 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNautilus: An Auto-Scheduling Tensor Compiler for Efficient Tiled GPU Kernels
Apr 16, 2026We present Nautilus, a novel tensor compiler that moves toward fully automated math-to-kernel optimization. Nautilus compiles a high-level algebraic specification of tensor operators into efficient tiled GPU kernels. Nautilus's successive lowering design allows high-level optimizations, expression rewrites, and tile optimizations to be jointly applied in a single end-to-end system. Nautilus presents a novel auto-scheduler that discovers sequences of high-level optimizations, while preserving the regular program structure needed by tile optimizers. Nautilus's auto-scheduler captures complex interactions and trade-offs in the high-level optimizations, including aggressive global transformations like advanced reduction fusion. Nautilus is the first end-to-end tensor compiler capable of starting from a math-like description of attention and automatically discovering FlashAttention-3-like kernels, offloading the entire burden of optimization from the programmer to the compiler. Across five transformer-based models and 150 evaluation configurations on NVIDIA GH200 and RTX 5090 GPUs, Nautilus achieves up to 23% higher throughput than state-of-the-art compilers on GH200 and up to 42% on RTX 5090, while matching or exceeding manually written cuDNN kernels on many long-sequence configurations.
RiO-DETR: DETR for Real-time Oriented Object Detection
Mar 10, 2026We present RiO-DETR: DETR for Real-time Oriented Object Detection, the first real-time oriented detection transformer to the best of our knowledge. Adapting DETR to oriented bounding boxes (OBBs) poses three challenges: semantics-dependent orientation, angle periodicity that breaks standard Euclidean refinement, and an enlarged search space that slows convergence. RiO-DETR resolves these issues with task-native designs while preserving real-time efficiency. First, we propose Content-Driven Angle Estimation by decoupling angle from positional queries, together with Rotation-Rectified Orthogonal Attention to capture complementary cues for reliable orientation. Second, Decoupled Periodic Refinement combines bounded coarse-to-fine updates with a Shortest-Path Periodic Loss for stable learning across angular seams. Third, Oriented Dense O2O injects angular diversity into dense supervision to speed up angle convergence at no extra cost. Extensive experiments on DOTA-1.0, DIOR-R, and FAIR-1M-2.0 demonstrate RiO-DETR establishes a new speed--accuracy trade-off for real-time oriented detection. Code will be made publicly available.
WorldTree: Towards 4D Dynamic Worlds from Monocular Video using Tree-Chains
Feb 12, 2026Dynamic reconstruction has achieved remarkable progress, but there remain challenges in monocular input for more practical applications. The prevailing works attempt to construct efficient motion representations, but lack a unified spatiotemporal decomposition framework, suffering from either holistic temporal optimization or coupled hierarchical spatial composition. To this end, we propose WorldTree, a unified framework comprising Temporal Partition Tree (TPT) that enables coarse-to-fine optimization based on the inheritance-based partition tree structure for hierarchical temporal decomposition, and Spatial Ancestral Chains (SAC) that recursively query ancestral hierarchical structure to provide complementary spatial dynamics while specializing motion representations across ancestral nodes. Experimental results on different datasets indicate that our proposed method achieves 8.26% improvement of LPIPS on NVIDIA-LS and 9.09% improvement of mLPIPS on DyCheck compared to the second-best method. Code: https://github.com/iCVTEAM/WorldTree.
LongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
Seeing through Light and Darkness: Sensor-Physics Grounded Deblurring HDR NeRF from Single-Exposure Images and Events
Jan 21, 2026Novel view synthesis from low dynamic range (LDR) blurry images, which are common in the wild, struggles to recover high dynamic range (HDR) and sharp 3D representations in extreme lighting conditions. Although existing methods employ event data to address this issue, they ignore the sensor-physics mismatches between the camera output and physical world radiance, resulting in suboptimal HDR and deblurring results. To cope with this problem, we propose a unified sensor-physics grounded NeRF framework for sharp HDR novel view synthesis from single-exposure blurry LDR images and corresponding events. We employ NeRF to directly represent the actual radiance of the 3D scene in the HDR domain and model raw HDR scene rays hitting the sensor pixels as in the physical world. A pixel-wise RGB mapping field is introduced to align the above rendered pixel values with the sensor-recorded LDR pixel values of the input images. A novel event mapping field is also designed to bridge the physical scene dynamics and actual event sensor output. The two mapping fields are jointly optimized with the NeRF network, leveraging the spatial and temporal dynamic information in events to enhance the sharp HDR 3D representation learning. Experiments on the collected and public datasets demonstrate that our method can achieve state-of-the-art deblurring HDR novel view synthesis results with single-exposure blurry LDR images and corresponding events.
