 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoAR: Concept Injection into Autoregressive Models for Personalized Text-to-Image Generation
Aug 10, 2025



The unified autoregressive (AR) model excels at multimodal understanding and generation, but its potential for customized image generation remains underexplored. Existing customized generation methods rely on full fine-tuning or adapters, making them costly and prone to overfitting or catastrophic forgetting. In this paper, we propose \textbf{CoAR}, a novel framework for injecting subject concepts into the unified AR models while keeping all pre-trained parameters completely frozen. CoAR learns effective, specific subject representations with only a minimal number of parameters using a Layerwise Multimodal Context Learning strategy. To address overfitting and language drift, we further introduce regularization that preserves the pre-trained distribution and anchors context tokens to improve subject fidelity and re-contextualization. Additionally, CoAR supports training-free subject customization in a user-provided style. Experiments demonstrate that CoAR achieves superior performance on both subject-driven personalization and style personalization, while delivering significant gains in computational and memory efficiency. Notably, CoAR tunes less than \textbf{0.05\%} of the parameters while achieving competitive performance compared to recent Proxy-Tuning. Code: https://github.com/KZF-kzf/CoAR
DyST-XL: Dynamic Layout Planning and Content Control for Compositional Text-to-Video Generation
Apr 21, 2025



Compositional text-to-video generation, which requires synthesizing dynamic scenes with multiple interacting entities and precise spatial-temporal relationships, remains a critical challenge for diffusion-based models. Existing methods struggle with layout discontinuity, entity identity drift, and implausible interaction dynamics due to unconstrained cross-attention mechanisms and inadequate physics-aware reasoning. To address these limitations, we propose DyST-XL, a \textbf{training-free} framework that enhances off-the-shelf text-to-video models (e.g., CogVideoX-5B) through frame-aware control. DyST-XL integrates three key innovations: (1) A Dynamic Layout Planner that leverages large language models (LLMs) to parse input prompts into entity-attribute graphs and generates physics-aware keyframe layouts, with intermediate frames interpolated via trajectory optimization; (2) A Dual-Prompt Controlled Attention Mechanism that enforces localized text-video alignment through frame-aware attention masking, achieving the precise control over individual entities; and (3) An Entity-Consistency Constraint strategy that propagates first-frame feature embeddings to subsequent frames during denoising, preserving object identity without manual annotation. Experiments demonstrate that DyST-XL excels in compositional text-to-video generation, significantly improving performance on complex prompts and bridging a crucial gap in training-free video synthesis.
Privacy-Preserving Hybrid Ensemble Model for Network Anomaly Detection: Balancing Security and Data Protection
Feb 13, 2025



Privacy-preserving network anomaly detection has become an essential area of research due to growing concerns over the protection of sensitive data. Traditional anomaly de- tection models often prioritize accuracy while neglecting the critical aspect of privacy. In this work, we propose a hybrid ensemble model that incorporates privacy-preserving techniques to address both detection accuracy and data protection. Our model combines the strengths of several machine learning algo- rithms, including K-Nearest Neighbors (KNN), Support Vector Machines (SVM), XGBoost, and Artificial Neural Networks (ANN), to create a robust system capable of identifying network anomalies while ensuring privacy. The proposed approach in- tegrates advanced preprocessing techniques that enhance data quality and address the challenges of small sample sizes and imbalanced datasets. By embedding privacy measures into the model design, our solution offers a significant advancement over existing methods, ensuring both enhanced detection performance and strong privacy safeguards.
Object Detection for Medical Image Analysis: Insights from the RT-DETR Model
Jan 27, 2025



Deep learning has emerged as a transformative approach for solving complex pattern recognition and object detection challenges. This paper focuses on the application of a novel detection framework based on the RT-DETR model for analyzing intricate image data, particularly in areas such as diabetic retinopathy detection. Diabetic retinopathy, a leading cause of vision loss globally, requires accurate and efficient image analysis to identify early-stage lesions. The proposed RT-DETR model, built on a Transformer-based architecture, excels at processing high-dimensional and complex visual data with enhanced robustness and accuracy. Comparative evaluations with models such as YOLOv5, YOLOv8, SSD, and DETR demonstrate that RT-DETR achieves superior performance across precision, recall, mAP50, and mAP50-95 metrics, particularly in detecting small-scale objects and densely packed targets. This study underscores the potential of Transformer-based models like RT-DETR for advancing object detection tasks, offering promising applications in medical imaging and beyond.
Deep Learning in Image Classification: Evaluating VGG19's Performance on Complex Visual Data
Dec 29, 2024



