 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstruction Tuning and CoT Prompting for Contextual Medical QA with LLMs
Jun 13, 2025Large language models (LLMs) have shown great potential in medical question answering (MedQA), yet adapting them to biomedical reasoning remains challenging due to domain-specific complexity and limited supervision. In this work, we study how prompt design and lightweight fine-tuning affect the performance of open-source LLMs on PubMedQA, a benchmark for multiple-choice biomedical questions. We focus on two widely used prompting strategies - standard instruction prompts and Chain-of-Thought (CoT) prompts - and apply QLoRA for parameter-efficient instruction tuning. Across multiple model families and sizes, our experiments show that CoT prompting alone can improve reasoning in zero-shot settings, while instruction tuning significantly boosts accuracy. However, fine-tuning on CoT prompts does not universally enhance performance and may even degrade it for certain larger models. These findings suggest that reasoning-aware prompts are useful, but their benefits are model- and scale-dependent. Our study offers practical insights into combining prompt engineering with efficient finetuning for medical QA applications.
Dynamic Adaptation of LoRA Fine-Tuning for Efficient and Task-Specific Optimization of Large Language Models
Jan 24, 2025



This paper presents a novel methodology of fine-tuning for large language models-dynamic LoRA. Building from the standard Low-Rank Adaptation framework, this methodology further adds dynamic adaptation mechanisms to improve efficiency and performance. The key contribution of dynamic LoRA lies within its adaptive weight allocation mechanism coupled with an input feature-based adaptive strategy. These enhancements allow for a more precise fine-tuning process that is more tailored to specific tasks. Traditional LoRA methods use static adapter settings, not considering the different importance of model layers. In contrast, dynamic LoRA introduces a mechanism that dynamically evaluates the layer's importance during fine-tuning. This evaluation enables the reallocation of adapter parameters to fit the unique demands of each individual task, which leads to better optimization results. Another gain in flexibility arises from the consideration of the input feature distribution, which helps the model generalize better when faced with complicated and diverse datasets. The joint approach boosts not only the performance over each single task but also the generalization ability of the model. The efficiency of the dynamic LoRA was validated in experiments on benchmark datasets, such as GLUE, with surprising results. More specifically, this method achieved 88.1% accuracy with an F1-score of 87.3%. Noticeably, these improvements were made at a slight increase in computational costs: only 0.1% more resources than standard LoRA. This balance between performance and efficiency positions dynamic LoRA as a practical, scalable solution for fine-tuning LLMs, especially in resource-constrained scenarios. To take it a step further, its adaptability makes it a promising foundation for much more advanced applications, including multimodal tasks.
Feature Alignment-Based Knowledge Distillation for Efficient Compression of Large Language Models
Dec 27, 2024


This study proposes a knowledge distillation algorithm based on large language models and feature alignment, aiming to effectively transfer the knowledge of large pre-trained models into lightweight student models, thereby reducing computational costs while maintaining high model performance. Different from the traditional soft label distillation method, this method introduces a multi-layer feature alignment strategy to deeply align the intermediate features and attention mechanisms of the teacher model and the student model, maximally retaining the semantic expression ability and context modeling ability of the teacher model. In terms of method design, a multi-task loss function is constructed, including feature matching loss, attention alignment loss, and output distribution matching loss, to ensure multi-level information transfer through joint optimization. The experiments were comprehensively evaluated on the GLUE data set and various natural language processing tasks. The results show that the proposed model performs very close to the state-of-the-art GPT-4 model in terms of evaluation indicators such as perplexity, BLEU, ROUGE, and CER. At the same time, it far exceeds baseline models such as DeBERTa, XLNet, and GPT-3, showing significant performance improvements and computing efficiency advantages. Research results show that the feature alignment distillation strategy is an effective model compression method that can significantly reduce computational overhead and storage requirements while maintaining model capabilities. Future research can be further expanded in the directions of self-supervised learning, cross-modal feature alignment, and multi-task transfer learning to provide more flexible and efficient solutions for the deployment and optimization of deep learning models.
Optimizing Large Language Models with an Enhanced LoRA Fine-Tuning Algorithm for Efficiency and Robustness in NLP Tasks
Dec 25, 2024