Towards Unified Co-Speech Gesture Generation via Hierarchical Implicit Periodicity Learning
Dec 15, 2025Generating 3D-based body movements from speech shows great potential in extensive downstream applications, while it still suffers challenges in imitating realistic human movements. Predominant research efforts focus on end-to-end generation schemes to generate co-speech gestures, spanning GANs, VQ-VAE, and recent diffusion models. As an ill-posed problem, in this paper, we argue that these prevailing learning schemes fail to model crucial inter- and intra-correlations across different motion units, i.e. head, body, and hands, thus leading to unnatural movements and poor coordination. To delve into these intrinsic correlations, we propose a unified Hierarchical Implicit Periodicity (HIP) learning approach for audio-inspired 3D gesture generation. Different from predominant research, our approach models this multi-modal implicit relationship by two explicit technique insights: i) To disentangle the complicated gesture movements, we first explore the gesture motion phase manifolds with periodic autoencoders to imitate human natures from realistic distributions while incorporating non-period ones from current latent states for instance-level diversities. ii) To model the hierarchical relationship of face motions, body gestures, and hand movements, driving the animation with cascaded guidance during learning. We exhibit our proposed approach on 3D avatars and extensive experiments show our method outperforms the state-of-the-art co-speech gesture generation methods by both quantitative and qualitative evaluations. Code and models will be publicly available.
Free Lunch to Meet the Gap: Intermediate Domain Reconstruction for Cross-Domain Few-Shot Learning
Nov 18, 2025Cross-Domain Few-Shot Learning (CDFSL) endeavors to transfer generalized knowledge from the source domain to target domains using only a minimal amount of training data, which faces a triplet of learning challenges in the meantime, i.e., semantic disjoint, large domain discrepancy, and data scarcity. Different from predominant CDFSL works focused on generalized representations, we make novel attempts to construct Intermediate Domain Proxies (IDP) with source feature embeddings as the codebook and reconstruct the target domain feature with this learned codebook. We then conduct an empirical study to explore the intrinsic attributes from perspectives of visual styles and semantic contents in intermediate domain proxies. Reaping benefits from these attributes of intermediate domains, we develop a fast domain alignment method to use these proxies as learning guidance for target domain feature transformation. With the collaborative learning of intermediate domain reconstruction and target feature transformation, our proposed model is able to surpass the state-of-the-art models by a margin on 8 cross-domain few-shot learning benchmarks.
Re-coding for Uncertainties: Edge-awareness Semantic Concordance for Resilient Event-RGB Segmentation
Nov 11, 2025Semantic segmentation has achieved great success in ideal conditions. However, when facing extreme conditions (e.g., insufficient light, fierce camera motion), most existing methods suffer from significant information loss of RGB, severely damaging segmentation results. Several researches exploit the high-speed and high-dynamic event modality as a complement, but event and RGB are naturally heterogeneous, which leads to feature-level mismatch and inferior optimization of existing multi-modality methods. Different from these researches, we delve into the edge secret of both modalities for resilient fusion and propose a novel Edge-awareness Semantic Concordance framework to unify the multi-modality heterogeneous features with latent edge cues. In this framework, we first propose Edge-awareness Latent Re-coding, which obtains uncertainty indicators while realigning event-RGB features into unified semantic space guided by re-coded distribution, and transfers event-RGB distributions into re-coded features by utilizing a pre-established edge dictionary as clues. We then propose Re-coded Consolidation and Uncertainty Optimization, which utilize re-coded edge features and uncertainty indicators to solve the heterogeneous event-RGB fusion issues under extreme conditions. We establish two synthetic and one real-world event-RGB semantic segmentation datasets for extreme scenario comparisons. Experimental results show that our method outperforms the state-of-the-art by a 2.55% mIoU on our proposed DERS-XS, and possesses superior resilience under spatial occlusion. Our code and datasets are publicly available at https://github.com/iCVTEAM/ESC.
