 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Inspired Relation Transfer for Few-shot Class-Incremental Learning
Jan 10, 2025Depicting novel classes with language descriptions by observing few-shot samples is inherent in human-learning systems. This lifelong learning capability helps to distinguish new knowledge from old ones through the increase of open-world learning, namely Few-Shot Class-Incremental Learning (FSCIL). Existing works to solve this problem mainly rely on the careful tuning of visual encoders, which shows an evident trade-off between the base knowledge and incremental ones. Motivated by human learning systems, we propose a new Language-inspired Relation Transfer (LRT) paradigm to understand objects by joint visual clues and text depictions, composed of two major steps. We first transfer the pretrained text knowledge to the visual domains by proposing a graph relation transformation module and then fuse the visual and language embedding by a text-vision prototypical fusion module. Second, to mitigate the domain gap caused by visual finetuning, we propose context prompt learning for fast domain alignment and imagined contrastive learning to alleviate the insufficient text data during alignment. With collaborative learning of domain alignments and text-image transfer, our proposed LRT outperforms the state-of-the-art models by over $13\%$ and $7\%$ on the final session of mini-ImageNet and CIFAR-100 FSCIL benchmarks.
Album Storytelling with Iterative Story-aware Captioning and Large Language Models
May 24, 2023
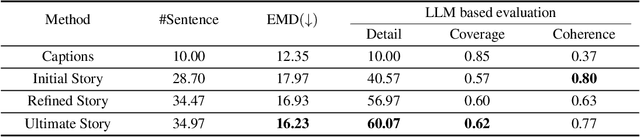
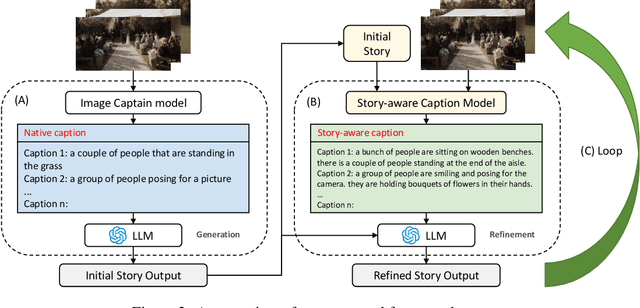

This work studies how to transform an album to vivid and coherent stories, a task we refer to as "album storytelling". While this task can help preserve memories and facilitate experience sharing, it remains an underexplored area in current literature. With recent advances in Large Language Models (LLMs), it is now possible to generate lengthy, coherent text, opening up the opportunity to develop an AI assistant for album storytelling. One natural approach is to use caption models to describe each photo in the album, and then use LLMs to summarize and rewrite the generated captions into an engaging story. However, we find this often results in stories containing hallucinated information that contradicts the images, as each generated caption ("story-agnostic") is not always about the description related to the whole story or miss some necessary information. To address these limitations, we propose a new iterative album storytelling pipeline. Specifically, we start with an initial story and build a story-aware caption model to refine the captions using the whole story as guidance. The polished captions are then fed into the LLMs to generate a new refined story. This process is repeated iteratively until the story contains minimal factual errors while maintaining coherence. To evaluate our proposed pipeline, we introduce a new dataset of image collections from vlogs and a set of systematic evaluation metrics. Our results demonstrate that our method effectively generates more accurate and engaging stories for albums, with enhanced coherence and vividness.
Temporal Contrastive Learning for Spiking Neural Networks
May 23, 2023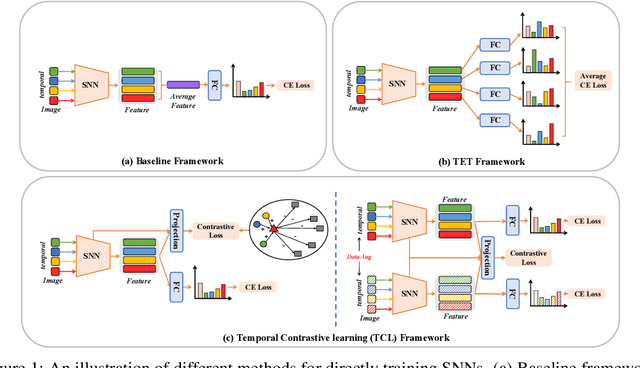
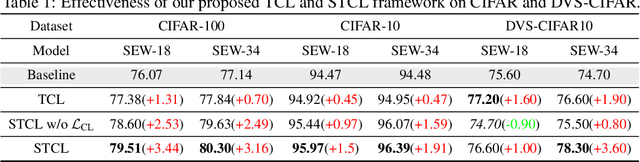
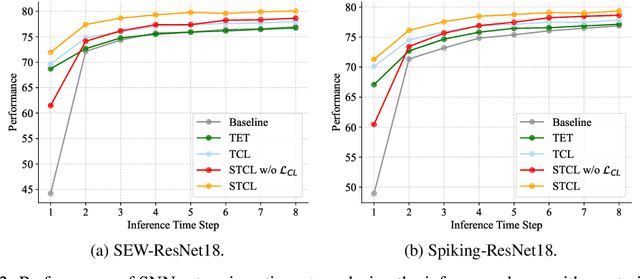

Biologically inspired spiking neural networks (SNNs) have garnered considerable attention due to their low-energy consumption and spatio-temporal information processing capabilities. Most existing SNNs training methods first integrate output information across time steps, then adopt the cross-entropy (CE) loss to supervise the prediction of the average representations. However, in this work, we find the method above is not ideal for the SNNs training as it omits the temporal dynamics of SNNs and degrades the performance quickly with the decrease of inference time steps. One tempting method to model temporal correlations is to apply the same label supervision at each time step and treat them identically. Although it can acquire relatively consistent performance across various time steps, it still faces challenges in obtaining SNNs with high performance. Inspired by these observations, we propose Temporal-domain supervised Contrastive Learning (TCL) framework, a novel method to obtain SNNs with low latency and high performance by incorporating contrastive supervision with temporal domain information. Contrastive learning (CL) prompts the network to discern both consistency and variability in the representation space, enabling it to better learn discriminative and generalizable features. We extend this concept to the temporal domain of SNNs, allowing us to flexibly and fully leverage the correlation between representations at different time steps. Furthermore, we propose a Siamese Temporal-domain supervised Contrastive Learning (STCL) framework to enhance the SNNs via augmentation, temporal and class constraints simultaneously. Extensive experimental results demonstrate that SNNs trained by our TCL and STCL can achieve both high performance and low latency, achieving state-of-the-art performance on a variety of datasets (e.g., CIFAR-10, CIFAR-100, and DVS-CIFAR10).