This study proposes a large language model optimization method based on the improved LoRA fine-tuning algorithm, aiming to improve the accuracy and computational efficiency of the model in natural language processing tasks. We fine-tune the large language model through a low-rank adaptation strategy, which significantly reduces the consumption of computing resources while maintaining the powerful capabilities of the pre-trained model. The experiment uses the QQP task as the evaluation scenario. The results show that the improved LoRA algorithm shows significant improvements in accuracy, F1 score, and MCC compared with traditional models such as BERT, Roberta, T5, and GPT-4. In particular, in terms of F1 score and MCC, our model shows stronger robustness and discrimination ability, which proves the potential of the improved LoRA algorithm in fine-tuning large-scale pre-trained models. In addition, this paper also discusses the application prospects of the improved LoRA algorithm in other natural language processing tasks, emphasizing its advantages in multi-task learning and scenarios with limited computing resources. Future research can further optimize the LoRA fine-tuning strategy and expand its application in larger-scale pre-trained models to improve the generalization ability and task adaptability of the model.
Optimizing Multi-Task Learning for Enhanced Performance in Large Language Models
Dec 09, 2024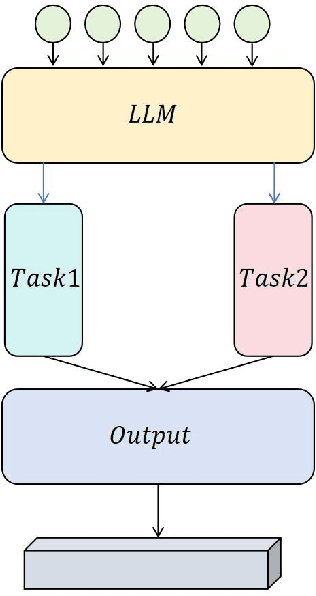
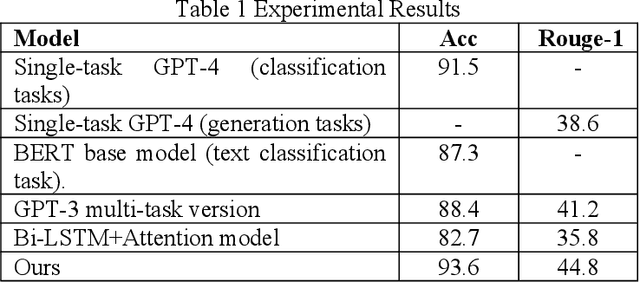

This study aims to explore the performance improvement method of large language models based on GPT-4 under the multi-task learning framework and conducts experiments on two tasks: text classification and automatic summary generation. Through the combined design of shared feature extractors and task-specific modules, we achieve knowledge-sharing and optimization of multiple tasks in the same model. The experiment uses multiple subtasks of the GLUE dataset to compare the performance of the multi-task model with the single-task GPT-4, the multi-task version of GPT-3, the BERT basic model, and the classic Bi-LSTM with Attention model. The results show that the proposed multi-task learning model outperforms other comparison models in terms of text classification accuracy and ROUGE value of summary generation, demonstrating the advantages of multi-task learning in improving model generalization ability and collaborative learning between tasks. The model maintains a stable loss convergence rate during training, showing good learning efficiency and adaptability to the test set. This study verifies the applicability of the multi-task learning framework in large language models, especially in improving the model's ability to balance different tasks. In the future, with the combination of large language models and multimodal data and the application of dynamic task adjustment technology, the framework based on multi-task learning is expected to play a greater role in practical applications across fields and provide new ideas for the development of general artificial intelligence.
A Combined Encoder and Transformer Approach for Coherent and High-Quality Text Generation
Nov 19, 2024


