 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Segment Anything with Depth-Aware Fusion and Limited Training Data
Feb 12, 2026Segment Anything Models (SAM) achieve impressive universal segmentation performance but require massive datasets (e.g., 11M images) and rely solely on RGB inputs. Recent efficient variants reduce computation but still depend on large-scale training. We propose a lightweight RGB-D fusion framework that augments EfficientViT-SAM with monocular depth priors. Depth maps are generated with a pretrained estimator and fused mid-level with RGB features through a dedicated depth encoder. Trained on only 11.2k samples (less than 0.1\% of SA-1B), our method achieves higher accuracy than EfficientViT-SAM, showing that depth cues provide strong geometric priors for segmentation.
Instruction Tuning and CoT Prompting for Contextual Medical QA with LLMs
Jun 13, 2025Large language models (LLMs) have shown great potential in medical question answering (MedQA), yet adapting them to biomedical reasoning remains challenging due to domain-specific complexity and limited supervision. In this work, we study how prompt design and lightweight fine-tuning affect the performance of open-source LLMs on PubMedQA, a benchmark for multiple-choice biomedical questions. We focus on two widely used prompting strategies - standard instruction prompts and Chain-of-Thought (CoT) prompts - and apply QLoRA for parameter-efficient instruction tuning. Across multiple model families and sizes, our experiments show that CoT prompting alone can improve reasoning in zero-shot settings, while instruction tuning significantly boosts accuracy. However, fine-tuning on CoT prompts does not universally enhance performance and may even degrade it for certain larger models. These findings suggest that reasoning-aware prompts are useful, but their benefits are model- and scale-dependent. Our study offers practical insights into combining prompt engineering with efficient finetuning for medical QA applications.
Data Augmentation Through Random Style Replacement
Apr 14, 2025In this paper, we introduce a novel data augmentation technique that combines the advantages of style augmentation and random erasing by selectively replacing image subregions with style-transferred patches. Our approach first applies a random style transfer to training images, then randomly substitutes selected areas of these images with patches derived from the style-transferred versions. This method is able to seamlessly accommodate a wide range of existing style transfer algorithms and can be readily integrated into diverse data augmentation pipelines. By incorporating our strategy, the training process becomes more robust and less prone to overfitting. Comparative experiments demonstrate that, relative to previous style augmentation methods, our technique achieves superior performance and faster convergence.
Enhancing Exchange Rate Forecasting with Explainable Deep Learning Models
Oct 25, 2024
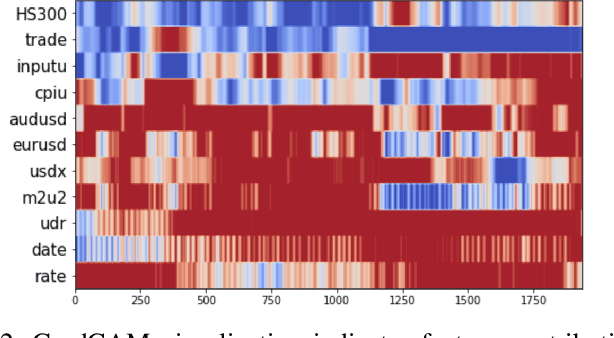

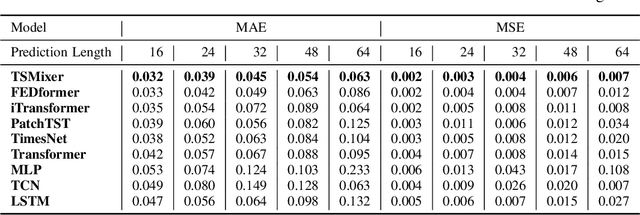
Accurate exchange rate prediction is fundamental to financial stability and international trade, positioning it as a critical focus in economic and financial research. Traditional forecasting models often falter when addressing the inherent complexities and non-linearities of exchange rate data. This study explores the application of advanced deep learning models, including LSTM, CNN, and transformer-based architectures, to enhance the predictive accuracy of the RMB/USD exchange rate. Utilizing 40 features across 6 categories, the analysis identifies TSMixer as the most effective model for this task. A rigorous feature selection process emphasizes the inclusion of key economic indicators, such as China-U.S. trade volumes and exchange rates of other major currencies like the euro-RMB and yen-dollar pairs. The integration of grad-CAM visualization techniques further enhances model interpretability, allowing for clearer identification of the most influential features and bolstering the credibility of the predictions. These findings underscore the pivotal role of fundamental economic data in exchange rate forecasting and highlight the substantial potential of machine learning models to deliver more accurate and reliable predictions, thereby serving as a valuable tool for financial analysis and decision-making.