This study aims to explore the automatic classification method of pneumonia X-ray images based on VGG19 deep convolutional neural network, and evaluate its application effect in pneumonia diagnosis by comparing with classic models such as SVM, XGBoost, MLP, and ResNet50. The experimental results show that VGG19 performs well in multiple indicators such as accuracy (92%), AUC (0.95), F1 score (0.90) and recall rate (0.87), which is better than other comparison models, especially in image feature extraction and classification accuracy. Although ResNet50 performs well in some indicators, it is slightly inferior to VGG19 in recall rate and F1 score. Traditional machine learning models SVM and XGBoost are obviously limited in image classification tasks, especially in complex medical image analysis tasks, and their performance is relatively mediocre. The research results show that deep learning, especially convolutional neural networks, have significant advantages in medical image classification tasks, especially in pneumonia X-ray image analysis, and can provide efficient and accurate automatic diagnosis support. This research provides strong technical support for the early detection of pneumonia and the development of automated diagnosis systems and also lays the foundation for further promoting the application and development of automated medical image processing technology.
Deep Learning with HM-VGG: AI Strategies for Multi-modal Image Analysis
Oct 31, 2024



This study introduces the Hybrid Multi-modal VGG (HM-VGG) model, a cutting-edge deep learning approach for the early diagnosis of glaucoma. The HM-VGG model utilizes an attention mechanism to process Visual Field (VF) data, enabling the extraction of key features that are vital for identifying early signs of glaucoma. Despite the common reliance on large annotated datasets, the HM-VGG model excels in scenarios with limited data, achieving remarkable results with small sample sizes. The model's performance is underscored by its high metrics in Precision, Accuracy, and F1-Score, indicating its potential for real-world application in glaucoma detection. The paper also discusses the challenges associated with ophthalmic image analysis, particularly the difficulty of obtaining large volumes of annotated data. It highlights the importance of moving beyond single-modality data, such as VF or Optical Coherence Tomography (OCT) images alone, to a multimodal approach that can provide a richer, more comprehensive dataset. This integration of different data types is shown to significantly enhance diagnostic accuracy. The HM- VGG model offers a promising tool for doctors, streamlining the diagnostic process and improving patient outcomes. Furthermore, its applicability extends to telemedicine and mobile healthcare, making diagnostic services more accessible. The research presented in this paper is a significant step forward in the field of medical image processing and has profound implications for clinical ophthalmology.
Deep Learning for Medical Text Processing: BERT Model Fine-Tuning and Comparative Study
Oct 28, 2024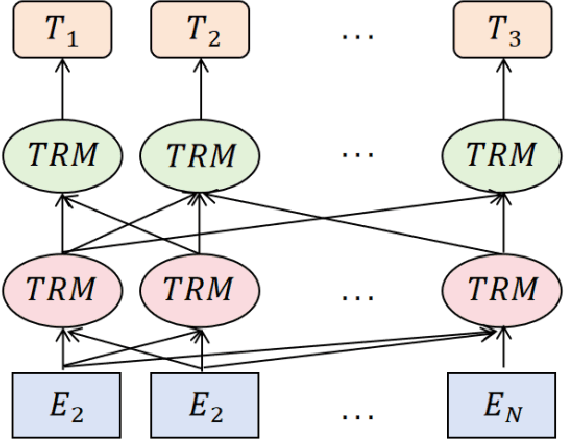
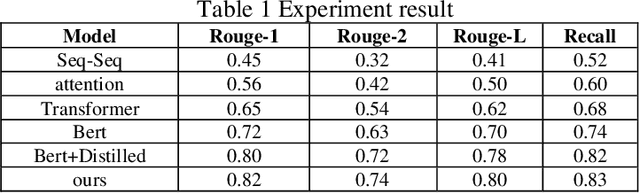
This paper proposes a medical literature summary generation method based on the BERT model to address the challenges brought by the current explosion of medical information. By fine-tuning and optimizing the BERT model, we develop an efficient summary generation system that can quickly extract key information from medical literature and generate coherent, accurate summaries. In the experiment, we compared various models, including Seq-Seq, Attention, Transformer, and BERT, and demonstrated that the improved BERT model offers significant advantages in the Rouge and Recall metrics. Furthermore, the results of this study highlight the potential of knowledge distillation techniques to further enhance model performance. The system has demonstrated strong versatility and efficiency in practical applications, offering a reliable tool for the rapid screening and analysis of medical literature.
Hybrid Mask Generation for Infrared Small Target Detection with Single-Point Supervision
Sep 06, 2024



