 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocomotion Beyond Feet
Jan 07, 2026Most locomotion methods for humanoid robots focus on leg-based gaits, yet natural bipeds frequently rely on hands, knees, and elbows to establish additional contacts for stability and support in complex environments. This paper introduces Locomotion Beyond Feet, a comprehensive system for whole-body humanoid locomotion across extremely challenging terrains, including low-clearance spaces under chairs, knee-high walls, knee-high platforms, and steep ascending and descending stairs. Our approach addresses two key challenges: contact-rich motion planning and generalization across diverse terrains. To this end, we combine physics-grounded keyframe animation with reinforcement learning. Keyframes encode human knowledge of motor skills, are embodiment-specific, and can be readily validated in simulation or on hardware, while reinforcement learning transforms these references into robust, physically accurate motions. We further employ a hierarchical framework consisting of terrain-specific motion-tracking policies, failure recovery mechanisms, and a vision-based skill planner. Real-world experiments demonstrate that Locomotion Beyond Feet achieves robust whole-body locomotion and generalizes across obstacle sizes, obstacle instances, and terrain sequences.
Structure-Aware Temporal Modeling for Chronic Disease Progression Prediction
Aug 20, 2025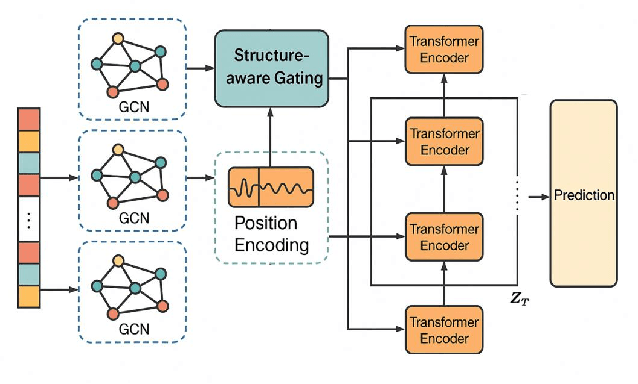
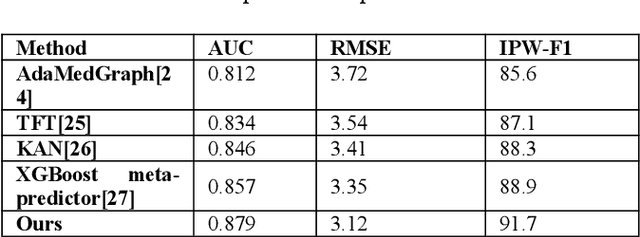
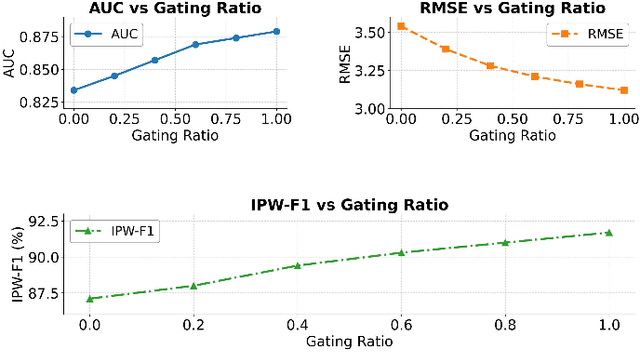
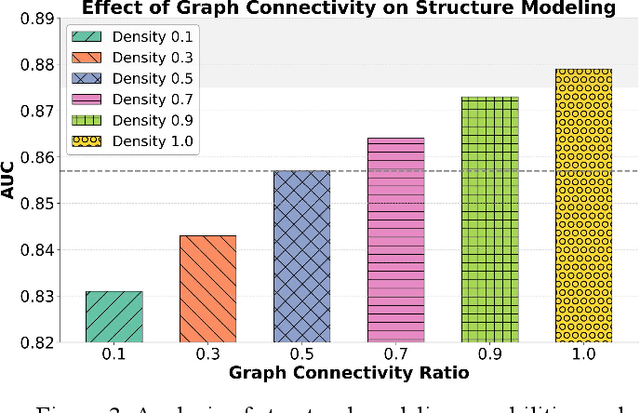
This study addresses the challenges of symptom evolution complexity and insufficient temporal dependency modeling in Parkinson's disease progression prediction. It proposes a unified prediction framework that integrates structural perception and temporal modeling. The method leverages graph neural networks to model the structural relationships among multimodal clinical symptoms and introduces graph-based representations to capture semantic dependencies between symptoms. It also incorporates a Transformer architecture to model dynamic temporal features during disease progression. To fuse structural and temporal information, a structure-aware gating mechanism is designed to dynamically adjust the fusion weights between structural encodings and temporal features, enhancing the model's ability to identify key progression stages. To improve classification accuracy and stability, the framework includes a multi-component modeling pipeline, consisting of a graph construction module, a temporal encoding module, and a prediction output layer. The model is evaluated on real-world longitudinal Parkinson's disease data. The experiments involve comparisons with mainstream models, sensitivity analysis of hyperparameters, and graph connection density control. Results show that the proposed method outperforms existing approaches in AUC, RMSE, and IPW-F1 metrics. It effectively distinguishes progression stages and improves the model's ability to capture personalized symptom trajectories. The overall framework demonstrates strong generalization and structural scalability, providing reliable support for intelligent modeling of chronic progressive diseases such as Parkinson's disease.