Learning with Fantasy: Semantic-Aware Virtual Contrastive Constraint for Few-Shot Class-Incremental Learning
Apr 02, 2023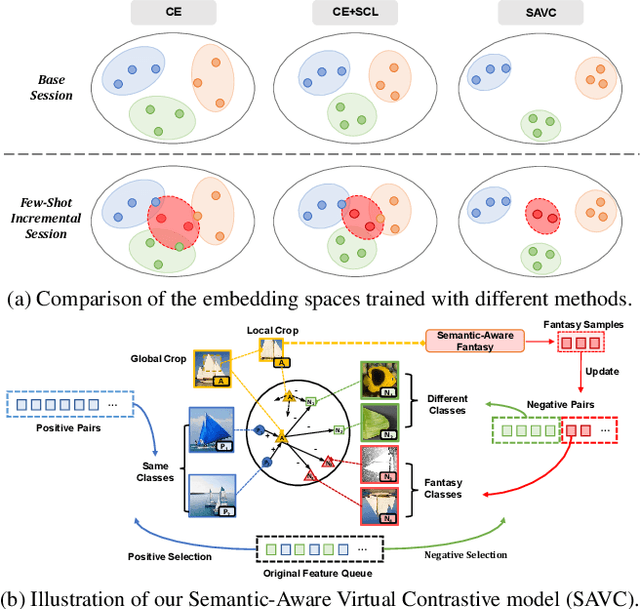
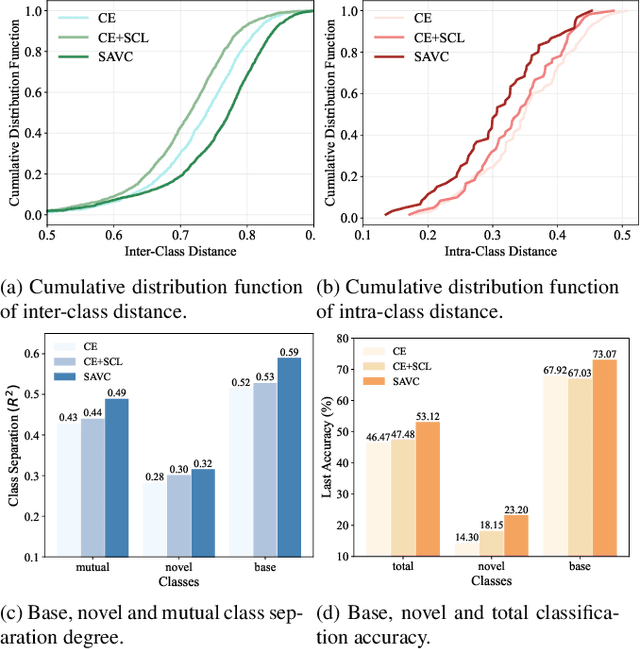
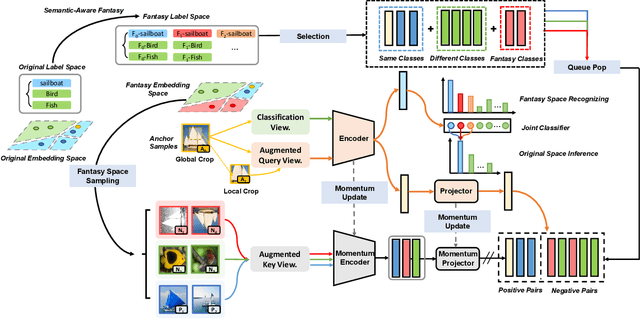
Few-shot class-incremental learning (FSCIL) aims at learning to classify new classes continually from limited samples without forgetting the old classes. The mainstream framework tackling FSCIL is first to adopt the cross-entropy (CE) loss for training at the base session, then freeze the feature extractor to adapt to new classes. However, in this work, we find that the CE loss is not ideal for the base session training as it suffers poor class separation in terms of representations, which further degrades generalization to novel classes. One tempting method to mitigate this problem is to apply an additional naive supervised contrastive learning (SCL) in the base session. Unfortunately, we find that although SCL can create a slightly better representation separation among different base classes, it still struggles to separate base classes and new classes. Inspired by the observations made, we propose Semantic-Aware Virtual Contrastive model (SAVC), a novel method that facilitates separation between new classes and base classes by introducing virtual classes to SCL. These virtual classes, which are generated via pre-defined transformations, not only act as placeholders for unseen classes in the representation space, but also provide diverse semantic information. By learning to recognize and contrast in the fantasy space fostered by virtual classes, our SAVC significantly boosts base class separation and novel class generalization, achieving new state-of-the-art performance on the three widely-used FSCIL benchmark datasets. Code is available at: https://github.com/zysong0113/SAVC.