 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Mind to Machine: The Rise of Manus AI as a Fully Autonomous Digital Agent
May 04, 2025Manus AI is a general-purpose AI agent introduced in early 2025, marking a significant advancement in autonomous artificial intelligence. Developed by the Chinese startup Monica.im, Manus is designed to bridge the gap between "mind" and "hand" - combining the reasoning and planning capabilities of large language models with the ability to execute complex, end-to-end tasks that produce tangible outcomes. This paper presents a comprehensive overview of Manus AI, exploring its core technical architecture, diverse applications across sectors such as healthcare, finance, manufacturing, robotics, and gaming, as well as its key strengths, current limitations, and future potential. Positioned as a preview of what lies ahead, Manus AI represents a shift toward intelligent agents that can translate high-level intentions into real-world actions, heralding a new era of human-AI collaboration.
Data Augmentation Through Random Style Replacement
Apr 14, 2025In this paper, we introduce a novel data augmentation technique that combines the advantages of style augmentation and random erasing by selectively replacing image subregions with style-transferred patches. Our approach first applies a random style transfer to training images, then randomly substitutes selected areas of these images with patches derived from the style-transferred versions. This method is able to seamlessly accommodate a wide range of existing style transfer algorithms and can be readily integrated into diverse data augmentation pipelines. By incorporating our strategy, the training process becomes more robust and less prone to overfitting. Comparative experiments demonstrate that, relative to previous style augmentation methods, our technique achieves superior performance and faster convergence.
Enhance Image-to-Image Generation with LLaVA Prompt and Negative Prompt
Jun 04, 2024This paper presents a novel approach to enhance image-to-image generation by leveraging the multimodal capabilities of the Large Language and Vision Assistant (LLaVA). We propose a framework where LLaVA analyzes input images and generates textual descriptions, hereinafter LLaVA-generated prompts. These prompts, along with the original image, are fed into the image-to-image generation pipeline. This enriched representation guides the generation process towards outputs that exhibit a stronger resemblance to the input image. Extensive experiments demonstrate the effectiveness of LLaVA-generated prompts in promoting image similarity. We observe a significant improvement in the visual coherence between the generated and input images compared to traditional methods. Future work will explore fine-tuning LLaVA prompts for increased control over the creative process. By providing more specific details within the prompts, we aim to achieve a delicate balance between faithfulness to the original image and artistic expression in the generated outputs.
ComposerX: Multi-Agent Symbolic Music Composition with LLMs
Apr 30, 2024

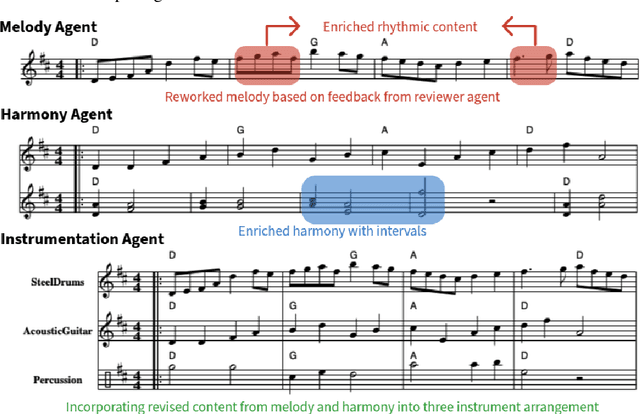
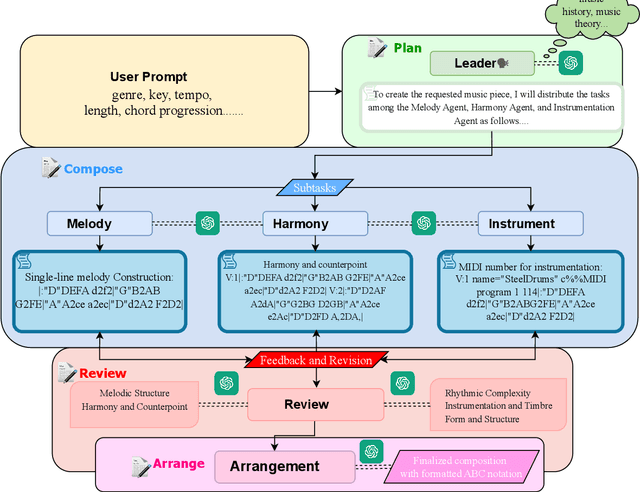
Music composition represents the creative side of humanity, and itself is a complex task that requires abilities to understand and generate information with long dependency and harmony constraints. While demonstrating impressive capabilities in STEM subjects, current LLMs easily fail in this task, generating ill-written music even when equipped with modern techniques like In-Context-Learning and Chain-of-Thoughts. To further explore and enhance LLMs' potential in music composition by leveraging their reasoning ability and the large knowledge base in music history and theory, we propose ComposerX, an agent-based symbolic music generation framework. We find that applying a multi-agent approach significantly improves the music composition quality of GPT-4. The results demonstrate that ComposerX is capable of producing coherent polyphonic music compositions with captivating melodies, while adhering to user instructions.
