 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUPME: An Unsupervised Peer Review Framework for Multimodal Large Language Model Evaluation
Mar 19, 2025Multimodal Large Language Models (MLLMs) have emerged to tackle the challenges of Visual Question Answering (VQA), sparking a new research focus on conducting objective evaluations of these models. Existing evaluation methods face limitations due to the significant human workload required to design Q&A pairs for visual images, which inherently restricts the scale and scope of evaluations. Although automated MLLM-as-judge approaches attempt to reduce the human workload through automatic evaluations, they often introduce biases. To address these problems, we propose an Unsupervised Peer review MLLM Evaluation framework. It utilizes only image data, allowing models to automatically generate questions and conduct peer review assessments of answers from other models, effectively alleviating the reliance on human workload. Additionally, we introduce the vision-language scoring system to mitigate the bias issues, which focuses on three aspects: (i) response correctness; (ii) visual understanding and reasoning; and (iii) image-text correlation. Experimental results demonstrate that UPME achieves a Pearson correlation of 0.944 with human evaluations on the MMstar dataset and 0.814 on the ScienceQA dataset, indicating that our framework closely aligns with human-designed benchmarks and inherent human preferences.
WISE: A World Knowledge-Informed Semantic Evaluation for Text-to-Image Generation
Mar 10, 2025Text-to-Image (T2I) models are capable of generating high-quality artistic creations and visual content. However, existing research and evaluation standards predominantly focus on image realism and shallow text-image alignment, lacking a comprehensive assessment of complex semantic understanding and world knowledge integration in text to image generation. To address this challenge, we propose $\textbf{WISE}$, the first benchmark specifically designed for $\textbf{W}$orld Knowledge-$\textbf{I}$nformed $\textbf{S}$emantic $\textbf{E}$valuation. WISE moves beyond simple word-pixel mapping by challenging models with 1000 meticulously crafted prompts across 25 sub-domains in cultural common sense, spatio-temporal reasoning, and natural science. To overcome the limitations of traditional CLIP metric, we introduce $\textbf{WiScore}$, a novel quantitative metric for assessing knowledge-image alignment. Through comprehensive testing of 20 models (10 dedicated T2I models and 10 unified multimodal models) using 1,000 structured prompts spanning 25 subdomains, our findings reveal significant limitations in their ability to effectively integrate and apply world knowledge during image generation, highlighting critical pathways for enhancing knowledge incorporation and application in next-generation T2I models. Code and data are available at https://github.com/PKU-YuanGroup/WISE.
LLMBind: A Unified Modality-Task Integration Framework
Mar 08, 2024While recent progress in multimodal large language models tackles various modality tasks, they posses limited integration capabilities for complex multi-modality tasks, consequently constraining the development of the field. In this work, we take the initiative to explore and propose the LLMBind, a unified framework for modality task integration, which binds Large Language Models and corresponding pre-trained task models with task-specific tokens. Consequently, LLMBind can interpret inputs and produce outputs in versatile combinations of image, text, video, and audio. Specifically, we introduce a Mixture-of-Experts technique to enable effective learning for different multimodal tasks through collaboration among diverse experts. Furthermore, we create a multi-task dataset comprising 400k instruction data, which unlocks the ability for interactive visual generation and editing tasks. Extensive experiments show the effectiveness of our framework across various tasks, including image, video, audio generation, image segmentation, and image editing. More encouragingly, our framework can be easily extended to other modality tasks, showcasing the promising potential of creating a unified AI agent for modeling universal modalities.