Harnessing Earnings Reports for Stock Predictions: A QLoRA-Enhanced LLM Approach
Aug 13, 2024


Accurate stock market predictions following earnings reports are crucial for investors. Traditional methods, particularly classical machine learning models, struggle with these predictions because they cannot effectively process and interpret extensive textual data contained in earnings reports and often overlook nuances that influence market movements. This paper introduces an advanced approach by employing Large Language Models (LLMs) instruction fine-tuned with a novel combination of instruction-based techniques and quantized low-rank adaptation (QLoRA) compression. Our methodology integrates 'base factors', such as financial metric growth and earnings transcripts, with 'external factors', including recent market indices performances and analyst grades, to create a rich, supervised dataset. This comprehensive dataset enables our models to achieve superior predictive performance in terms of accuracy, weighted F1, and Matthews correlation coefficient (MCC), especially evident in the comparison with benchmarks such as GPT-4. We specifically highlight the efficacy of the llama-3-8b-Instruct-4bit model, which showcases significant improvements over baseline models. The paper also discusses the potential of expanding the output capabilities to include a 'Hold' option and extending the prediction horizon, aiming to accommodate various investment styles and time frames. This study not only demonstrates the power of integrating cutting-edge AI with fine-tuned financial data but also paves the way for future research in enhancing AI-driven financial analysis tools.
Evaluating Modern Approaches in 3D Scene Reconstruction: NeRF vs Gaussian-Based Methods
Aug 08, 2024Exploring the capabilities of Neural Radiance Fields (NeRF) and Gaussian-based methods in the context of 3D scene reconstruction, this study contrasts these modern approaches with traditional Simultaneous Localization and Mapping (SLAM) systems. Utilizing datasets such as Replica and ScanNet, we assess performance based on tracking accuracy, mapping fidelity, and view synthesis. Findings reveal that NeRF excels in view synthesis, offering unique capabilities in generating new perspectives from existing data, albeit at slower processing speeds. Conversely, Gaussian-based methods provide rapid processing and significant expressiveness but lack comprehensive scene completion. Enhanced by global optimization and loop closure techniques, newer methods like NICE-SLAM and SplaTAM not only surpass older frameworks such as ORB-SLAM2 in terms of robustness but also demonstrate superior performance in dynamic and complex environments. This comparative analysis bridges theoretical research with practical implications, shedding light on future developments in robust 3D scene reconstruction across various real-world applications.
Time Series Modeling for Heart Rate Prediction: From ARIMA to Transformers
Jun 18, 2024Cardiovascular disease (CVD) is a leading cause of death globally, necessitating precise forecasting models for monitoring vital signs like heart rate, blood pressure, and ECG. Traditional models, such as ARIMA and Prophet, are limited by their need for manual parameter tuning and challenges in handling noisy, sparse, and highly variable medical data. This study investigates advanced deep learning models, including LSTM, and transformer-based architectures, for predicting heart rate time series from the MIT-BIH Database. Results demonstrate that deep learning models, particularly PatchTST, significantly outperform traditional models across multiple metrics, capturing complex patterns and dependencies more effectively. This research underscores the potential of deep learning to enhance patient monitoring and CVD management, suggesting substantial clinical benefits. Future work should extend these findings to larger, more diverse datasets and real-world clinical applications to further validate and optimize model performance.
Enhance Image-to-Image Generation with LLaVA Prompt and Negative Prompt
Jun 04, 2024This paper presents a novel approach to enhance image-to-image generation by leveraging the multimodal capabilities of the Large Language and Vision Assistant (LLaVA). We propose a framework where LLaVA analyzes input images and generates textual descriptions, hereinafter LLaVA-generated prompts. These prompts, along with the original image, are fed into the image-to-image generation pipeline. This enriched representation guides the generation process towards outputs that exhibit a stronger resemblance to the input image. Extensive experiments demonstrate the effectiveness of LLaVA-generated prompts in promoting image similarity. We observe a significant improvement in the visual coherence between the generated and input images compared to traditional methods. Future work will explore fine-tuning LLaVA prompts for increased control over the creative process. By providing more specific details within the prompts, we aim to achieve a delicate balance between faithfulness to the original image and artistic expression in the generated outputs.