Single-frame infrared small target (SIRST) detection poses a significant challenge due to the requirement to discern minute targets amidst complex infrared background clutter. Recently, deep learning approaches have shown promising results in this domain. However, these methods heavily rely on extensive manual annotations, which are particularly cumbersome and resource-intensive for infrared small targets owing to their minute sizes. To address this limitation, we introduce a Hybrid Mask Generation (HMG) approach that recovers high-quality masks for each target from only a single-point label for network training. Specifically, our HMG approach consists of a handcrafted Points-to-Mask Generation strategy coupled with a pseudo mask updating strategy to recover and refine pseudo masks from point labels. The Points-to-Mask Generation strategy divides two distinct stages: Points-to-Box conversion, where individual point labels are transformed into bounding boxes, and subsequently, Box-to-Mask prediction, where these bounding boxes are elaborated into precise masks. The mask updating strategy integrates the complementary strengths of handcrafted and deep-learning algorithms to iteratively refine the initial pseudo masks. Experimental results across three datasets demonstrate that our method outperforms the existing methods for infrared small target detection with single-point supervision.
Integrating Medical Imaging and Clinical Reports Using Multimodal Deep Learning for Advanced Disease Analysis
May 23, 2024

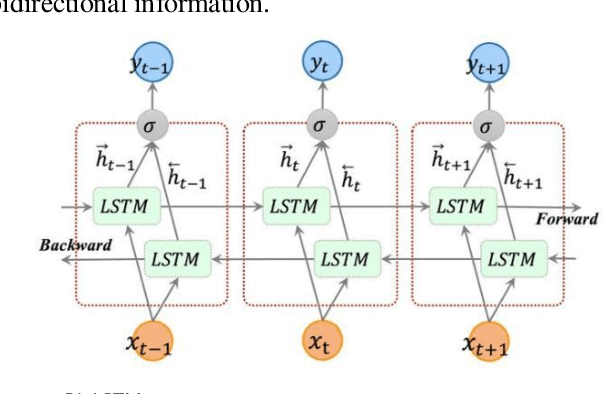

In this paper, an innovative multi-modal deep learning model is proposed to deeply integrate heterogeneous information from medical images and clinical reports. First, for medical images, convolutional neural networks were used to extract high-dimensional features and capture key visual information such as focal details, texture and spatial distribution. Secondly, for clinical report text, a two-way long and short-term memory network combined with an attention mechanism is used for deep semantic understanding, and key statements related to the disease are accurately captured. The two features interact and integrate effectively through the designed multi-modal fusion layer to realize the joint representation learning of image and text. In the empirical study, we selected a large medical image database covering a variety of diseases, combined with corresponding clinical reports for model training and validation. The proposed multimodal deep learning model demonstrated substantial superiority in the realms of disease classification, lesion localization, and clinical description generation, as evidenced by the experimental results.
SYNC-CLIP: Synthetic Data Make CLIP Generalize Better in Data-Limited Scenarios
Dec 06, 2023Prompt learning is a powerful technique for transferring Vision-Language Models (VLMs) such as CLIP to downstream tasks. However, the prompt-based methods that are fine-tuned solely with base classes may struggle to generalize to novel classes in open-vocabulary scenarios, especially when data are limited. To address this issue, we propose an innovative approach called SYNC-CLIP that leverages SYNthetiC data for enhancing the generalization capability of CLIP. Based on the observation of the distribution shift between the real and synthetic samples, we treat real and synthetic samples as distinct domains and propose to optimize separate domain prompts to capture domain-specific information, along with the shared visual prompts to preserve the semantic consistency between two domains. By aligning the cross-domain features, the synthetic data from novel classes can provide implicit guidance to rebalance the decision boundaries. Experimental results on three model generalization tasks demonstrate that our method performs very competitively across various benchmarks. Notably, SYNC-CLIP outperforms the state-of-the-art competitor PromptSRC by an average improvement of 3.0% on novel classes across 11 datasets in open-vocabulary scenarios.