A Comparative Study on Enhancing Prediction in Social Network Advertisement through Data Augmentation
Apr 28, 2024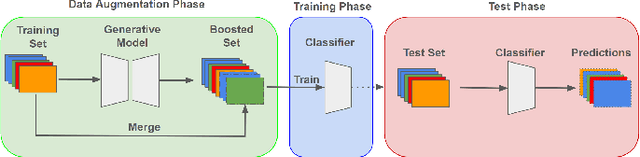
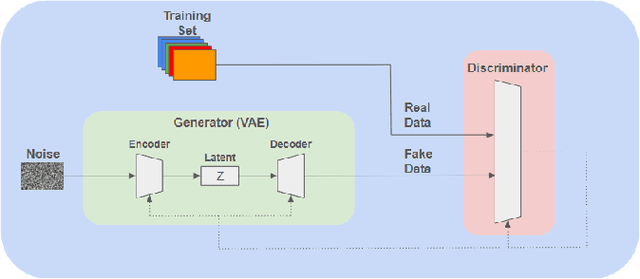
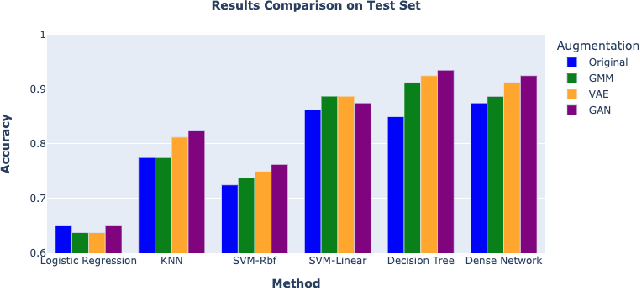
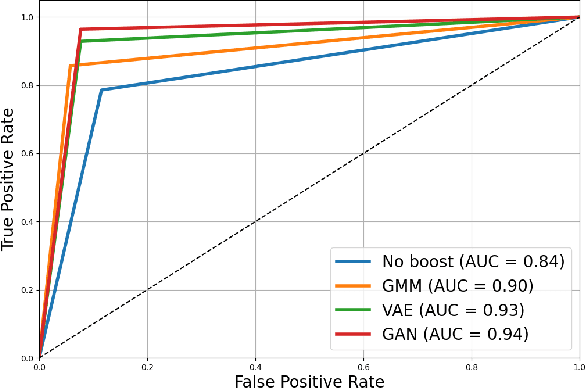
In the ever-evolving landscape of social network advertising, the volume and accuracy of data play a critical role in the performance of predictive models. However, the development of robust predictive algorithms is often hampered by the limited size and potential bias present in real-world datasets. This study presents and explores a generative augmentation framework of social network advertising data. Our framework explores three generative models for data augmentation - Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and Gaussian Mixture Models (GMMs) - to enrich data availability and diversity in the context of social network advertising analytics effectiveness. By performing synthetic extensions of the feature space, we find that through data augmentation, the performance of various classifiers has been quantitatively improved. Furthermore, we compare the relative performance gains brought by each data augmentation technique, providing insights for practitioners to select appropriate techniques to enhance model performance. This paper contributes to the literature by showing that synthetic data augmentation alleviates the limitations imposed by small or imbalanced datasets in the field of social network advertising. At the same time, this article also provides a comparative perspective on the practicality of different data augmentation methods, thereby guiding practitioners to choose appropriate techniques to enhance model performance.