A Comparative Study on Enhancing Prediction in Social Network Advertisement through Data Augmentation
Apr 28, 2024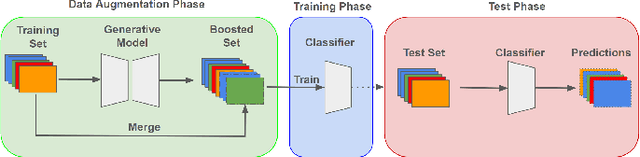
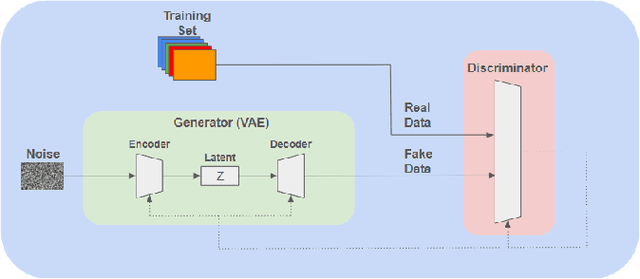
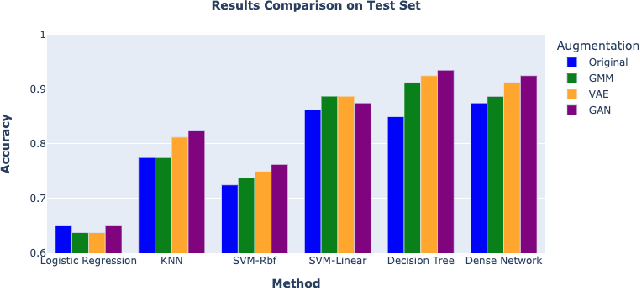
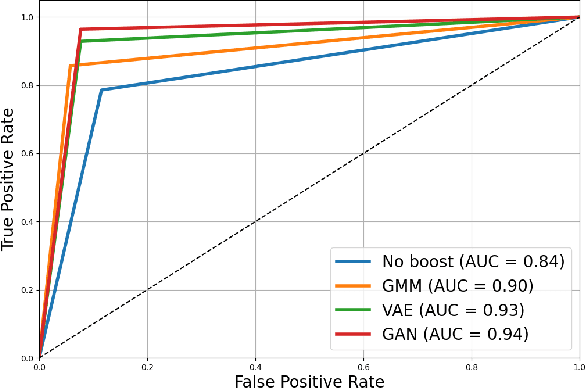
In the ever-evolving landscape of social network advertising, the volume and accuracy of data play a critical role in the performance of predictive models. However, the development of robust predictive algorithms is often hampered by the limited size and potential bias present in real-world datasets. This study presents and explores a generative augmentation framework of social network advertising data. Our framework explores three generative models for data augmentation - Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and Gaussian Mixture Models (GMMs) - to enrich data availability and diversity in the context of social network advertising analytics effectiveness. By performing synthetic extensions of the feature space, we find that through data augmentation, the performance of various classifiers has been quantitatively improved. Furthermore, we compare the relative performance gains brought by each data augmentation technique, providing insights for practitioners to select appropriate techniques to enhance model performance. This paper contributes to the literature by showing that synthetic data augmentation alleviates the limitations imposed by small or imbalanced datasets in the field of social network advertising. At the same time, this article also provides a comparative perspective on the practicality of different data augmentation methods, thereby guiding practitioners to choose appropriate techniques to enhance model performance.
Regional Style and Color Transfer
Apr 24, 2024This paper presents a novel contribution to the field of regional style transfer. Existing methods often suffer from the drawback of applying style homogeneously across the entire image, leading to stylistic inconsistencies or foreground object twisted when applied to image with foreground elements such as person figures. To address this limitation, we propose a new approach that leverages a segmentation network to precisely isolate foreground objects within the input image. Subsequently, style transfer is applied exclusively to the background region. The isolated foreground objects are then carefully reintegrated into the style-transferred background. To enhance the visual coherence between foreground and background, a color transfer step is employed on the foreground elements prior to their rein-corporation. Finally, we utilize feathering techniques to achieve a seamless amalgamation of foreground and background, resulting in a visually unified and aesthetically pleasing final composition. Extensive evaluations demonstrate that our proposed approach yields significantly more natural stylistic transformations compared to conventional methods.