This research introduces a novel text generation model that combines BERT's semantic interpretation strengths with GPT-4's generative capabilities, establishing a high standard in generating coherent, contextually accurate language. Through the combined architecture, the model enhances semantic depth and maintains smooth, human-like text flow, overcoming limitations seen in prior models. Experimental benchmarks reveal that BERT-GPT-4 surpasses traditional models, including GPT-3, T5, BART, Transformer-XL, and CTRL, in key metrics like Perplexity and BLEU, showcasing its superior natural language generation performance. By fully utilizing contextual information, this hybrid model generates text that is not only logically coherent but also aligns closely with human language patterns, providing an advanced solution for text generation tasks. This research highlights the potential of integrating semantic understanding with advanced generative models, contributing new insights for NLP, and setting a foundation for broader applications of large-scale generative architectures in areas such as automated writing, question-answer systems, and adaptive conversational agents.
Advanced RAG Models with Graph Structures: Optimizing Complex Knowledge Reasoning and Text Generation
Nov 06, 2024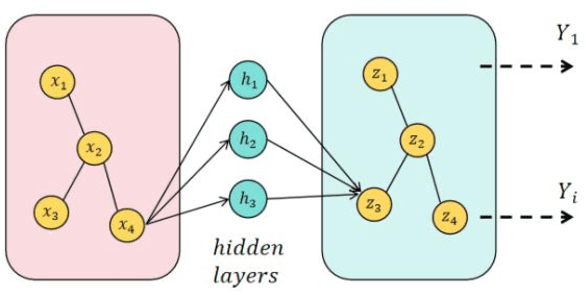
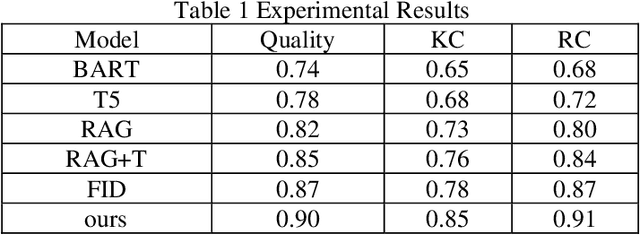
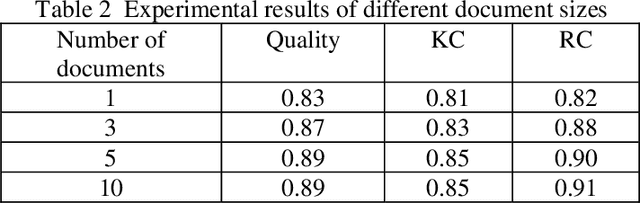
This study aims to optimize the existing retrieval-augmented generation model (RAG) by introducing a graph structure to improve the performance of the model in dealing with complex knowledge reasoning tasks. The traditional RAG model has the problem of insufficient processing efficiency when facing complex graph structure information (such as knowledge graphs, hierarchical relationships, etc.), which affects the quality and consistency of the generated results. This study proposes a scheme to process graph structure data by combining graph neural network (GNN), so that the model can capture the complex relationship between entities, thereby improving the knowledge consistency and reasoning ability of the generated text. The experiment used the Natural Questions (NQ) dataset and compared it with multiple existing generation models. The results show that the graph-based RAG model proposed in this paper is superior to the traditional generation model in terms of quality, knowledge consistency, and reasoning ability, especially when dealing with tasks that require multi-dimensional reasoning. Through the combination of the enhancement of the retrieval module and the graph neural network, the model in this study can better handle complex knowledge background information and has broad potential value in multiple practical application scenarios.
Enhancing Exchange Rate Forecasting with Explainable Deep Learning Models
Oct 25, 2024
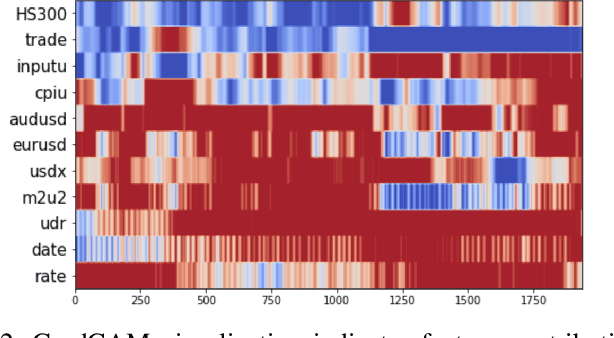