Regional Style and Color Transfer
Apr 24, 2024This paper presents a novel contribution to the field of regional style transfer. Existing methods often suffer from the drawback of applying style homogeneously across the entire image, leading to stylistic inconsistencies or foreground object twisted when applied to image with foreground elements such as person figures. To address this limitation, we propose a new approach that leverages a segmentation network to precisely isolate foreground objects within the input image. Subsequently, style transfer is applied exclusively to the background region. The isolated foreground objects are then carefully reintegrated into the style-transferred background. To enhance the visual coherence between foreground and background, a color transfer step is employed on the foreground elements prior to their rein-corporation. Finally, we utilize feathering techniques to achieve a seamless amalgamation of foreground and background, resulting in a visually unified and aesthetically pleasing final composition. Extensive evaluations demonstrate that our proposed approach yields significantly more natural stylistic transformations compared to conventional methods.
Exploring Diverse Methods in Visual Question Answering
Apr 21, 2024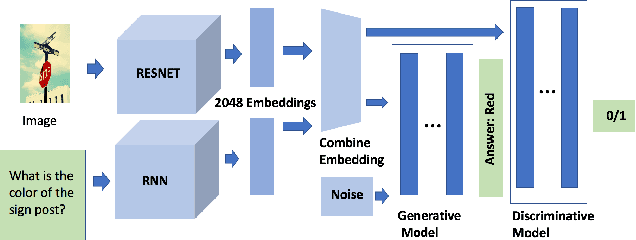
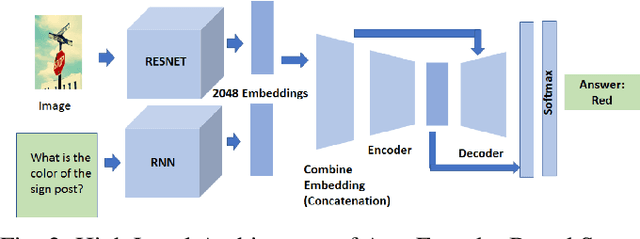
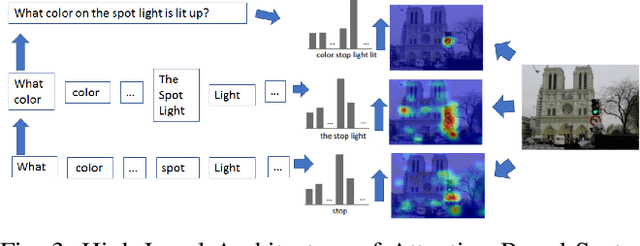

This study explores innovative methods for improving Visual Question Answering (VQA) using Generative Adversarial Networks (GANs), autoencoders, and attention mechanisms. Leveraging a balanced VQA dataset, we investigate three distinct strategies. Firstly, GAN-based approaches aim to generate answer embeddings conditioned on image and question inputs, showing potential but struggling with more complex tasks. Secondly, autoencoder-based techniques focus on learning optimal embeddings for questions and images, achieving comparable results with GAN due to better ability on complex questions. Lastly, attention mechanisms, incorporating Multimodal Compact Bilinear pooling (MCB), address language priors and attention modeling, albeit with a complexity-performance trade-off. This study underscores the challenges and opportunities in VQA and suggests avenues for future research, including alternative GAN formulations and attentional mechanisms.