 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeveloping Foundation Models for Universal Segmentation from 3D Whole-Body Positron Emission Tomography
Mar 12, 2026Positron emission tomography (PET) is a key nuclear medicine imaging modality that visualizes radiotracer distributions to quantify in vivo physiological and metabolic processes, playing an irreplaceable role in disease management. Despite its clinical importance, the development of deep learning models for quantitative PET image analysis remains severely limited, driven by both the inherent segmentation challenge from PET's paucity of anatomical contrast and the high costs of data acquisition and annotation. To bridge this gap, we develop generalist foundational models for universal segmentation from 3D whole-body PET imaging. We first build the largest and most comprehensive PET dataset to date, comprising 11041 3D whole-body PET scans with 59831 segmentation masks for model development. Based on this dataset, we present SegAnyPET, an innovative foundational model with general-purpose applicability to diverse segmentation tasks. Built on a 3D architecture with a prompt engineering strategy for mask generation, SegAnyPET enables universal and scalable organ and lesion segmentation, supports efficient human correction with minimal effort, and enables a clinical human-in-the-loop workflow. Extensive evaluations on multi-center, multi-tracer, multi-disease datasets demonstrate that SegAnyPET achieves strong zero-shot performance across a wide range of segmentation tasks, highlighting its potential to advance the clinical applications of molecular imaging.
IDProxy: Cold-Start CTR Prediction for Ads and Recommendation at Xiaohongshu with Multimodal LLMs
Mar 02, 2026Click-through rate (CTR) models in advertising and recommendation systems rely heavily on item ID embeddings, which struggle in item cold-start settings. We present IDProxy, a solution that leverages multimodal large language models (MLLMs) to generate proxy embeddings from rich content signals, enabling effective CTR prediction for new items without usage data. These proxies are explicitly aligned with the existing ID embedding space and are optimized end-to-end under CTR objectives together with the ranking model, allowing seamless integration into existing large-scale ranking pipelines. Offline experiments and online A/B tests demonstrate the effectiveness of IDProxy, which has been successfully deployed in both Content Feed and Display Ads features of Xiaohongshu's Explore Feed, serving hundreds of millions of users daily.
Uncovering Modality Discrepancy and Generalization Illusion for General-Purpose 3D Medical Segmentation
Feb 07, 2026While emerging 3D medical foundation models are envisioned as versatile tools with offer general-purpose capabilities, their validation remains largely confined to regional and structural imaging, leaving a significant modality discrepancy unexplored. To provide a rigorous and objective assessment, we curate the UMD dataset comprising 490 whole-body PET/CT and 464 whole-body PET/MRI scans ($\sim$675k 2D images, $\sim$12k 3D organ annotations) and conduct a thorough and comprehensive evaluation of representative 3D segmentation foundation models. Through intra-subject controlled comparisons of paired scans, we isolate imaging modality as the primary independent variable to evaluate model robustness in real-world applications. Our evaluation reveals a stark discrepancy between literature-reported benchmarks and real-world efficacy, particularly when transitioning from structural to functional domains. Such systemic failures underscore that current 3D foundation models are far from achieving truly general-purpose status, necessitating a paradigm shift toward multi-modal training and evaluation to bridge the gap between idealized benchmarking and comprehensive clinical utility. This dataset and analysis establish a foundational cornerstone for future research to develop truly modality-agnostic medical foundation models.
Aneumo: A Large-Scale Comprehensive Synthetic Dataset of Aneurysm Hemodynamics
Jan 17, 2025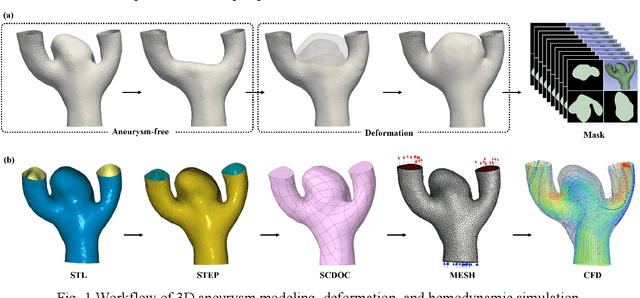
Intracranial aneurysm (IA) is a common cerebrovascular disease that is usually asymptomatic but may cause severe subarachnoid hemorrhage (SAH) if ruptured. Although clinical practice is usually based on individual factors and morphological features of the aneurysm, its pathophysiology and hemodynamic mechanisms remain controversial. To address the limitations of current research, this study constructed a comprehensive hemodynamic dataset of intracranial aneurysms. The dataset is based on 466 real aneurysm models, and 10,000 synthetic models were generated by resection and deformation operations, including 466 aneurysm-free models and 9,534 deformed aneurysm models. The dataset also provides medical image-like segmentation mask files to support insightful analysis. In addition, the dataset contains hemodynamic data measured at eight steady-state flow rates (0.001 to 0.004 kg/s), including critical parameters such as flow velocity, pressure, and wall shear stress, providing a valuable resource for investigating aneurysm pathogenesis and clinical prediction. This dataset will help advance the understanding of the pathologic features and hemodynamic mechanisms of intracranial aneurysms and support in-depth research in related fields. Dataset hosted at https://github.com/Xigui-Li/Aneumo.
Disentangling Hierarchical Features for Anomalous Sound Detection Under Domain Shift
Jan 03, 2025



