 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Omni-AVSR: Towards Unified Multimodal Speech Recognition with Large Language Models
Nov 10, 2025Large language models (LLMs) have recently achieved impressive results in speech recognition across multiple modalities, including Auditory Speech Recognition (ASR), Visual Speech Recognition (VSR), and Audio-Visual Speech Recognition (AVSR). Despite this progress, current LLM-based approaches typically address each task independently, training separate models that raise computational and deployment resource use while missing potential cross-task synergies. They also rely on fixed-rate token compression, which restricts flexibility in balancing accuracy with efficiency. These limitations highlight the need for a unified framework that can support ASR, VSR, and AVSR while enabling elastic inference. To this end, we present Omni-AVSR, a unified audio-visual LLM that combines efficient multi-granularity training with parameter-efficient adaptation. Specifically, we adapt the matryoshka representation learning paradigm to efficiently train across multiple audio and visual granularities, reducing its inherent training resource use. Furthermore, we explore three LoRA-based strategies for adapting the backbone LLM, balancing shared and task-specific specialization. Experiments on LRS2 and LRS3 show that Omni-AVSR achieves comparable or superior accuracy to state-of-the-art baselines while training a single model at substantially lower training and deployment resource use. The model also remains robust under acoustic noise, and we analyze its scaling behavior as LLM size increases, providing insights into the trade-off between performance and efficiency.
Noise-Robust Sound Event Detection and Counting via Language-Queried Sound Separation
Aug 10, 2025Most sound event detection (SED) systems perform well on clean datasets but degrade significantly in noisy environments. Language-queried audio source separation (LASS) models show promise for robust SED by separating target events; existing methods require elaborate multi-stage training and lack explicit guidance for target events. To address these challenges, we introduce event appearance detection (EAD), a counting-based approach that counts event occurrences at both the clip and frame levels. Based on EAD, we propose a co-training-based multi-task learning framework for EAD and SED to enhance SED's performance in noisy environments. First, SED struggles to learn the same patterns as EAD. Then, a task-based constraint is designed to improve prediction consistency between SED and EAD. This framework provides more reliable clip-level predictions for LASS models and strengthens timestamp detection capability. Experiments on DESED and WildDESED datasets demonstrate better performance compared to existing methods, with advantages becoming more pronounced at higher noise levels.
AudioTurbo: Fast Text-to-Audio Generation with Rectified Diffusion
May 28, 2025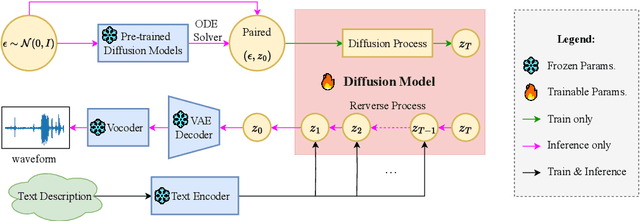
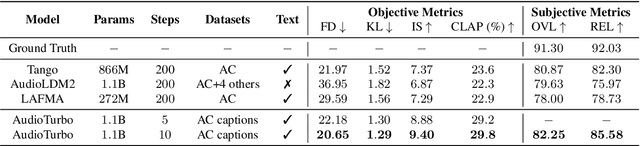
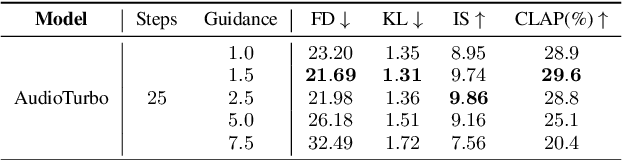
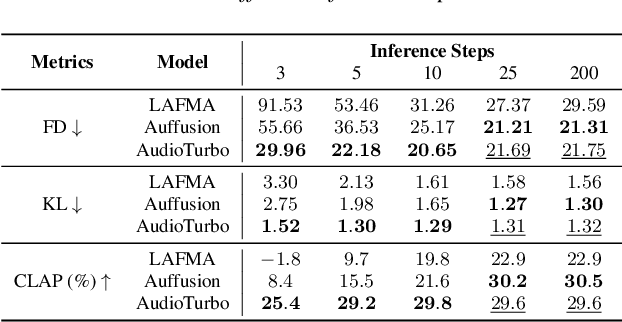
Diffusion models have significantly improved the quality and diversity of audio generation but are hindered by slow inference speed. Rectified flow enhances inference speed by learning straight-line ordinary differential equation (ODE) paths. However, this approach requires training a flow-matching model from scratch and tends to perform suboptimally, or even poorly, at low step counts. To address the limitations of rectified flow while leveraging the advantages of advanced pre-trained diffusion models, this study integrates pre-trained models with the rectified diffusion method to improve the efficiency of text-to-audio (TTA) generation. Specifically, we propose AudioTurbo, which learns first-order ODE paths from deterministic noise sample pairs generated by a pre-trained TTA model. Experiments on the AudioCaps dataset demonstrate that our model, with only 10 sampling steps, outperforms prior models and reduces inference to 3 steps compared to a flow-matching-based acceleration model.