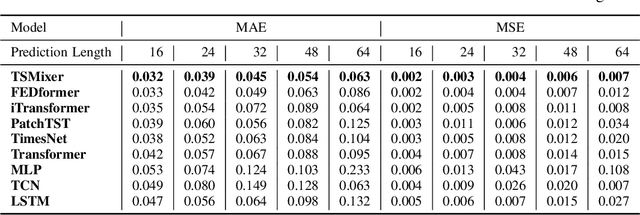
Accurate exchange rate prediction is fundamental to financial stability and international trade, positioning it as a critical focus in economic and financial research. Traditional forecasting models often falter when addressing the inherent complexities and non-linearities of exchange rate data. This study explores the application of advanced deep learning models, including LSTM, CNN, and transformer-based architectures, to enhance the predictive accuracy of the RMB/USD exchange rate. Utilizing 40 features across 6 categories, the analysis identifies TSMixer as the most effective model for this task. A rigorous feature selection process emphasizes the inclusion of key economic indicators, such as China-U.S. trade volumes and exchange rates of other major currencies like the euro-RMB and yen-dollar pairs. The integration of grad-CAM visualization techniques further enhances model interpretability, allowing for clearer identification of the most influential features and bolstering the credibility of the predictions. These findings underscore the pivotal role of fundamental economic data in exchange rate forecasting and highlight the substantial potential of machine learning models to deliver more accurate and reliable predictions, thereby serving as a valuable tool for financial analysis and decision-making.
Automated Genre-Aware Article Scoring and Feedback Using Large Language Models
Oct 18, 2024



This paper focuses on the development of an advanced intelligent article scoring system that not only assesses the overall quality of written work but also offers detailed feature-based scoring tailored to various article genres. By integrating the pre-trained BERT model with the large language model Chat-GPT, the system gains a deep understanding of both the content and structure of the text, enabling it to provide a thorough evaluation along with targeted suggestions for improvement. Experimental results demonstrate that this system outperforms traditional scoring methods across multiple public datasets, particularly in feature-based assessments, offering a more accurate reflection of the quality of different article types. Moreover, the system generates personalized feedback to assist users in enhancing their writing skills, underscoring the potential and practical value of automated scoring technologies in educational contexts.
Contrastive Learning for Knowledge-Based Question Generation in Large Language Models
Sep 21, 2024With the rapid development of artificial intelligence technology, especially the increasingly widespread application of question-and-answer systems, high-quality question generation has become a key component in supporting the development of these systems. This article focuses on knowledge-based question generation technology, which aims to enable computers to simulate the human questioning process based on understanding specific texts or knowledge bases. In light of the issues of hallucination and knowledge gaps present in large-scale language models when applied to knowledge-intensive tasks, this paper proposes an enhanced question generation method that incorporates contrastive learning. This method utilizes multiple models to jointly mine domain knowledge and uses contrastive learning to guide the model in reducing noise and hallucinations in generation. Experimental results show that by designing prompts containing contrasting examples, the model's performance in question generation improves considerably, particularly when contrasting instructions and examples are used simultaneously, leading to the highest quality of generated questions and improved accuracy. These results demonstrate that the method proposed in this study, which combines contrasting context and chain-of-thought prompts, can effectively improve both the quality and the practicality of question generation.