MoE-LLaVA: Mixture of Experts for Large Vision-Language Models
Feb 04, 2024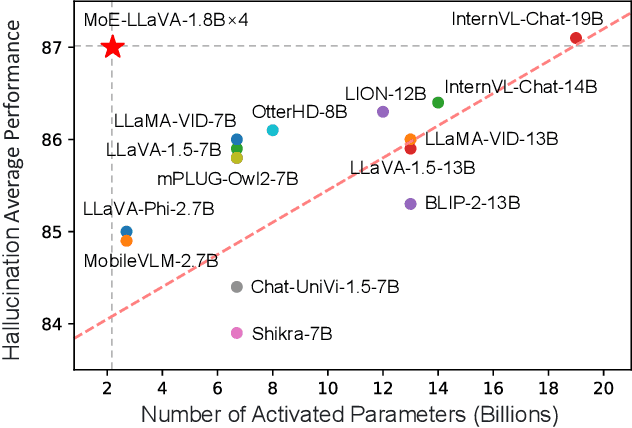
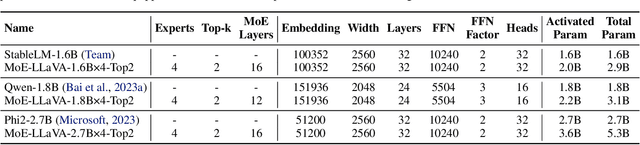
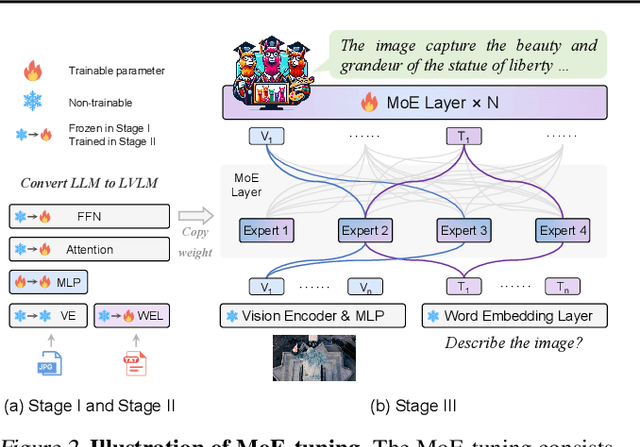

Recent advances demonstrate that scaling Large Vision-Language Models (LVLMs) effectively improves downstream task performances. However, existing scaling methods enable all model parameters to be active for each token in the calculation, which brings massive training and inferring costs. In this work, we propose a simple yet effective training strategy MoE-Tuning for LVLMs. This strategy innovatively addresses the common issue of performance degradation in multi-modal sparsity learning, consequently constructing a sparse model with an outrageous number of parameters but a constant computational cost. Furthermore, we present the MoE-LLaVA, a MoE-based sparse LVLM architecture, which uniquely activates only the top-k experts through routers during deployment, keeping the remaining experts inactive. Extensive experiments show the significant performance of MoE-LLaVA in a variety of visual understanding and object hallucination benchmarks. Remarkably, with only approximately 3B sparsely activated parameters, MoE-LLaVA demonstrates performance comparable to the LLaVA-1.5-7B on various visual understanding datasets and even surpasses the LLaVA-1.5-13B in object hallucination benchmark. Through MoE-LLaVA, we aim to establish a baseline for sparse LVLMs and provide valuable insights for future research in developing more efficient and effective multi-modal learning systems. Code is released at \url{https://github.com/PKU-YuanGroup/MoE-LLaVA}.
Repaint123: Fast and High-quality One Image to 3D Generation with Progressive Controllable 2D Repainting
Dec 27, 2023



Recent one image to 3D generation methods commonly adopt Score Distillation Sampling (SDS). Despite the impressive results, there are multiple deficiencies including multi-view inconsistency, over-saturated and over-smoothed textures, as well as the slow generation speed. To address these deficiencies, we present Repaint123 to alleviate multi-view bias as well as texture degradation and speed up the generation process. The core idea is to combine the powerful image generation capability of the 2D diffusion model and the texture alignment ability of the repainting strategy for generating high-quality multi-view images with consistency. We further propose visibility-aware adaptive repainting strength for overlap regions to enhance the generated image quality in the repainting process. The generated high-quality and multi-view consistent images enable the use of simple Mean Square Error (MSE) loss for fast 3D content generation. We conduct extensive experiments and show that our method has a superior ability to generate high-quality 3D content with multi-view consistency and fine textures in 2 minutes from scratch. Our project page is available at https://pku-yuangroup.github.io/repaint123/.
Video-Bench: A Comprehensive Benchmark and Toolkit for Evaluating Video-based Large Language Models
Nov 28, 2023Video-based large language models (Video-LLMs) have been recently introduced, targeting both fundamental improvements in perception and comprehension, and a diverse range of user inquiries. In pursuit of the ultimate goal of achieving artificial general intelligence, a truly intelligent Video-LLM model should not only see and understand the surroundings, but also possess human-level commonsense, and make well-informed decisions for the users. To guide the development of such a model, the establishment of a robust and comprehensive evaluation system becomes crucial. To this end, this paper proposes \textit{Video-Bench}, a new comprehensive benchmark along with a toolkit specifically designed for evaluating Video-LLMs. The benchmark comprises 10 meticulously crafted tasks, evaluating the capabilities of Video-LLMs across three distinct levels: Video-exclusive Understanding, Prior Knowledge-based Question-Answering, and Comprehension and Decision-making. In addition, we introduce an automatic toolkit tailored to process model outputs for various tasks, facilitating the calculation of metrics and generating convenient final scores. We evaluate 8 representative Video-LLMs using \textit{Video-Bench}. The findings reveal that current Video-LLMs still fall considerably short of achieving human-like comprehension and analysis of real-world videos, offering valuable insights for future research directions. The benchmark and toolkit are available at: \url{https://github.com/PKU-YuanGroup/Video-Bench}.
