 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Hierarchical Features for Anomalous Sound Detection Under Domain Shift
Jan 03, 2025



Anomalous sound detection (ASD) encounters difficulties with domain shift, where the sounds of machines in target domains differ significantly from those in source domains due to varying operating conditions. Existing methods typically employ domain classifiers to enhance detection performance, but they often overlook the influence of domain-unrelated information. This oversight can hinder the model's ability to clearly distinguish between domains, thereby weakening its capacity to differentiate normal from abnormal sounds. In this paper, we propose a Gradient Reversal-based Hierarchical feature Disentanglement (GRHD) method to address the above challenge. GRHD uses gradient reversal to separate domain-related features from domain-unrelated ones, resulting in more robust feature representations. Additionally, the method employs a hierarchical structure to guide the learning of fine-grained, domain-specific features by leveraging available metadata, such as section IDs and machine sound attributes. Experimental results on the DCASE 2022 Challenge Task 2 dataset demonstrate that the proposed method significantly improves ASD performance under domain shift.
First-Shot Unsupervised Anomalous Sound Detection With Unknown Anomalies Estimated by Metadata-Assisted Audio Generation
Oct 22, 2023



First-shot (FS) unsupervised anomalous sound detection (ASD) is a brand-new task introduced in DCASE 2023 Challenge Task 2, where the anomalous sounds for the target machine types are unseen in training. Existing methods often rely on the availability of normal and abnormal sound data from the target machines. However, due to the lack of anomalous sound data for the target machine types, it becomes challenging when adapting the existing ASD methods to the first-shot task. In this paper, we propose a new framework for the first-shot unsupervised ASD, where metadata-assisted audio generation is used to estimate unknown anomalies, by utilising the available machine information (i.e., metadata and sound data) to fine-tune a text-to-audio generation model for generating the anomalous sounds that contain unique acoustic characteristics accounting for each different machine types. We then use the method of Time-Weighted Frequency domain audio Representation with Gaussian Mixture Model (TWFR-GMM) as the backbone to achieve the first-shot unsupervised ASD. Our proposed FS-TWFR-GMM method achieves competitive performance amongst top systems in DCASE 2023 Challenge Task 2, while requiring only 1% model parameters for detection, as validated in our experiments.
Anomalous Sound Detection Using Self-Attention-Based Frequency Pattern Analysis of Machine Sounds
Sep 06, 2023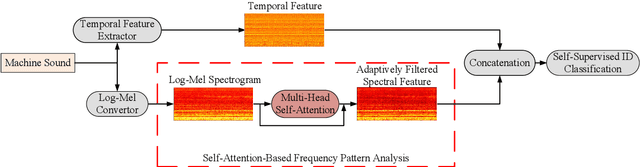



Different machines can exhibit diverse frequency patterns in their emitted sound. This feature has been recently explored in anomaly sound detection and reached state-of-the-art performance. However, existing methods rely on the manual or empirical determination of the frequency filter by observing the effective frequency range in the training data, which may be impractical for general application. This paper proposes an anomalous sound detection method using self-attention-based frequency pattern analysis and spectral-temporal information fusion. Our experiments demonstrate that the self-attention module automatically and adaptively analyses the effective frequencies of a machine sound and enhances that information in the spectral feature representation. With spectral-temporal information fusion, the obtained audio feature eventually improves the anomaly detection performance on the DCASE 2020 Challenge Task 2 dataset.