ProDS: Preference-oriented Data Selection for Instruction Tuning
May 19, 2025Instruction data selection aims to identify a high-quality subset from the training set that matches or exceeds the performance of the full dataset on target tasks. Existing methods focus on the instruction-to-response mapping, but neglect the human preference for diverse responses. In this paper, we propose Preference-oriented Data Selection method (ProDS) that scores training samples based on their alignment with preferences observed in the target set. Our key innovation lies in shifting the data selection criteria from merely estimating features for accurate response generation to explicitly aligning training samples with human preferences in target tasks. Specifically, direct preference optimization (DPO) is employed to estimate human preferences across diverse responses. Besides, a bidirectional preference synthesis strategy is designed to score training samples according to both positive preferences and negative preferences. Extensive experimental results demonstrate our superiority to existing task-agnostic and targeted methods.
Audio-Visual Class-Incremental Learning for Fish Feeding intensity Assessment in Aquaculture
Apr 21, 2025



Fish Feeding Intensity Assessment (FFIA) is crucial in industrial aquaculture management. Recent multi-modal approaches have shown promise in improving FFIA robustness and efficiency. However, these methods face significant challenges when adapting to new fish species or environments due to catastrophic forgetting and the lack of suitable datasets. To address these limitations, we first introduce AV-CIL-FFIA, a new dataset comprising 81,932 labelled audio-visual clips capturing feeding intensities across six different fish species in real aquaculture environments. Then, we pioneer audio-visual class incremental learning (CIL) for FFIA and demonstrate through benchmarking on AV-CIL-FFIA that it significantly outperforms single-modality methods. Existing CIL methods rely heavily on historical data. Exemplar-based approaches store raw samples, creating storage challenges, while exemplar-free methods avoid data storage but struggle to distinguish subtle feeding intensity variations across different fish species. To overcome these limitations, we introduce HAIL-FFIA, a novel audio-visual class-incremental learning framework that bridges this gap with a prototype-based approach that achieves exemplar-free efficiency while preserving essential knowledge through compact feature representations. Specifically, HAIL-FFIA employs hierarchical representation learning with a dual-path knowledge preservation mechanism that separates general intensity knowledge from fish-specific characteristics. Additionally, it features a dynamic modality balancing system that adaptively adjusts the importance of audio versus visual information based on feeding behaviour stages. Experimental results show that HAIL-FFIA is superior to SOTA methods on AV-CIL-FFIA, achieving higher accuracy with lower storage needs while effectively mitigating catastrophic forgetting in incremental fish species learning.
NCL-CIR: Noise-aware Contrastive Learning for Composed Image Retrieval
Apr 06, 2025Composed Image Retrieval (CIR) seeks to find a target image using a multi-modal query, which combines an image with modification text to pinpoint the target. While recent CIR methods have shown promise, they mainly focus on exploring relationships between the query pairs (image and text) through data augmentation or model design. These methods often assume perfect alignment between queries and target images, an idealized scenario rarely encountered in practice. In reality, pairs are often partially or completely mismatched due to issues like inaccurate modification texts, low-quality target images, and annotation errors. Ignoring these mismatches leads to numerous False Positive Pair (FFPs) denoted as noise pairs in the dataset, causing the model to overfit and ultimately reducing its performance. To address this problem, we propose the Noise-aware Contrastive Learning for CIR (NCL-CIR), comprising two key components: the Weight Compensation Block (WCB) and the Noise-pair Filter Block (NFB). The WCB coupled with diverse weight maps can ensure more stable token representations of multi-modal queries and target images. Meanwhile, the NFB, in conjunction with the Gaussian Mixture Model (GMM) predicts noise pairs by evaluating loss distributions, and generates soft labels correspondingly, allowing for the design of the soft-label based Noise Contrastive Estimation (NCE) loss function. Consequently, the overall architecture helps to mitigate the influence of mismatched and partially matched samples, with experimental results demonstrating that NCL-CIR achieves exceptional performance on the benchmark datasets.
