectively tackles the multi-step SiMT task. This intuitive framework allows the SiMT LLMs to simulate and refine the SiMT process using a tailored reward. We conduct experiments on six datasets from diverse domains for En to Zh and Zh to En SiMT tasks, demonstrating that SeqPO-SiMT consistently achieves significantly higher translation quality with lower latency. In particular, SeqPO-SiMT outperforms the supervised fine-tuning (SFT) model by 1.13 points in COMET, while reducing the Average Lagging by 6.17 in the NEWSTEST2021 En to Zh dataset. While SiMT operates with far less context than offline translation, the SiMT results of SeqPO-SiMT on 7B LLM surprisingly rival the offline translation of high-performing LLMs, including Qwen-2.5-7B-Instruct and LLaMA-3-8B-Instruct.
A Clinician-Friendly Platform for Ophthalmic Image Analysis Without Technical Barriers
Apr 22, 2025Artificial intelligence (AI) shows remarkable potential in medical imaging diagnostics, but current models typically require retraining when deployed across different clinical centers, limiting their widespread adoption. We introduce GlobeReady, a clinician-friendly AI platform that enables ocular disease diagnosis without retraining/fine-tuning or technical expertise. GlobeReady achieves high accuracy across imaging modalities: 93.9-98.5% for an 11-category fundus photo dataset and 87.2-92.7% for a 15-category OCT dataset. Through training-free local feature augmentation, it addresses domain shifts across centers and populations, reaching an average accuracy of 88.9% across five centers in China, 86.3% in Vietnam, and 90.2% in the UK. The built-in confidence-quantifiable diagnostic approach further boosted accuracy to 94.9-99.4% (fundus) and 88.2-96.2% (OCT), while identifying out-of-distribution cases at 86.3% (49 CFP categories) and 90.6% (13 OCT categories). Clinicians from multiple countries rated GlobeReady highly (average 4.6 out of 5) for its usability and clinical relevance. These results demonstrate GlobeReady's robust, scalable diagnostic capability and potential to support ophthalmic care without technical barriers.
Adaptive Transformer Attention and Multi-Scale Fusion for Spine 3D Segmentation
Mar 17, 2025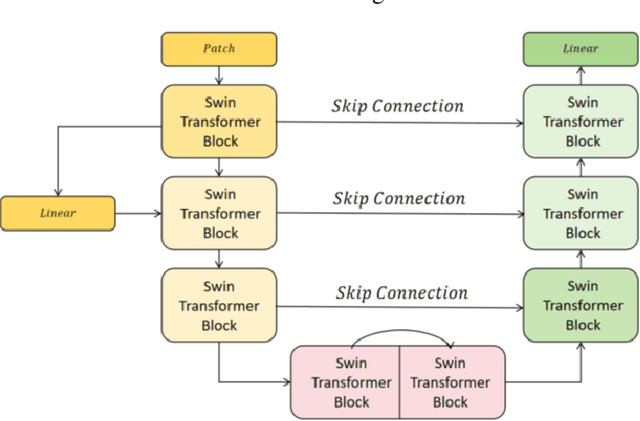
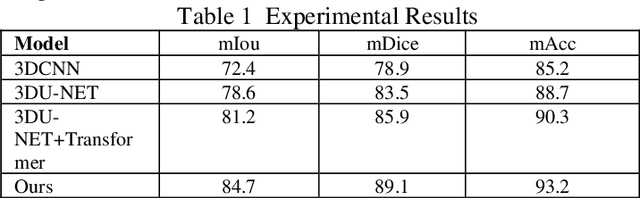
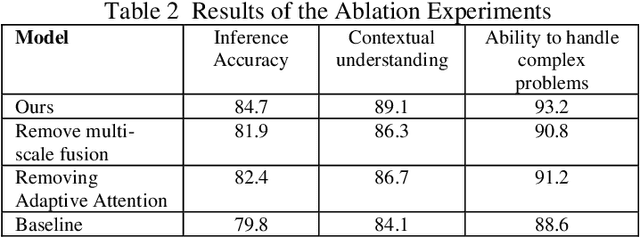
This study proposes a 3D semantic segmentation method for the spine based on the improved SwinUNETR to improve segmentation accuracy and robustness. Aiming at the complex anatomical structure of spinal images, this paper introduces a multi-scale fusion mechanism to enhance the feature extraction capability by using information of different scales, thereby improving the recognition accuracy of the model for the target area. In addition, the introduction of the adaptive attention mechanism enables the model to dynamically adjust the attention to the key area, thereby optimizing the boundary segmentation effect. The experimental results show that compared with 3D CNN, 3D U-Net, and 3D U-Net + Transformer, the model of this study has achieved significant improvements in mIoU, mDice, and mAcc indicators, and has better segmentation performance. The ablation experiment further verifies the effectiveness of the proposed improved method, proving that multi-scale fusion and adaptive attention mechanism have a positive effect on the segmentation task. Through the visualization analysis of the inference results, the model can better restore the real anatomical structure of the spinal image. Future research can further optimize the Transformer structure and expand the data scale to improve the generalization ability of the model. This study provides an efficient solution for the task of medical image segmentation, which is of great significance to intelligent medical image analysis.