Video-LLaVA: Learning United Visual Representation by Alignment Before Projection
Nov 21, 2023



The Large Vision-Language Model (LVLM) has enhanced the performance of various downstream tasks in visual-language understanding. Most existing approaches encode images and videos into separate feature spaces, which are then fed as inputs to large language models. However, due to the lack of unified tokenization for images and videos, namely misalignment before projection, it becomes challenging for a Large Language Model (LLM) to learn multi-modal interactions from several poor projection layers. In this work, we unify visual representation into the language feature space to advance the foundational LLM towards a unified LVLM. As a result, we establish a simple but robust LVLM baseline, Video-LLaVA, which learns from a mixed dataset of images and videos, mutually enhancing each other. Video-LLaVA achieves superior performances on a broad range of 9 image benchmarks across 5 image question-answering datasets and 4 image benchmark toolkits. Additionally, our Video-LLaVA also outperforms Video-ChatGPT by 5.8%, 9.9%, 18.6%, and 10.1% on MSRVTT, MSVD, TGIF, and ActivityNet, respectively. Notably, extensive experiments demonstrate that Video-LLaVA mutually benefits images and videos within a unified visual representation, outperforming models designed specifically for images or videos. We aim for this work to provide modest insights into the multi-modal inputs for the LLM.
LanguageBind: Extending Video-Language Pretraining to N-modality by Language-based Semantic Alignment
Oct 14, 2023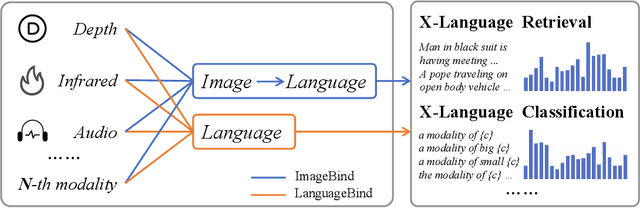
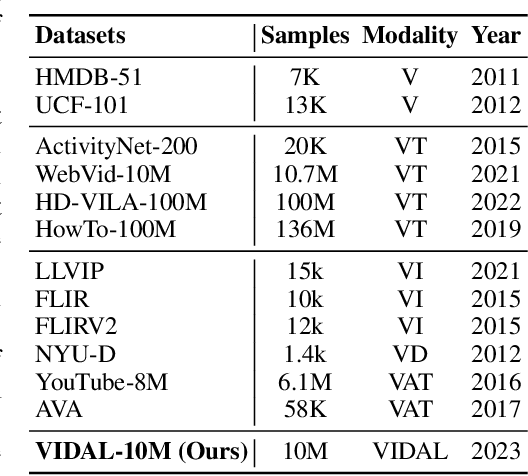
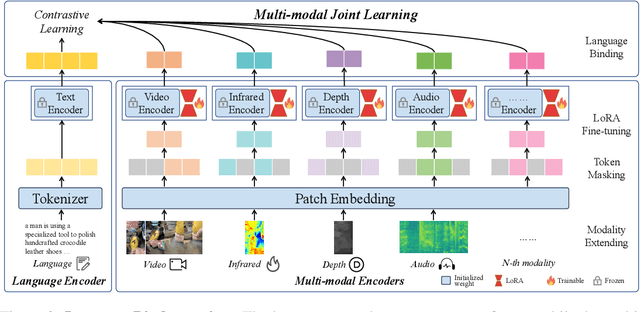
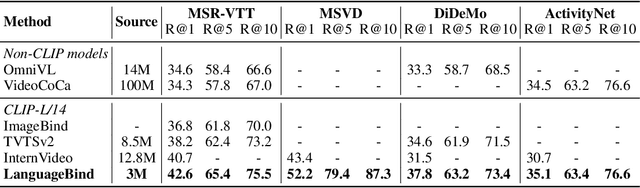
The video-language (VL) pretraining has achieved remarkable improvement in multiple downstream tasks. However, the current VL pretraining framework is hard to extend to multiple modalities (N modalities, N>=3) beyond vision and language. We thus propose LanguageBind, taking the language as the bind across different modalities because the language modality is well-explored and contains rich semantics. Specifically, we freeze the language encoder acquired by VL pretraining, then train encoders for other modalities with contrastive learning. As a result, all modalities are mapped to a shared feature space, implementing multi-modal semantic alignment. While LanguageBind ensures that we can extend VL modalities to N modalities, we also need a high-quality dataset with alignment data pairs centered on language. We thus propose VIDAL-10M with Video, Infrared, Depth, Audio and their corresponding Language, naming as VIDAL-10M. In our VIDAL-10M, all videos are from short video platforms with complete semantics rather than truncated segments from long videos, and all the video, depth, infrared, and audio modalities are aligned to their textual descriptions. After pretraining on VIDAL-10M, we outperform ImageBind by 5.8% R@1 on the MSR-VTT dataset with only 15% of the parameters in the zero-shot video-text retrieval task. Beyond this, our LanguageBind has greatly improved in the zero-shot video, audio, depth, and infrared understanding tasks. For instance, LanguageBind surpassing InterVideo by 1.9% on MSR-VTT, 8.8% on MSVD, 6.3% on DiDeMo, and 4.4% on ActivityNet. On the LLVIP and NYU-D datasets, LanguageBind outperforms ImageBind with 23.8% and 11.1% top-1 accuracy. Code address: https://github.com/PKU-YuanGroup/LanguageBind.
