 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning with HM-VGG: AI Strategies for Multi-modal Image Analysis
Oct 31, 2024



This study introduces the Hybrid Multi-modal VGG (HM-VGG) model, a cutting-edge deep learning approach for the early diagnosis of glaucoma. The HM-VGG model utilizes an attention mechanism to process Visual Field (VF) data, enabling the extraction of key features that are vital for identifying early signs of glaucoma. Despite the common reliance on large annotated datasets, the HM-VGG model excels in scenarios with limited data, achieving remarkable results with small sample sizes. The model's performance is underscored by its high metrics in Precision, Accuracy, and F1-Score, indicating its potential for real-world application in glaucoma detection. The paper also discusses the challenges associated with ophthalmic image analysis, particularly the difficulty of obtaining large volumes of annotated data. It highlights the importance of moving beyond single-modality data, such as VF or Optical Coherence Tomography (OCT) images alone, to a multimodal approach that can provide a richer, more comprehensive dataset. This integration of different data types is shown to significantly enhance diagnostic accuracy. The HM- VGG model offers a promising tool for doctors, streamlining the diagnostic process and improving patient outcomes. Furthermore, its applicability extends to telemedicine and mobile healthcare, making diagnostic services more accessible. The research presented in this paper is a significant step forward in the field of medical image processing and has profound implications for clinical ophthalmology.
Deep Learning for Medical Text Processing: BERT Model Fine-Tuning and Comparative Study
Oct 28, 2024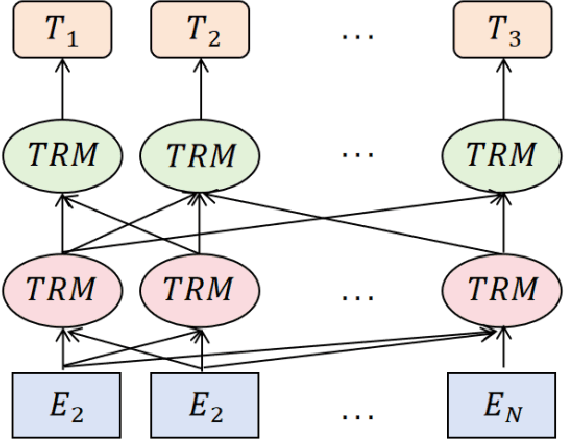
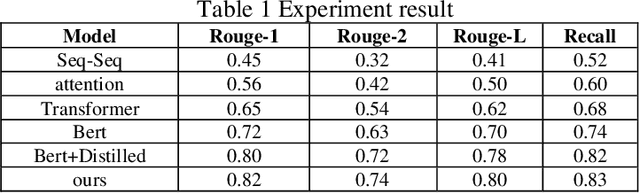
This paper proposes a medical literature summary generation method based on the BERT model to address the challenges brought by the current explosion of medical information. By fine-tuning and optimizing the BERT model, we develop an efficient summary generation system that can quickly extract key information from medical literature and generate coherent, accurate summaries. In the experiment, we compared various models, including Seq-Seq, Attention, Transformer, and BERT, and demonstrated that the improved BERT model offers significant advantages in the Rouge and Recall metrics. Furthermore, the results of this study highlight the potential of knowledge distillation techniques to further enhance model performance. The system has demonstrated strong versatility and efficiency in practical applications, offering a reliable tool for the rapid screening and analysis of medical literature.
A comparative study of generative adversarial networks for image recognition algorithms based on deep learning and traditional methods
Aug 07, 2024In this paper, an image recognition algorithm based on the combination of deep learning and generative adversarial network (GAN) is studied, and compared with traditional image recognition methods. The purpose of this study is to evaluate the advantages and application prospects of deep learning technology, especially GAN, in the field of image recognition. Firstly, this paper reviews the basic principles and techniques of traditional image recognition methods, including the classical algorithms based on feature extraction such as SIFT, HOG and their combination with support vector machine (SVM), random forest, and other classifiers. Then, the working principle, network structure, and unique advantages of GAN in image generation and recognition are introduced. In order to verify the effectiveness of GAN in image recognition, a series of experiments are designed and carried out using multiple public image data sets for training and testing. The experimental results show that compared with traditional methods, GAN has excellent performance in processing complex images, recognition accuracy, and anti-noise ability. Specifically, Gans are better able to capture high-dimensional features and details of images, significantly improving recognition performance. In addition, Gans shows unique advantages in dealing with image noise, partial missing information, and generating high-quality images.
Advanced Multimodal Deep Learning Architecture for Image-Text Matching
Jun 13, 2024Image-text matching is a key multimodal task that aims to model the semantic association between images and text as a matching relationship. With the advent of the multimedia information age, image, and text data show explosive growth, and how to accurately realize the efficient and accurate semantic correspondence between them has become the core issue of common concern in academia and industry. In this study, we delve into the limitations of current multimodal deep learning models in processing image-text pairing tasks. Therefore, we innovatively design an advanced multimodal deep learning architecture, which combines the high-level abstract representation ability of deep neural networks for visual information with the advantages of natural language processing models for text semantic understanding. By introducing a novel cross-modal attention mechanism and hierarchical feature fusion strategy, the model achieves deep fusion and two-way interaction between image and text feature space. In addition, we also optimize the training objectives and loss functions to ensure that the model can better map the potential association structure between images and text during the learning process. Experiments show that compared with existing image-text matching models, the optimized new model has significantly improved performance on a series of benchmark data sets. In addition, the new model also shows excellent generalization and robustness on large and diverse open scenario datasets and can maintain high matching performance even in the face of previously unseen complex situations.