A Hybrid CNN-Transformer Model for Heart Disease Prediction Using Life History Data
Mar 03, 2025This study proposed a hybrid model of a convolutional neural network (CNN) and a Transformer to predict and diagnose heart disease. Based on CNN's strength in detecting local features and the Transformer's high capacity in sensing global relations, the model is able to successfully detect risk factors of heart disease from high-dimensional life history data. Experimental results show that the proposed model outperforms traditional benchmark models like support vector machine (SVM), convolutional neural network (CNN), and long short-term memory network (LSTM) on several measures like accuracy, precision, and recall. This demonstrates its strong ability to deal with multi-dimensional and unstructured data. In order to verify the effectiveness of the model, experiments removing certain parts were carried out, and the results of the experiments showed that it is important to use both CNN and Transformer modules in enhancing the model. This paper also discusses the incorporation of additional features and approaches in future studies to enhance the model's performance and enable it to operate effectively in diverse conditions. This study presents novel insights and methods for predicting heart disease using machine learning, with numerous potential applications especially in personalized medicine and health management.
Object Detection for Medical Image Analysis: Insights from the RT-DETR Model
Jan 27, 2025



Deep learning has emerged as a transformative approach for solving complex pattern recognition and object detection challenges. This paper focuses on the application of a novel detection framework based on the RT-DETR model for analyzing intricate image data, particularly in areas such as diabetic retinopathy detection. Diabetic retinopathy, a leading cause of vision loss globally, requires accurate and efficient image analysis to identify early-stage lesions. The proposed RT-DETR model, built on a Transformer-based architecture, excels at processing high-dimensional and complex visual data with enhanced robustness and accuracy. Comparative evaluations with models such as YOLOv5, YOLOv8, SSD, and DETR demonstrate that RT-DETR achieves superior performance across precision, recall, mAP50, and mAP50-95 metrics, particularly in detecting small-scale objects and densely packed targets. This study underscores the potential of Transformer-based models like RT-DETR for advancing object detection tasks, offering promising applications in medical imaging and beyond.
Enhancing Uplift Modeling in Multi-Treatment Marketing Campaigns: Leveraging Score Ranking and Calibration Techniques
Aug 27, 2024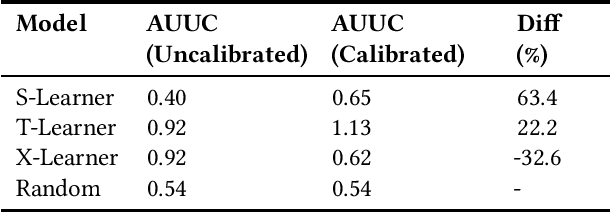
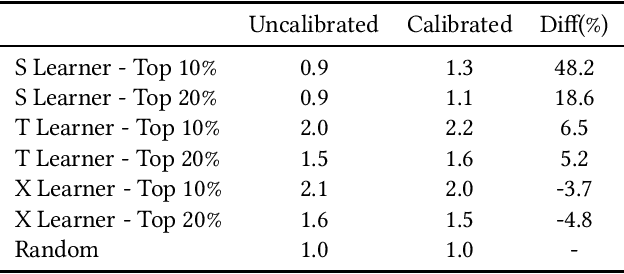


Uplift modeling is essential for optimizing marketing strategies by selecting individuals likely to respond positively to specific marketing campaigns. This importance escalates in multi-treatment marketing campaigns, where diverse treatment is available and we may want to assign the customers to treatment that can make the most impact. While there are existing approaches with convenient frameworks like Causalml, there are potential spaces to enhance the effect of uplift modeling in multi treatment cases. This paper introduces a novel approach to uplift modeling in multi-treatment campaigns, leveraging score ranking and calibration techniques to improve overall performance of the marketing campaign. We review existing uplift models, including Meta Learner frameworks (S, T, X), and their application in real-world scenarios. Additionally, we delve into insights from multi-treatment studies to highlight the complexities and potential advancements in the field. Our methodology incorporates Meta-Learner calibration and a scoring rank-based offer selection strategy. Extensive experiment results with real-world datasets demonstrate the practical benefits and superior performance of our approach. The findings underscore the critical role of integrating score ranking and calibration techniques in refining the performance and reliability of uplift predictions, thereby advancing predictive modeling in marketing analytics and providing actionable insights for practitioners seeking to optimize their campaign strategies.
Research on Early Warning Model of Cardiovascular Disease Based on Computer Deep Learning
Jun 13, 2024This project intends to study a cardiovascular disease risk early warning model based on one-dimensional convolutional neural networks. First, the missing values of 13 physiological and symptom indicators such as patient age, blood glucose, cholesterol, and chest pain were filled and Z-score was standardized. The convolutional neural network is converted into a 2D matrix, the convolution function of 1,3, and 5 is used for the first-order convolution operation, and the Max Pooling algorithm is adopted for dimension reduction. Set the learning rate and output rate. It is optimized by the Adam algorithm. The result of classification is output by a soft classifier. This study was conducted based on Statlog in the UCI database and heart disease database respectively. The empirical data indicate that the forecasting precision of this technique has been enhanced by 11.2%, relative to conventional approaches, while there is a significant improvement in the logarithmic curve fitting. The efficacy and applicability of the novel approach are corroborated through the examination employing a one-dimensional convolutional neural network.