Joint Deblurring and 3D Reconstruction for Macrophotography
Oct 02, 2025
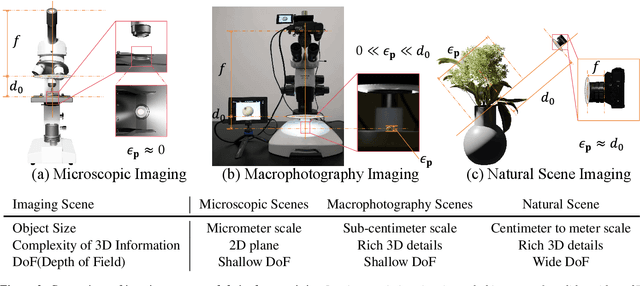
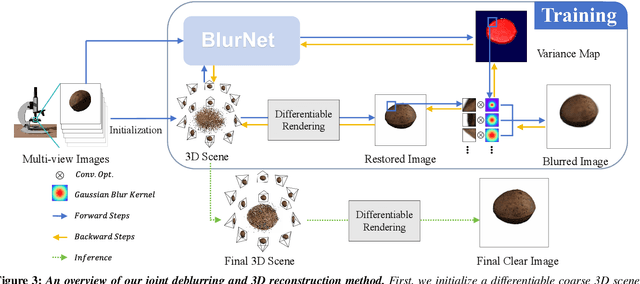

Macro lens has the advantages of high resolution and large magnification, and 3D modeling of small and detailed objects can provide richer information. However, defocus blur in macrophotography is a long-standing problem that heavily hinders the clear imaging of the captured objects and high-quality 3D reconstruction of them. Traditional image deblurring methods require a large number of images and annotations, and there is currently no multi-view 3D reconstruction method for macrophotography. In this work, we propose a joint deblurring and 3D reconstruction method for macrophotography. Starting from multi-view blurry images captured, we jointly optimize the clear 3D model of the object and the defocus blur kernel of each pixel. The entire framework adopts a differentiable rendering method to self-supervise the optimization of the 3D model and the defocus blur kernel. Extensive experiments show that from a small number of multi-view images, our proposed method can not only achieve high-quality image deblurring but also recover high-fidelity 3D appearance.
LLMs-guided adaptive compensator: Bringing Adaptivity to Automatic Control Systems with Large Language Models
Jul 28, 2025With rapid advances in code generation, reasoning, and problem-solving, Large Language Models (LLMs) are increasingly applied in robotics. Most existing work focuses on high-level tasks such as task decomposition. A few studies have explored the use of LLMs in feedback controller design; however, these efforts are restricted to overly simplified systems, fixed-structure gain tuning, and lack real-world validation. To further investigate LLMs in automatic control, this work targets a key subfield: adaptive control. Inspired by the framework of model reference adaptive control (MRAC), we propose an LLM-guided adaptive compensator framework that avoids designing controllers from scratch. Instead, the LLMs are prompted using the discrepancies between an unknown system and a reference system to design a compensator that aligns the response of the unknown system with that of the reference, thereby achieving adaptivity. Experiments evaluate five methods: LLM-guided adaptive compensator, LLM-guided adaptive controller, indirect adaptive control, learning-based adaptive control, and MRAC, on soft and humanoid robots in both simulated and real-world environments. Results show that the LLM-guided adaptive compensator outperforms traditional adaptive controllers and significantly reduces reasoning complexity compared to the LLM-guided adaptive controller. The Lyapunov-based analysis and reasoning-path inspection demonstrate that the LLM-guided adaptive compensator enables a more structured design process by transforming mathematical derivation into a reasoning task, while exhibiting strong generalizability, adaptability, and robustness. This study opens a new direction for applying LLMs in the field of automatic control, offering greater deployability and practicality compared to vision-language models.