Anomalous sound detection (ASD) encounters difficulties with domain shift, where the sounds of machines in target domains differ significantly from those in source domains due to varying operating conditions. Existing methods typically employ domain classifiers to enhance detection performance, but they often overlook the influence of domain-unrelated information. This oversight can hinder the model's ability to clearly distinguish between domains, thereby weakening its capacity to differentiate normal from abnormal sounds. In this paper, we propose a Gradient Reversal-based Hierarchical feature Disentanglement (GRHD) method to address the above challenge. GRHD uses gradient reversal to separate domain-related features from domain-unrelated ones, resulting in more robust feature representations. Additionally, the method employs a hierarchical structure to guide the learning of fine-grained, domain-specific features by leveraging available metadata, such as section IDs and machine sound attributes. Experimental results on the DCASE 2022 Challenge Task 2 dataset demonstrate that the proposed method significantly improves ASD performance under domain shift.
Spectral-Temporal Fusion Representation for Person-in-Bed Detection
Dec 27, 2024This study is based on the ICASSP 2025 Signal Processing Grand Challenge's Accelerometer-Based Person-in-Bed Detection Challenge, which aims to determine bed occupancy using accelerometer signals. The task is divided into two tracks: "in bed" and "not in bed" segmented detection, and streaming detection, facing challenges such as individual differences, posture variations, and external disturbances. We propose a spectral-temporal fusion-based feature representation method with mixup data augmentation, and adopt Intersection over Union (IoU) loss to optimize detection accuracy. In the two tracks, our method achieved outstanding results of 100.00% and 95.55% in detection scores, securing first place and third place, respectively.
Attacking Voice Anonymization Systems with Augmented Feature and Speaker Identity Difference
Dec 26, 2024

This study focuses on the First VoicePrivacy Attacker Challenge within the ICASSP 2025 Signal Processing Grand Challenge, which aims to develop speaker verification systems capable of determining whether two anonymized speech signals are from the same speaker. However, differences between feature distributions of original and anonymized speech complicate this task. To address this challenge, we propose an attacker system that combines Data Augmentation enhanced feature representation and Speaker Identity Difference enhanced classifier to improve verification performance, termed DA-SID. Specifically, data augmentation strategies (i.e., data fusion and SpecAugment) are utilized to mitigate feature distribution gaps, while probabilistic linear discriminant analysis (PLDA) is employed to further enhance speaker identity difference. Our system significantly outperforms the baseline, demonstrating exceptional effectiveness and robustness against various voice anonymization systems, ultimately securing a top-5 ranking in the challenge.
Graph-Enhanced Dual-Stream Feature Fusion with Pre-Trained Model for Acoustic Traffic Monitoring
Dec 26, 2024



Microphone array techniques are widely used in sound source localization and smart city acoustic-based traffic monitoring, but these applications face significant challenges due to the scarcity of labeled real-world traffic audio data and the complexity and diversity of application scenarios. The DCASE Challenge's Task 10 focuses on using multi-channel audio signals to count vehicles (cars or commercial vehicles) and identify their directions (left-to-right or vice versa). In this paper, we propose a graph-enhanced dual-stream feature fusion network (GEDF-Net) for acoustic traffic monitoring, which simultaneously considers vehicle type and direction to improve detection. We propose a graph-enhanced dual-stream feature fusion strategy which consists of a vehicle type feature extraction (VTFE) branch, a vehicle direction feature extraction (VDFE) branch, and a frame-level feature fusion module to combine the type and direction feature for enhanced performance. A pre-trained model (PANNs) is used in the VTFE branch to mitigate data scarcity and enhance the type features, followed by a graph attention mechanism to exploit temporal relationships and highlight important audio events within these features. The frame-level fusion of direction and type features enables fine-grained feature representation, resulting in better detection performance. Experiments demonstrate the effectiveness of our proposed method. GEDF-Net is our submission that achieved 1st place in the DCASE 2024 Challenge Task 10.
Independent Feature Enhanced Crossmodal Fusion for Match-Mismatch Classification of Speech Stimulus and EEG Response
Oct 19, 2024



It is crucial for auditory attention decoding to classify matched and mismatched speech stimuli with corresponding EEG responses by exploring their relationship. However, existing methods often adopt two independent networks to encode speech stimulus and EEG response, which neglect the relationship between these signals from the two modalities. In this paper, we propose an independent feature enhanced crossmodal fusion model (IFE-CF) for match-mismatch classification, which leverages the fusion feature of the speech stimulus and the EEG response to achieve auditory EEG decoding. Specifically, our IFE-CF contains a crossmodal encoder to encode the speech stimulus and the EEG response with a two-branch structure connected via crossmodal attention mechanism in the encoding process, a multi-channel fusion module to fuse features of two modalities by aggregating the interaction feature obtained from the crossmodal encoder and the independent feature obtained from the speech stimulus and EEG response, and a predictor to give the matching result. In addition, the causal mask is introduced to consider the time delay of the speech-EEG pair in the crossmodal encoder, which further enhances the feature representation for match-mismatch classification. Experiments demonstrate our method's effectiveness with better classification accuracy, as compared with the baseline of the Auditory EEG Decoding Challenge 2023.
A Reference-free Metric for Language-Queried Audio Source Separation using Contrastive Language-Audio Pretraining
Jul 06, 2024



Language-queried audio source separation (LASS) aims to separate an audio source guided by a text query, with the signal-to-distortion ratio (SDR)-based metrics being commonly used to objectively measure the quality of the separated audio. However, the SDR-based metrics require a reference signal, which is often difficult to obtain in real-world scenarios. In addition, with the SDR-based metrics, the content information of the text query is not considered effectively in LASS. This paper introduces a reference-free evaluation metric using a contrastive language-audio pretraining (CLAP) module, termed CLAPScore, which measures the semantic similarity between the separated audio and the text query. Unlike SDR, the proposed CLAPScore metric evaluates the quality of the separated audio based on the content information of the text query, without needing a reference signal. Experimental results show that the CLAPScore metric provides an effective evaluation of the semantic relevance of the separated audio to the text query, as compared to the SDR metric, offering an alternative for the performance evaluation of LASS systems.