A Deep Learning Framework for Boundary-Aware Semantic Segmentation
Mar 28, 2025As a fundamental task in computer vision, semantic segmentation is widely applied in fields such as autonomous driving, remote sensing image analysis, and medical image processing. In recent years, Transformer-based segmentation methods have demonstrated strong performance in global feature modeling. However, they still struggle with blurred target boundaries and insufficient recognition of small targets. To address these issues, this study proposes a Mask2Former-based semantic segmentation algorithm incorporating a boundary enhancement feature bridging module (BEFBM). The goal is to improve target boundary accuracy and segmentation consistency. Built upon the Mask2Former framework, this method constructs a boundary-aware feature map and introduces a feature bridging mechanism. This enables effective cross-scale feature fusion, enhancing the model's ability to focus on target boundaries. Experiments on the Cityscapes dataset demonstrate that, compared to mainstream segmentation methods, the proposed approach achieves significant improvements in metrics such as mIOU, mDICE, and mRecall. It also exhibits superior boundary retention in complex scenes. Visual analysis further confirms the model's advantages in fine-grained regions. Future research will focus on optimizing computational efficiency and exploring its potential in other high-precision segmentation tasks.
Adaptive Transformer Attention and Multi-Scale Fusion for Spine 3D Segmentation
Mar 17, 2025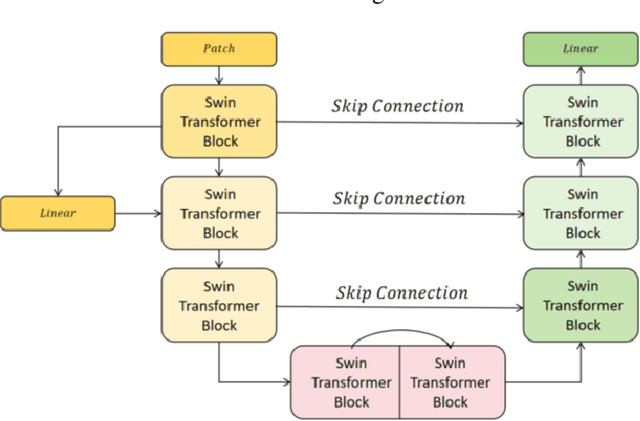
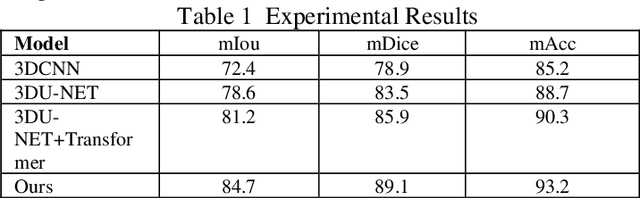
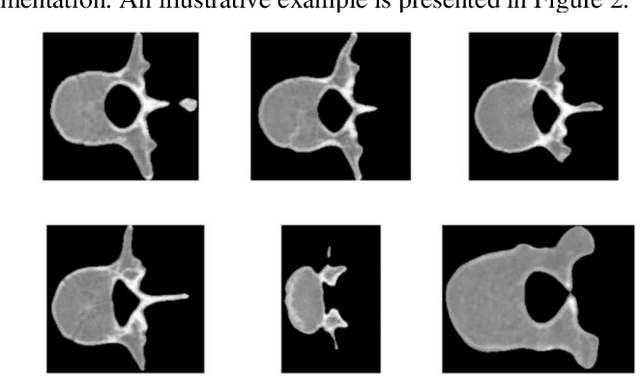
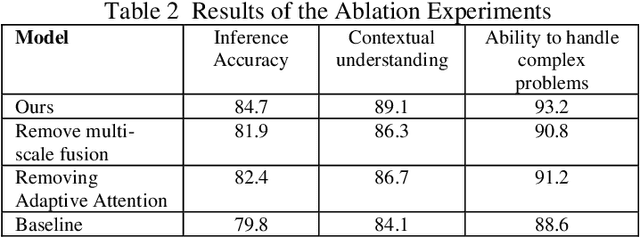
This study proposes a 3D semantic segmentation method for the spine based on the improved SwinUNETR to improve segmentation accuracy and robustness. Aiming at the complex anatomical structure of spinal images, this paper introduces a multi-scale fusion mechanism to enhance the feature extraction capability by using information of different scales, thereby improving the recognition accuracy of the model for the target area. In addition, the introduction of the adaptive attention mechanism enables the model to dynamically adjust the attention to the key area, thereby optimizing the boundary segmentation effect. The experimental results show that compared with 3D CNN, 3D U-Net, and 3D U-Net + Transformer, the model of this study has achieved significant improvements in mIoU, mDice, and mAcc indicators, and has better segmentation performance. The ablation experiment further verifies the effectiveness of the proposed improved method, proving that multi-scale fusion and adaptive attention mechanism have a positive effect on the segmentation task. Through the visualization analysis of the inference results, the model can better restore the real anatomical structure of the spinal image. Future research can further optimize the Transformer structure and expand the data scale to improve the generalization ability of the model. This study provides an efficient solution for the task of medical image segmentation, which is of great significance to intelligent medical image analysis.
A Hybrid CNN-Transformer Model for Heart Disease Prediction Using Life History Data