Fast data inversion for high-dimensional dynamical systems from noisy measurements
Jan 07, 2025



In this work, we develop a scalable approach for a flexible latent factor model for high-dimensional dynamical systems. Each latent factor process has its own correlation and variance parameters, and the orthogonal factor loading matrix can be either fixed or estimated. We utilize an orthogonal factor loading matrix that avoids computing the inversion of the posterior covariance matrix at each time of the Kalman filter, and derive closed-form expressions in an expectation-maximization algorithm for parameter estimation, which substantially reduces the computational complexity without approximation. Our study is motivated by inversely estimating slow slip events from geodetic data, such as continuous GPS measurements. Extensive simulated studies illustrate higher accuracy and scalability of our approach compared to alternatives. By applying our method to geodetic measurements in the Cascadia region, our estimated slip better agrees with independently measured seismic data of tremor events. The substantial acceleration from our method enables the use of massive noisy data for geological hazard quantification and other applications.
Disentangling Hierarchical Features for Anomalous Sound Detection Under Domain Shift
Jan 03, 2025



Anomalous sound detection (ASD) encounters difficulties with domain shift, where the sounds of machines in target domains differ significantly from those in source domains due to varying operating conditions. Existing methods typically employ domain classifiers to enhance detection performance, but they often overlook the influence of domain-unrelated information. This oversight can hinder the model's ability to clearly distinguish between domains, thereby weakening its capacity to differentiate normal from abnormal sounds. In this paper, we propose a Gradient Reversal-based Hierarchical feature Disentanglement (GRHD) method to address the above challenge. GRHD uses gradient reversal to separate domain-related features from domain-unrelated ones, resulting in more robust feature representations. Additionally, the method employs a hierarchical structure to guide the learning of fine-grained, domain-specific features by leveraging available metadata, such as section IDs and machine sound attributes. Experimental results on the DCASE 2022 Challenge Task 2 dataset demonstrate that the proposed method significantly improves ASD performance under domain shift.
RiTTA: Modeling Event Relations in Text-to-Audio Generation
Dec 20, 2024
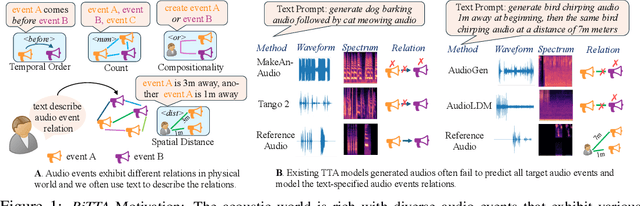
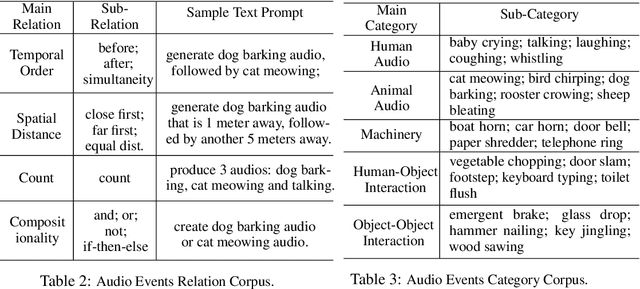
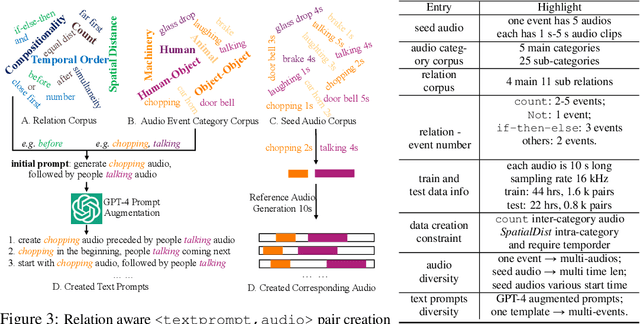
Despite significant advancements in Text-to-Audio (TTA) generation models achieving high-fidelity audio with fine-grained context understanding, they struggle to model the relations between audio events described in the input text. However, previous TTA methods have not systematically explored audio event relation modeling, nor have they proposed frameworks to enhance this capability. In this work, we systematically study audio event relation modeling in TTA generation models. We first establish a benchmark for this task by: 1. proposing a comprehensive relation corpus covering all potential relations in real-world scenarios; 2. introducing a new audio event corpus encompassing commonly heard audios; and 3. proposing new evaluation metrics to assess audio event relation modeling from various perspectives. Furthermore, we propose a finetuning framework to enhance existing TTA models ability to model audio events relation. Code is available at: https://github.com/yuhanghe01/RiTTA