Album Storytelling with Iterative Story-aware Captioning and Large Language Models
May 24, 2023
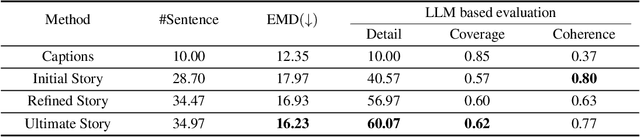
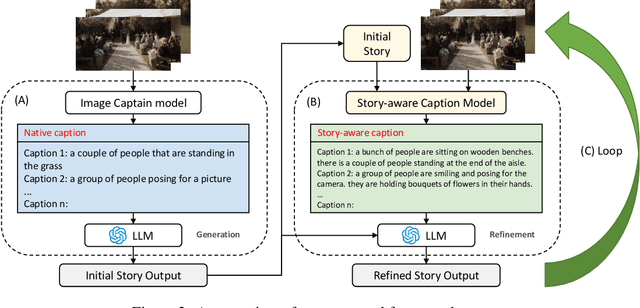

This work studies how to transform an album to vivid and coherent stories, a task we refer to as "album storytelling". While this task can help preserve memories and facilitate experience sharing, it remains an underexplored area in current literature. With recent advances in Large Language Models (LLMs), it is now possible to generate lengthy, coherent text, opening up the opportunity to develop an AI assistant for album storytelling. One natural approach is to use caption models to describe each photo in the album, and then use LLMs to summarize and rewrite the generated captions into an engaging story. However, we find this often results in stories containing hallucinated information that contradicts the images, as each generated caption ("story-agnostic") is not always about the description related to the whole story or miss some necessary information. To address these limitations, we propose a new iterative album storytelling pipeline. Specifically, we start with an initial story and build a story-aware caption model to refine the captions using the whole story as guidance. The polished captions are then fed into the LLMs to generate a new refined story. This process is repeated iteratively until the story contains minimal factual errors while maintaining coherence. To evaluate our proposed pipeline, we introduce a new dataset of image collections from vlogs and a set of systematic evaluation metrics. Our results demonstrate that our method effectively generates more accurate and engaging stories for albums, with enhanced coherence and vividness.
ChatFace: Chat-Guided Real Face Editing via Diffusion Latent Space Manipulation
May 24, 2023Editing real facial images is a crucial task in computer vision with significant demand in various real-world applications. While GAN-based methods have showed potential in manipulating images especially when combined with CLIP, these methods are limited in their ability to reconstruct real images due to challenging GAN inversion capability. Despite the successful image reconstruction achieved by diffusion-based methods, there are still challenges in effectively manipulating fine-gained facial attributes with textual instructions.To address these issues and facilitate convenient manipulation of real facial images, we propose a novel approach that conduct text-driven image editing in the semantic latent space of diffusion model. By aligning the temporal feature of the diffusion model with the semantic condition at generative process, we introduce a stable manipulation strategy, which perform precise zero-shot manipulation effectively. Furthermore, we develop an interactive system named ChatFace, which combines the zero-shot reasoning ability of large language models to perform efficient manipulations in diffusion semantic latent space. This system enables users to perform complex multi-attribute manipulations through dialogue, opening up new possibilities for interactive image editing. Extensive experiments confirmed that our approach outperforms previous methods and enables precise editing of real facial images, making it a promising candidate for real-world applications. Project page: https://dongxuyue.github.io/chatface/