Mar 03, 2025This study proposed a hybrid model of a convolutional neural network (CNN) and a Transformer to predict and diagnose heart disease. Based on CNN's strength in detecting local features and the Transformer's high capacity in sensing global relations, the model is able to successfully detect risk factors of heart disease from high-dimensional life history data. Experimental results show that the proposed model outperforms traditional benchmark models like support vector machine (SVM), convolutional neural network (CNN), and long short-term memory network (LSTM) on several measures like accuracy, precision, and recall. This demonstrates its strong ability to deal with multi-dimensional and unstructured data. In order to verify the effectiveness of the model, experiments removing certain parts were carried out, and the results of the experiments showed that it is important to use both CNN and Transformer modules in enhancing the model. This paper also discusses the incorporation of additional features and approaches in future studies to enhance the model's performance and enable it to operate effectively in diverse conditions. This study presents novel insights and methods for predicting heart disease using machine learning, with numerous potential applications especially in personalized medicine and health management.
Multi-Scale Transformer Architecture for Accurate Medical Image Classification
Feb 10, 2025



This study introduces an AI-driven skin lesion classification algorithm built on an enhanced Transformer architecture, addressing the challenges of accuracy and robustness in medical image analysis. By integrating a multi-scale feature fusion mechanism and refining the self-attention process, the model effectively extracts both global and local features, enhancing its ability to detect lesions with ambiguous boundaries and intricate structures. Performance evaluation on the ISIC 2017 dataset demonstrates that the improved Transformer surpasses established AI models, including ResNet50, VGG19, ResNext, and Vision Transformer, across key metrics such as accuracy, AUC, F1-Score, and Precision. Grad-CAM visualizations further highlight the interpretability of the model, showcasing strong alignment between the algorithm's focus areas and actual lesion sites. This research underscores the transformative potential of advanced AI models in medical imaging, paving the way for more accurate and reliable diagnostic tools. Future work will explore the scalability of this approach to broader medical imaging tasks and investigate the integration of multimodal data to enhance AI-driven diagnostic frameworks for intelligent healthcare.
A Structured Reasoning Framework for Unbalanced Data Classification Using Probabilistic Models
Feb 05, 2025

This paper studies a Markov network model for unbalanced data, aiming to solve the problems of classification bias and insufficient minority class recognition ability of traditional machine learning models in environments with uneven class distribution. By constructing joint probability distribution and conditional dependency, the model can achieve global modeling and reasoning optimization of sample categories. The study introduced marginal probability estimation and weighted loss optimization strategies, combined with regularization constraints and structured reasoning methods, effectively improving the generalization ability and robustness of the model. In the experimental stage, a real credit card fraud detection dataset was selected and compared with models such as logistic regression, support vector machine, random forest and XGBoost. The experimental results show that the Markov network performs well in indicators such as weighted accuracy, F1 score, and AUC-ROC, significantly outperforming traditional classification models, demonstrating its strong decision-making ability and applicability in unbalanced data scenarios. Future research can focus on efficient model training, structural optimization, and deep learning integration in large-scale unbalanced data environments and promote its wide application in practical applications such as financial risk control, medical diagnosis, and intelligent monitoring.
Dynamic Adaptation of LoRA Fine-Tuning for Efficient and Task-Specific Optimization of Large Language Models
Jan 24, 2025



This paper presents a novel methodology of fine-tuning for large language models-dynamic LoRA. Building from the standard Low-Rank Adaptation framework, this methodology further adds dynamic adaptation mechanisms to improve efficiency and performance. The key contribution of dynamic LoRA lies within its adaptive weight allocation mechanism coupled with an input feature-based adaptive strategy. These enhancements allow for a more precise fine-tuning process that is more tailored to specific tasks. Traditional LoRA methods use static adapter settings, not considering the different importance of model layers. In contrast, dynamic LoRA introduces a mechanism that dynamically evaluates the layer's importance during fine-tuning. This evaluation enables the reallocation of adapter parameters to fit the unique demands of each individual task, which leads to better optimization results. Another gain in flexibility arises from the consideration of the input feature distribution, which helps the model generalize better when faced with complicated and diverse datasets. The joint approach boosts not only the performance over each single task but also the generalization ability of the model. The efficiency of the dynamic LoRA was validated in experiments on benchmark datasets, such as GLUE, with surprising results. More specifically, this method achieved 88.1% accuracy with an F1-score of 87.3%. Noticeably, these improvements were made at a slight increase in computational costs: only 0.1% more resources than standard LoRA. This balance between performance and efficiency positions dynamic LoRA as a practical, scalable solution for fine-tuning LLMs, especially in resource-constrained scenarios. To take it a step further, its adaptability makes it a promising foundation for much more advanced applications, including multimodal tasks.
Deep Learning in Image Classification: Evaluating VGG19's Performance on Complex Visual Data
Dec 29, 2024



This study aims to explore the automatic classification method of pneumonia X-ray images based on VGG19 deep convolutional neural network, and evaluate its application effect in pneumonia diagnosis by comparing with classic models such as SVM, XGBoost, MLP, and ResNet50. The experimental results show that VGG19 performs well in multiple indicators such as accuracy (92%), AUC (0.95), F1 score (0.90) and recall rate (0.87), which is better than other comparison models, especially in image feature extraction and classification accuracy. Although ResNet50 performs well in some indicators, it is slightly inferior to VGG19 in recall rate and F1 score. Traditional machine learning models SVM and XGBoost are obviously limited in image classification tasks, especially in complex medical image analysis tasks, and their performance is relatively mediocre. The research results show that deep learning, especially convolutional neural networks, have significant advantages in medical image classification tasks, especially in pneumonia X-ray image analysis, and can provide efficient and accurate automatic diagnosis support. This research provides strong technical support for the early detection of pneumonia and the development of automated diagnosis systems and also lays the foundation for further promoting the application and development of automated medical image processing technology.
Optimizing Large Language Models with an Enhanced LoRA Fine-Tuning Algorithm for Efficiency and Robustness in NLP Tasks
Dec 25, 2024


This study proposes a large language model optimization method based on the improved LoRA fine-tuning algorithm, aiming to improve the accuracy and computational efficiency of the model in natural language processing tasks. We fine-tune the large language model through a low-rank adaptation strategy, which significantly reduces the consumption of computing resources while maintaining the powerful capabilities of the pre-trained model. The experiment uses the QQP task as the evaluation scenario. The results show that the improved LoRA algorithm shows significant improvements in accuracy, F1 score, and MCC compared with traditional models such as BERT, Roberta, T5, and GPT-4. In particular, in terms of F1 score and MCC, our model shows stronger robustness and discrimination ability, which proves the potential of the improved LoRA algorithm in fine-tuning large-scale pre-trained models. In addition, this paper also discusses the application prospects of the improved LoRA algorithm in other natural language processing tasks, emphasizing its advantages in multi-task learning and scenarios with limited computing resources. Future research can further optimize the LoRA fine-tuning strategy and expand its application in larger-scale pre-trained models to improve the generalization ability and task adaptability of the model.